AWS for M&E Blog
Extracting intelligence from corporate streaming using machine learning
With nearly one million minutes of video content forecasted to pass through global IP networks each second by 2021, ensuring that video traffic — especially video produced and consumed by company employees — is valuable, actionable, and personal becomes critical to that company’s success1. Companies today create live and on-demand videos for many purposes, including employee trainings, product tutorials, marketing, analyst meetings, or simply townhall presentations to broadcast news to its employees around the world. Together these videos define corporate streaming. Typically originating as live content, then moving to on-demand, corporate streaming video is forecasted to grow to 70% of all business Internet traffic in 20212. It’s amazing, then, that more is not done to make videos searchable and localized for its users.
This blog will teach you how to make the content of corporate videos searchable beyond the typical title, description and metadata tags, and do so in an automated manner. With that knowledge as the foundation, you’ll find your content will reach broader audiences using machine learning. Viewers will be able to jump to the exact location within videos where company executives appear, view and search captioned text, or listen to an audio track in different languages.
Pique your interest? Let’s get started.
The Basics: The Building Blocks
First, since we’re talking live and on-demand video, you should familiarize yourself with AWS Elemental MediaLive and MediaConvert. There have been several M&E blogs diving into the intricacies of those two services already, so I encourage you to spend some time learning about those services.
Second, if you don’t already know about the machine learning services we’ll be using, here’s a quick primer. Don’t worry. You don’t need to be a data scientist to use these, although basic knowledge is always helpful. Each of these services have reference documentation (typically for their API or SDK) and other tutorials which make learning how to use each service straight-forward. Some even allow you to experiment via the AWS console which is another great way to learn how the services function.
- Amazon Transcribe — automatic speech recognition (ASR) service that makes it easy to add speech-to-text capability. The service provides transcripts with time stamps for every word to help easily locate the audio in the original source by searching for the text, an ability to expand and customize the speech recognition vocabulary, and a speaker identification feature.
- Amazon Translate — neural machine translation service that delivers fast, high-quality, and affordable language translation.
- Amazon Rekognition — intelligent image and video analysis to detect objects, people, text, scenes, and activities, as well as to detect any inappropriate content.
Finally, as the “glue” between the services, we’ll be making use of two additional services, namely: Amazon Simple Notification Service (SNS) which allows other services to subscribe to events — think of these as “triggers” in the IFTTT (“If This Then That”) paradigm; and Amazon Lambda which let you run mini-functions without worrying about provisioning servers.
WORKFLOW: Automatic Transcription and Translation
The workflow we’re going over today — automated transcription and translation of videos — provides a solid foundation for more complex workflows which involve object or person recognition, creation of a spoken audio track in another language, and search for objects, persons, or text which magically take you to the precise location in a video. Note that we’re going over a high-level overview and not the detailed steps (for more detailed assistance, refer to the documentation on (https://docs.aws.amazon.com/index.html). Feel free to contact us if you don’t have the time or the resources.
