Artificial Intelligence

Optimize pet profiles for Purina’s Petfinder application using Amazon Rekognition Custom Labels and AWS Step Functions
Purina US, a subsidiary of Nestlé, has a long history of enabling people to more easily adopt pets through Petfinder, a digital marketplace of over 11,000 animal shelters and rescue groups across the US, Canada, and Mexico. As the leading pet adoption platform, Petfinder has helped millions of pets find their forever homes. Purina consistently […]

Learn how Amazon Pharmacy created their LLM-based chat-bot using Amazon SageMaker
Amazon Pharmacy is a full-service pharmacy on Amazon.com that offers transparent pricing, clinical and customer support, and free delivery right to your door. Customer care agents play a crucial role in quickly and accurately retrieving information related to pharmacy information, including prescription clarifications and transfer status, order and dispensing details, and patient profile information, in […]
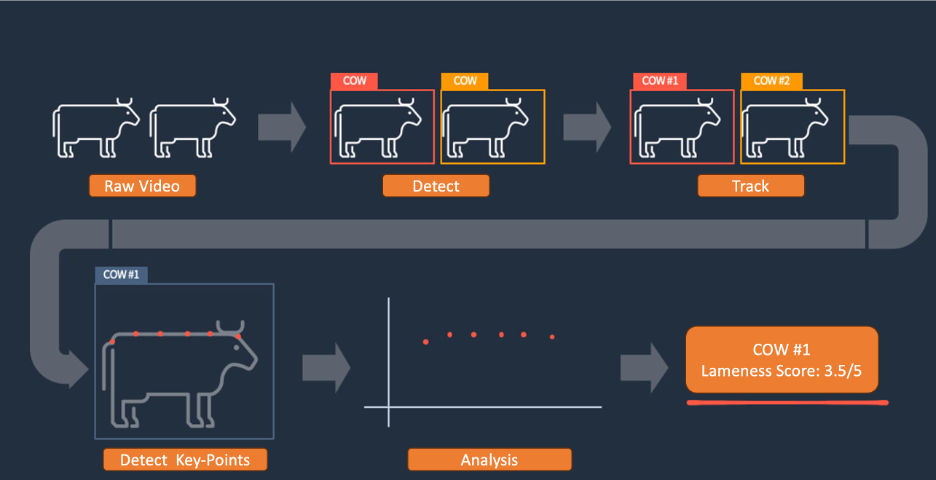
Keeping an eye on your cattle using AI technology
At Amazon Web Services (AWS), not only are we passionate about providing customers with a variety of comprehensive technical solutions, but we’re also keen on deeply understanding our customers’ business processes. We adopt a third-party perspective and objective judgment to help customers sort out their value propositions, collect pain points, propose appropriate solutions, and create […]

Personalize your search results with Amazon Personalize and Amazon OpenSearch Service integration
Amazon Personalize has launched a new integration with Amazon OpenSearch Service that enables you to personalize search results for each user and assists in predicting their search needs. The Amazon Personalize Search Ranking plugin within OpenSearch Service allows you to improve the end-user engagement and conversion from your website and app search by taking advantage […]

How Veriff decreased deployment time by 80% using Amazon SageMaker multi-model endpoints
Veriff is an identity verification platform partner for innovative growth-driven organizations, including pioneers in financial services, FinTech, crypto, gaming, mobility, and online marketplaces. In this post, we show you how Veriff standardized their model deployment workflow using Amazon SageMaker, reducing costs and development time.

Improve performance of Falcon models with Amazon SageMaker
What is the optimal framework and configuration for hosting large language models (LLMs) for text-generating generative AI applications? Despite the abundance of options for serving LLMs, this is a hard question to answer due to the size of the models, varying model architectures, performance requirements of applications, and more. The Amazon SageMaker Large Model Inference […]

Index your web crawled content using the new Web Crawler for Amazon Kendra
In this post, we show how to index information stored in websites and use the intelligent search in Amazon Kendra to search for answers from content stored in internal and external websites. In addition, the ML-powered intelligent search can accurately get answers for your questions from unstructured documents with natural language narrative content, for which keyword search is not very effective.

New – No-code generative AI capabilities now available in Amazon SageMaker Canvas
Launched in 2021, Amazon SageMaker Canvas is a visual, point-and-click service that allows business analysts and citizen data scientists to use ready-to-use machine learning (ML) models and build custom ML models to generate accurate predictions without the need to write any code. Ready-to-use models enable you to derive immediate insights from text, image, and document […]

Whisper models for automatic speech recognition now available in Amazon SageMaker JumpStart
Today, we’re excited to announce that the OpenAI Whisper foundation model is available for customers using Amazon SageMaker JumpStart. Whisper is a pre-trained model for automatic speech recognition (ASR) and speech translation. Trained on 680 thousand hours of labelled data, Whisper models demonstrate a strong ability to generalize to many datasets and domains without the need […]

Reinventing a cloud-native federated learning architecture on AWS
In this blog, you will learn to build a cloud-native FL architecture on AWS. By using infrastructure as code (IaC) tools on AWS, you can deploy FL architectures with ease. Also, a cloud-native architecture takes full advantage of a variety of AWS services with proven security and operational excellence, thereby simplifying the development of FL.