AWS for M&E Blog
[Updated 11-December] Media2Cloud 2.0 now live: Increased control, SageMaker ground truth integration, and more partner support
MEDIA2CLOUD VERSION 2.0 RELEASED
I’m happy to announce that Media2Cloud 2.0 has been officially released to help AWS customers simplify and expedite their ingest workflow into AWS. The following blog post was published when we demonstrated the new version at IBC in September of this year. Now that the new version has officially launched, I wanted to clarify the value of this solution to the industry as it is important to AWS Customers and AWS Partners for different reasons.
For AWS Customers, the solution provides an opportunity to reduce the complexity of getting video and photo content under management along with the supporting metadata through a standard ingest process for content. Since the solution supports standardized metadata, identifiers, proxies, and adding machine learning metadata to content as a foundation, all assets are easier to manage and search for as archives grow.
For AWS Partners, they can accelerate the ingest setup for customers by leveraging Media2Cloud output into their Media Asset Management systems. It creates a secure ingest workflow that can standardize their customers’ content to easily import into their systems to demonstrate the value of their user experience and media tools. I encourage any AWS Partner that is interested in removing a manual ingest activity from their customer implementation to talk to us about how Media2Cloud can accelerate their service setup with their customers.
THE PROBLEM WITH VIDEO INGEST
Let me start by saying I hate the word “ingest” in the context of video workflow. The word is much better suited to the common definition of absorbing food and drink. Candidly, if the process is not well managed for video, the outcome can be very similar. Ingest is often confused with just moving a digital file from one location to another. The true meaning in the term in the industry context is to run a standardized process that performs necessary registration steps to manage content in your digital platform. These steps include a technical inspection of the video file, registering a unique identifier, performing/validating a checksum, creating proxies and thumbnails, and associating descriptive metadata to the asset. These steps are necessary to ensure the integrity of the video asset, ability to uniquely find, manage, and utilize these video assets to power your business. 
ENTER MEDIA2CLOUD
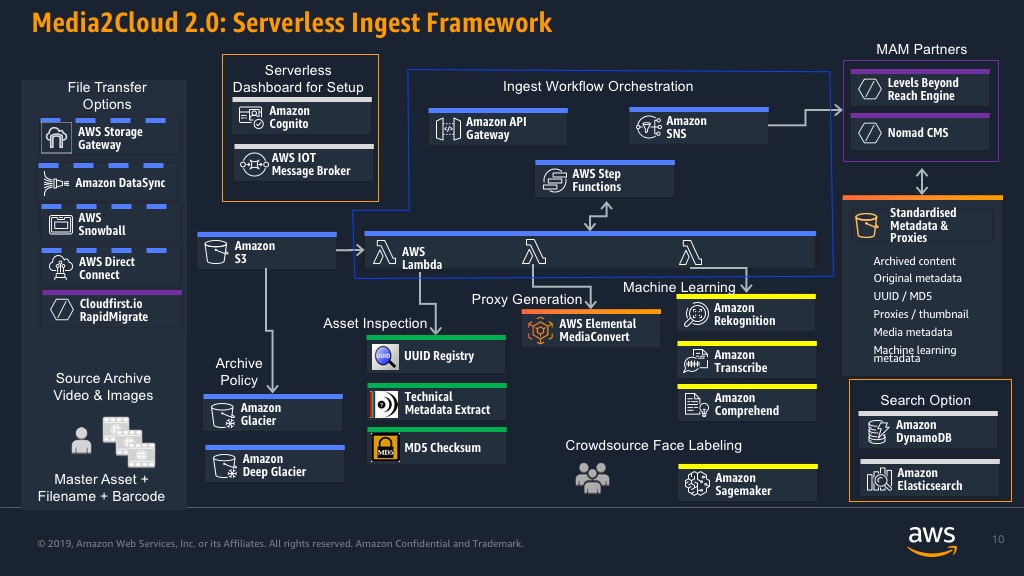
Media2Cloud is an AWS Solution designed to provide a structured process for getting video content under management within AWS. It’s a serverless ingest framework that considers all the best attributes of ingest to ensure that new video assets are processed and supported with consistent metadata and supporting proxies. The framework provides customers with a way of avoiding weeks of setup configuration and provides a secure baseline in which to modify the framework to match the customer’s ingest objective.