Once implemented, you should be able to:
- Shoot a live video such as a townhall meeting, interview, analyst call, or product demo
- A few minutes later, you receive the transcript of the video, in as many languages as you’ve pre-selected
- Additionally, the VTT or SRT caption files will appear in as many languages as you’ve indicated as selectable caption options in the video
Let’s walk through the high-level workflow:
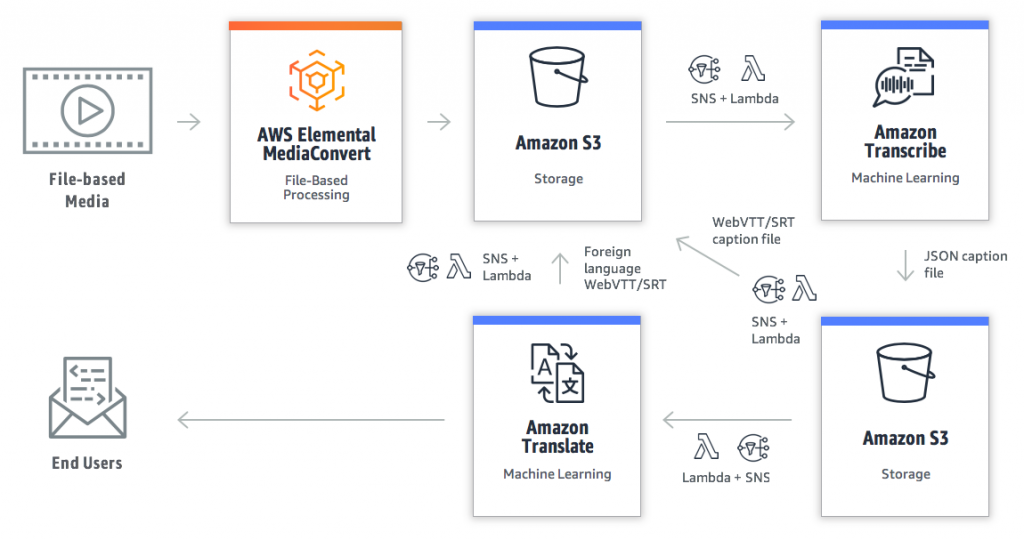
Transcription Workflow: Subtitling a file-based archive of a broadcast or webinar
- A video is encoded in the correct ABR bouquet by MediaConvert and deposited into a S3 bucket.
- Before Transcribe can work its magic, however, the audio must be isolated in WAV, MP3, MP4, or FLAC formats to be used as an input into the Transcribe service. To accomplish this, you can use FFmpeg or other tool. The availability of the VOD asset in S3 triggers an AWS Lambda function stripping out the audio using FFmpeg or equivalent tool, stores the audio file in S3, and initiates Amazon Transcribe on that audio file.
- Once complete, Amazon Transcribe deposits the transcription in JSON format into an S3 bucket.
- The availability of the JSON file triggers an AWS Lambda function to convert it to WebVTT or SRT caption format, as appropriate, so that the captions can be used with the VOD asset. There is publicly available code that takes the JSON and converts it to the right captioned format (of course, you can write your own code to do the same). The Lambda function then saves the SRT or WebVTT file in the same S3 bucket and directory as the VOD asset so that it can be used during video playback.
Translation Workflow: Translation into multiple languages
- The availability of the JSON file in S3 also triggers an AWS Lambda function to initiate Amazon Translate. Translate needs to know in advance the languages into which the text will be translated. (Fortunately, the list is long at 21 languages.)
- The translated JSON file triggers an AWS Lambda function to convert it to WebVTT or SRT format, as appropriate, so that it might be used as an appropriate language file with the VOD asset. Again, the Lambda function then saves the SRT or WebVTT file in the same S3 bucket and directory as the VOD asset with the appropriate language designation.
That’s it. And why might you set up a workflow like the above rather than engaging an external captioning provider? Time, money, and flexibility. Once this workflow is set up, it can be re-used across any number of concurrent events, as AWS services are built for reliability and to scale. And a workflow like this costs a fraction of the cost of a manual captioning service. Finally, teams can build upon the workflow by adding in Amazon Polly to speak the foreign languages in a separate audio track, leveraging Amazon Rekognition to identify clips within videos where executives and actors appear, and utilizing both the JSON transcriptions as well as the JSON recognized actors to enhance the search capabilities of a media asset management (MAM) system. Imagine the efficiencies your organization will gain!
To see other walk-throughs of corporate streaming workflows, download the whitepaper today. And if you have any questions, feel free to reach outto see how we can set up a proof of concept for you.
ENDNOTES:
(1) Cisco VNI Forecasts Highlights Tool, https://www.cisco.com/c/m/en_us/solutions/service-provider/vni-forecast-highlights.html
(2) Cisco VNI Complete Forecasts Highlights, https://www.cisco.com/c/dam/m/en_us/solutions/service-provider/vni-forecast-highlights/pdf/Global_Business_Highlights.pdf