Artificial Intelligence
How Earth.com and Provectus implemented their MLOps Infrastructure with Amazon SageMaker
This blog post is co-written with Marat Adayev and Dmitrii Evstiukhin from Provectus.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. Machine Learning Operations (MLOps) provides the technical solution to this issue, assisting organizations in managing, monitoring, deploying, and governing their models on a centralized platform.
At-scale, real-time image recognition is a complex technical problem that also requires the implementation of MLOps. By enabling effective management of the ML lifecycle, MLOps can help account for various alterations in data, models, and concepts that the development of real-time image recognition applications is associated with.
One such application is EarthSnap, an AI-powered image recognition application that enables users to identify all types of plants and animals, using the camera on their smartphone. EarthSnap was developed by Earth.com, a leading online platform for enthusiasts who are passionate about the environment, nature, and science.
Earth.com’s leadership team recognized the vast potential of EarthSnap and set out to create an application that utilizes the latest deep learning (DL) architectures for computer vision (CV). However, they faced challenges in managing and scaling their ML system, which consisted of various siloed ML and infrastructure components that had to be maintained manually. They needed a cloud platform and a strategic partner with proven expertise in delivering production-ready AI/ML solutions, to quickly bring EarthSnap to the market. That is where Provectus, an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
This post explains how Provectus and Earth.com were able to enhance the AI-powered image recognition capabilities of EarthSnap, reduce engineering heavy lifting, and minimize administrative costs by implementing end-to-end ML pipelines, delivered as part of a managed MLOps platform and managed AI services.
Challenges faced in the initial approach
The executive team at Earth.com was eager to accelerate the launch of EarthSnap. They swiftly began to work on AI/ML capabilities by building image recognition models using Amazon SageMaker. The following diagram shows the initial image recognition ML workflow, run manually and sequentially.
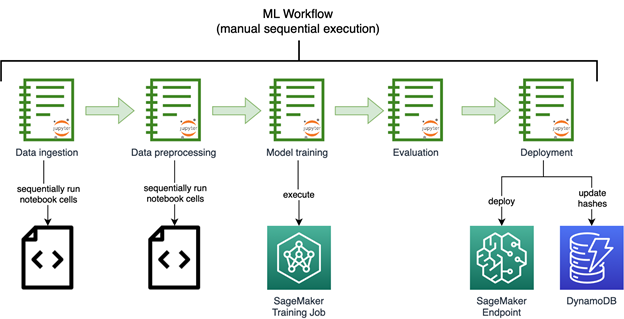
The models developed by Earth.com lived across various notebooks. They required the manual sequential execution run of a series of complex notebooks to process the data and retrain the model. Endpoints had to be deployed manually as well.
Earth.com didn’t have an in-house ML engineering team, which made it hard to add new datasets featuring new species, release and improve new models, and scale their disjointed ML system.
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers.
The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
First iteration of the solution
Provectus served as a valuable collaborator for Earth.com, playing a crucial role in augmenting the AI-driven image recognition features of EarthSnap. The application’s workflows were automated by implementing end-to-end ML pipelines, which were delivered as part of Provectus’s managed MLOps platform and supported through managed AI services.
A series of project discovery sessions were initiated by Provectus to examine EarthSnap’s existing codebase and inventory the notebook scripts, with the goal of reproducing the existing model results. After the model results had been restored, the scattered components of the ML workflow were merged into an automated ML pipeline using Amazon SageMaker Pipelines, a purpose-built CI/CD service for ML.
The final pipeline includes the following components:
- Data QA & versioning – This step run as a SageMaker Processing job, ingests the source data from Amazon Simple Storage Service (Amazon S3) and prepares the metadata for the next step, containing only valid images (URI and label) that are filtered according to internal rules. It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
- Data preprocessing – This includes multiple steps wrapped as SageMaker processing jobs, and run sequentially. The steps preprocess the images, convert them to RecordIO format, split the images into datasets (full, train, test and validation), and prepare the images to be consumed by SageMaker training jobs.
