Artificial Intelligence
Fast-track graph ML with GraphStorm: A new way to solve problems on enterprise-scale graphs
We are excited to announce the open-source release of GraphStorm 0.1, a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems.
Until now, it has been notoriously hard to build, train, and deploy graph ML solutions for complex enterprise graphs that easily have billions of nodes, hundreds of billions of edges, and dozens of attributes—just think about a graph capturing Amazon.com products, product attributes, customers, and more. With GraphStorm, we release the tools that Amazon uses internally to bring large-scale graph ML solutions to production. GraphStorm doesn’t require you to be an expert in graph ML and is available under the Apache v2.0 license on GitHub. To learn more about GraphStorm, visit the GitHub repository.
In this post, we provide an introduction to GraphStorm, its architecture, and an example use case of how to use it.
Introducing GraphStorm
Graph algorithms and graph ML are emerging as state-of-the-art solutions for many important business problems like predicting transaction risks, anticipating customer preferences, detecting intrusions, optimizing supply chains, social network analysis, and traffic prediction. For example, Amazon GuardDuty, the native AWS threat detection service, uses a graph with billions of edges to improve the coverage and accuracy of its threat intelligence. This allows GuardDuty to categorize previously unseen domains as highly likely to be malicious or benign based on their association to known malicious domains. By using Graph Neural Networks (GNNs), GuardDuty is able to enhance its capability to alert customers.
However, developing, launching, and operating graph ML solutions takes months and requires graph ML expertise. As a first step, a graph ML scientist has to build a graph ML model for a given use case using a framework like the Deep Graph Library (DGL). Training such models is challenging due to the size and complexity of graphs in enterprise applications, which routinely reach billions of nodes, hundreds of billions of edges, different node and edge types, and hundreds of node and edge attributes. Enterprise graphs can require terabytes of memory storage, requiring graph ML scientists to build complex training pipelines. Finally, after a model has been trained, they have to be deployed for inference, which requires inference pipelines that are just as difficult to build as the training pipelines.
GraphStorm 0.1 is a low-code enterprise graph ML framework that allows ML practitioners to easily pick predefined graph ML models that have been proven to be effective, run distributed training on graphs with billions of nodes, and deploy the models into production. GraphStorm offers a collection of built-in graph ML models, such as Relational Graph Convolutional Networks (RGCN), Relational Graph Attention Networks (RGAT), and Heterogeneous Graph Transformer (HGT) for enterprise applications with heterogeneous graphs, which allow ML engineers with little graph ML expertise to try out different model solutions for their task and select the right one quickly. End-to-end distributed training and inference pipelines, which scale to billion-scale enterprise graphs, make it easy to train, deploy, and run inference. If you are new to GraphStorm or graph ML in general, you will benefit from the pre-defined models and pipelines. If you are an expert, you have all options to tune the training pipeline and model architecture to get the best performance. GraphStorm is built on top of the DGL, a widely popular framework for developing GNN models, and available as open-source code under the Apache v2.0 license.
“GraphStorm is designed to help customers experiment and operationalize graph ML methods for industry applications to accelerate the adoption of graph ML,” says George Karypis, Senior Principal Scientist in Amazon AI/ML research. “Since its release inside Amazon, GraphStorm has reduced the effort to build graph ML-based solutions by up to five times.”
“GraphStorm enables our team to train GNN embedding in a self-supervised manner on a graph with 288 million nodes and 2 billion edges,” Says Haining Yu, Principal Applied Scientist at Amazon Measurement, Ad Tech, and Data Science. “The pre-trained GNN embeddings show a 24% improvement on a shopper activity prediction task over a state-of-the-art BERT- based baseline; it also exceeds benchmark performance in other ads applications.”
“Before GraphStorm, customers could only scale vertically to handle graphs of 500 million edges,” says Brad Bebee, GM for Amazon Neptune and Amazon Timestream. “GraphStorm enables customers to scale GNN model training on massive Amazon Neptune graphs with tens of billions of edges.”
GraphStorm technical architecture
The following figure shows the technical architecture of GraphStorm.

GraphStorm is built on top of PyTorch and can run on a single GPU, multiple GPUs, and multiple GPU machines. It consists of three layers (marked in the yellow boxes in the preceding figure):
- Bottom layer (Dist GraphEngine) – The bottom layer provides the basic components to enable distributed graph ML, including distributed graphs, distributed tensors, distributed embeddings, and distributed samplers. GraphStorm provides efficient implementations of these components to scale graph ML training to billion-node graphs.
- Middle layer (GS training/inference pipeline) – The middle layer provides trainers, evaluators, and predictors to simplify model training and inference for both built-in models and your custom models. Basically, by using the API of this layer, you can focus on the model development without worrying about how to scale the model training.
- Top layer (GS general model zoo) – The top layer is a model zoo with popular GNN and non-GNN models for different graph types. As of this writing, it provides RGCN, RGAT, and HGT for heterogeneous graphs and BERTGNN for textual graphs. In the future, we will add support for temporal graph models such as TGAT for temporal graphs as well as TransE and DistMult for knowledge graphs.
How to use GraphStorm
After installing GraphStorm, you only need three steps to build and train GML models for your application.