- Hyperparameter tuning – A SageMaker hyperparameter tuning job takes as input a subset of the training and validation set and runs a series of small training jobs under the hood to determine the best parameters for the full training job.
- Full training – A step SageMaker training job launches the training job on the entire data, given the best parameters from the hyperparameter tuning step.
- Model evaluation – A step SageMaker processing job is run after the final model has been trained. This step produces an expanded report containing the model’s metrics.
- Model creation – The SageMaker ModelCreate step wraps the model into the SageMaker model package and pushes it to the SageMaker model registry.
All steps are run in an automated manner after the pipeline has been run. The pipeline can be run via any of following methods:
- Automatically using AWS CodeBuild, after the new changes are pushed to a primary branch and a new version of the pipeline is upserted (CI)
- Automatically using Amazon API Gateway, which can be triggered with a certain API call
- Manually in Amazon SageMaker Studio
After the pipeline run (launched using one of preceding methods), a trained model is produced that is ready to be deployed as a SageMaker endpoint. This means that the model must first be approved by the PM or engineer in the model registry, then the model is automatically rolled out to the stage environment using Amazon EventBridge and tested internally. After the model is confirmed to be working as expected, it’s deployed to the production environment (CD).
The Provectus solution for EarthSnap can be summarized in the following steps:
- Start with fully automated, end-to-end ML pipelines to make it easier for Earth.com to release new models
- Build on top of the pipelines to deliver a robust ML infrastructure for the MLOps platform, featuring all components for streamlining AI/ML
- Support the solution by providing managed AI services (including ML infrastructure provisioning, maintenance, and cost monitoring and optimization)
- Bring EarthSnap to its desired state (mobile application and backend) through a series of engagements, including AI/ML work, data and database operations, and DevOps
After the foundational infrastructure and processes were established, the model was trained and retrained on a larger dataset. At this point, however, the team encountered an additional issue when attempting to expand the model with even larger datasets. We needed to find a way to restructure the solution architecture, making it more sophisticated and capable of scaling effectively. The following diagram shows the EarthSnap AI/ML architecture.
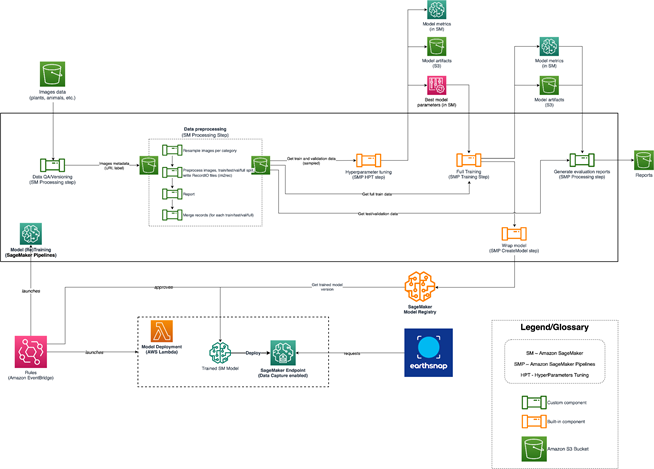
The AI/ML architecture for EarthSnap is designed around a series of AWS services:
- Sagemaker Pipeline runs using one of the methods mentioned above (CodeBuild, API, manual) that trains the model and produces artifacts and metrics. As a result, the new version of the model is pushed to the Sagemaker Model registry
- Then the model is reviewed by an internal team (PM/engineer) in model registry and approved/rejected based on metrics provided
- Once the model is approved, the model version is automatically deployed to the stage environment using the Amazon EventBridge that tracks the model status change
- The model is deployed to the production environment if the model passes all tests in the stage environment
Final solution
To accommodate all necessary sets of labels, the solution for EarthSnap’s model required substantial modifications, because incorporating all species within a single model proved to be both costly and inefficient. The plant category was selected first for implementation.