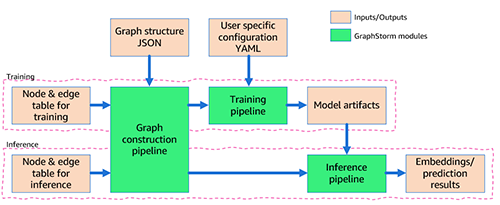
First, you preprocess your data (potentially including your custom feature engineering) and transform it into a table format required by GraphStorm. For each node type, you define a table that lists all nodes of that type and their features, providing a unique ID for each node. For each edge type, you similarly define a table in which each row contains the source and destination node IDs for an edge of that type (for more information, see Use Your Own Data Tutorial). In addition, you provide a JSON file that describes the overall graph structure.
Second, via the command line interface (CLI), you use GraphStorm’s built-in construct_graph component for some GraphStorm-specific data processing, which enables efficient distributed training and inference.
Third, you configure the model and training in a YAML file (example) and, again using the CLI, invoke one of the five built-in components (gs_node_classification, gs_node_regression, gs_edge_classification, gs_edge_regression, gs_link_prediction) as training pipelines to train the model. This step results in the trained model artifacts. To do inference, you need to repeat the first two steps to transform the inference data into a graph using the same GraphStorm component (construct_graph) as before.
Finally, you can invoke one of the five built-in components, the same that was used for model training, as an inference pipeline to generate embeddings or prediction results.
The overall flow is also depicted in the following figure.
In the following section, we provide an example use case.
Make predictions on raw OAG data
For this post, we demonstrate how easily GraphStorm can enable graph ML training and inference on a large raw dataset. The Open Academic Graph (OAG) contains five entities (papers, authors, venues, affiliations, and field of study). The raw dataset is stored in JSON files with over 500 GB.
Our task is to build a model to predict the field of study of a paper. To predict the field of study, you can formulate it as a multi-label classification task, but it’s difficult to use one-hot encoding to store the labels because there are hundreds of thousands of fields. Therefore, you should create field of study nodes and formulate this problem as a link prediction task, predicting which field of study nodes a paper node should connect to.
To model this dataset with a graph method, the first step is to process the dataset and extract entities and edges. You can extract five types of edges from the JSON files to define a graph, shown in the following figure. You can use the Jupyter notebook in the GraphStorm example code to process the dataset and generate five entity tables for each entity type and five edge tables for each edge type. The Jupyter notebook also generates BERT embeddings on the entities with text data, such as papers.

After defining the entities and edges between the entities, you can create mag_bert.json, which defines the graph schema, and invoke the built-in graph construction pipeline construct_graph in GraphStorm to build the graph (see the following code). Even though the GraphStorm graph construction pipeline runs in a single machine, it supports multi-processing to process nodes and edge features in parallel (--num_processes) and can store entity and edge features on external memory (--ext-mem-workspace) to scale to large datasets.
To process such a large graph, you need a large-memory CPU instance to construct the graph. You can use an Amazon Elastic Compute Cloud (Amazon EC2) r6id.32xlarge instance (128 vCPU and 1 TB RAM) or r6a.48xlarge instances (192 vCPU and 1.5 TB RAM) to construct the OAG graph.
After constructing a graph, you can use gs_link_prediction to train a link prediction model on four g5.48xlarge instances. When using the built-in models, you only invoke one command line to launch the distributed training job. See the following code:
After the model training, the model artifact is saved in the folder /data/mag_lp_model.
Now you can run link prediction inference to generate GNN embeddings and evaluate the model performance. GraphStorm provides multiple built-in evaluation metrics to evaluate model performance. For link prediction problems, for example, GraphStorm automatically outputs the metric mean reciprocal rank (MRR). MRR is a valuable metric for evaluating graph link prediction models because it assesses how high the actual links are ranked among the predicted links. This captures the quality of predictions, making sure our model correctly prioritizes true connections, which is our objective here.
You can run inference with one command line, as shown in the following code. In this case, the model reaches an MRR of 0.31 on the test set of the constructed graph.
Note that the inference pipeline generates embeddings from the link prediction model. To solve the problem of finding the field of study for any given paper, simply perform a k-nearest neighbor search on the embeddings.
Conclusion
GraphStorm is a new graph ML framework that makes it easy to build, train, and deploy graph ML models on industry graphs. It addresses some key challenges in graph ML, including scalability and usability. It provides built-in components to process billion-scale graphs from raw input data to model training and model inference and has enabled multiple Amazon teams to train state-of-the-art graph ML models in various applications. Check out our GitHub repository for more information.
About the Authors
 Da Zheng is a senior applied scientist at AWS AI/ML research leading a graph machine learning team to develop techniques and frameworks to put graph machine learning in production. Da got his PhD in computer science from the Johns Hopkins University.
Da Zheng is a senior applied scientist at AWS AI/ML research leading a graph machine learning team to develop techniques and frameworks to put graph machine learning in production. Da got his PhD in computer science from the Johns Hopkins University.
 Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting advanced science teams like the graph machine learning group and improving products like Amazon DataZone with ML capabilities. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems/robotics scientist – a field in which he holds a phd.
Florian Saupe is a Principal Technical Product Manager at AWS AI/ML research supporting advanced science teams like the graph machine learning group and improving products like Amazon DataZone with ML capabilities. Before joining AWS, Florian lead technical product management for automated driving at Bosch, was a strategy consultant at McKinsey & Company, and worked as a control systems/robotics scientist – a field in which he holds a phd.