A thorough examination of plant data was conducted, to organize it into subsets based on shared internal characteristics. The solution for the plant model was redesigned by implementing a multi-model parent/child architecture. This was achieved by training child models on grouped subsets of plant data and training the parent model on a set of data samples from each subcategory. The Child models were employed for accurate classification within the internally grouped species, while the parent model was utilized to categorize input plant images into subgroups. This design necessitated distinct training processes for each model, leading to the creation of separate ML pipelines. With this new design, along with the previously established ML/MLOps foundation, the EarthSnap application was able to encompass all essential plant species, resulting in improved efficiency concerning model maintenance and retraining. The following diagram illustrates the logical scheme of parent/child model relations.
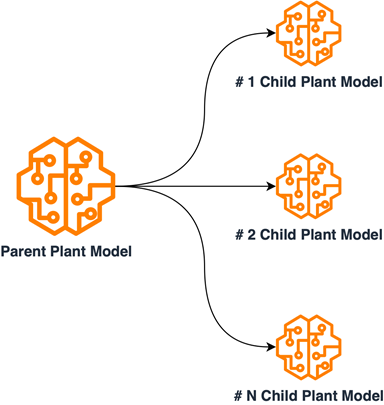
Upon completing the redesign, the ultimate challenge was to guarantee that the AI solution powering EarthSnap could manage the substantial load generated by a broad user base. Fortunately, the managed AI onboarding process encompasses all essential automation, monitoring, and procedures for transitioning the solution into a production-ready state, eliminating the need for any further capital investment.
Results
Despite the pressing requirement to develop and implement the AI-driven image recognition features of EarthSnap within a few months, Provectus managed to meet all project requirements within the designated time frame. In just 3 months, Provectus modernized and productionized the ML solution for EarthSnap, ensuring that their mobile application was ready for public release.
The modernized infrastructure for ML and MLOps allowed Earth.com to reduce engineering heavy lifting and minimize the administrative costs associated with maintenance and support of EarthSnap. By streamlining processes and implementing best practices for CI/CD and DevOps, Provectus ensured that EarthSnap could achieve better performance while improving its adaptability, resilience, and security. With a focus on innovation and efficiency, we enabled EarthSnap to function flawlessly, while providing a seamless and user-friendly experience for all users.
As part of its managed AI services, Provectus was able to reduce the infrastructure management overhead, establish well-defined SLAs and processes, ensure 24/7 coverage and support, and increase overall infrastructure stability, including production workloads and critical releases. We initiated a series of enhancements to deliver managed MLOps platform and augment ML engineering. Specifically, it now takes Earth.com minutes, instead of several days, to release new ML models for their AI-powered image recognition application.
With assistance from Provectus, Earth.com was able to release its EarthSnap application at the Apple Store and Playstore ahead of schedule. The early release signified the importance of Provectus’ comprehensive work for the client.
”I’m incredibly excited to work with Provectus. Words can’t describe how great I feel about handing over control of the technical side of business to Provectus. It is a huge relief knowing that I don’t have to worry about anything other than developing the business side.”
– Eric Ralls, Founder and CEO of EarthSnap.
The next steps of our cooperation will include: adding advanced monitoring components to pipelines, enhancing model retraining, and introducing a human-in-the-loop step.
Conclusion
The Provectus team hopes that Earth.com will continue to modernize EarthSnap with us. We look forward to powering the company’s future expansion, further popularizing natural phenomena, and doing our part to protect our planet.
To learn more about the Provectus ML infrastructure and MLOps, visit Machine Learning Infrastructure and watch the webinar for more practical advice. You can also learn more about Provectus managed AI services at the Managed AI Services.
If you’re interested in building a robust infrastructure for ML and MLOps in your organization, apply for the ML Acceleration Program to get started.
Provectus helps companies in healthcare and life sciences, retail and CPG, media and entertainment, and manufacturing, achieve their objectives through AI.
Provectus is an AWS Machine Learning Competency Partner and AI-first transformation consultancy and solutions provider helping design, architect, migrate, or build cloud-native applications on AWS.
Contact Provectus | Partner Overview
About the Authors
Marat Adayev is an ML Solutions Architect at Provectus
Dmitrii Evstiukhin is the Director of Managed Services at Provectus
James Burdon is a Senior Startups Solutions Architect at AWS