It’s now been one year since the initial preview of the Media2Cloud solution at International Broadcast Convention 2018. The following blog post is an update that outlines the issues with managing large scale video content on-premise and how Media2Cloud can help customers and partners establish an elastic ingest model.
Media2Cloud covers the standard essentials for ingesting video content like assigning a UUID, running a MD5 checksum, technical metadata extraction, and the creation of proxies of thumbnails. In addition to this process, the framework includes a trigger to augment the baseline metadata of the video assets with AWS Machine Learning. The video asset will have object and face recognition performed with Amazon Rekognition, speech to text is created via Amazon Transcribe, and contextual metadata is created using Amazon Comprehend. The service is elastic meaning the same workflow can be used to support day to day production and archive migration ingest as long as the requirements are the same. There’s no need to create separate workflows to accommodate capacity, a common issue with on-premise solutions.
WHAT’S NEW
We continue to listen to our customers and are working to make it easier to modify the ingest framework to match the customer needs. Version 2.o, which was previewed at IBC 2019, now supports a configuration panel to decide which machine learning services you wish to use and what language the source content is in. This provides the customer with an easy way to tailor the usage machine learning services to only use the ones that will be appropriate for the source video. For example, if you are ingesting establishing scenic shots, you can select Amazon Rekognition for objects but there’s no need to run facial analysis or use Amazon Transcribe if there’s no audio. The configuration for Amazon Rekognition has also added inappropriate video detection as an option which can support several video compliance use-cases.
Media2Cloud solution will now include SageMaker Ground Truth to provide a crowdsourcing tool supporting custom face curation training. The tool provides an easy to configure front-end to enable a public or private workforce to quickly view, identify and tag faces in the video found by Amazon Rekognition. The training data is fed into a private faces collection in the customer account and added to their facial recognition service. Take for example the rise in demand for content series acquisition. Often times the actors are playing a character and they may be under a lot of makeup or it’s a reality show with a cast that is not in the celebrity database. Sagemaker Ground Truth provides the ability to quickly review the faces from the first episode, tag them with descriptive metadata, and add them to your training model so that they are recognized by facial analysis on subsequent face recognition processing.
PARTICIPATING AWS PARTNERS
The Media2Cloud solution was launched with key partners supporting both ends of the framework, Cloudfirst.io, Levels Beyond, and Nomad-CMS.
In order to enable the customer to tackle on-premise challenges, companies like Cloudfirst.io bridge the gap. CloudFirst.io is an AWS technology partner that supports customers that need to migrate large-scale, often proprietary, physical LTO archive solutions. They actively assist customers with complex, legacy archive migrations helping them establish a migration-to-cloud strategy that does not interfere with day-to-day production activity.
Cloudfirst.io offers a SaaS based tool called Rapid Migrate which helps clients with the heavy-lifting of legacy on-premise, proprietary tape archive systems (i.e. Oracle DIVA, Quantum and IBM) to the cloud. The system essentially provides a means to take advantage of unused resources without interfering with the complexities of existing production workflows. This service enables the mass-migration of assets to AWS Snowball or file transfer to AWS S3 cloud storage in a non-proprietary video format and sidecar metadata file.
It’s key to note that customers will still want a MAM to import and manage this content and metadata. Levels Beyond is an AWS Partner that provides a MAM service platform called Reach Engine. Levels Beyond is able to manage Media2Cloud or interface with the output to consume the JSON formatted metadata to provide customers with a rich search, discovery and management service that can manage the content archive. Reach Engine can provide a number of visualizations to your content inventory, including Timeline Views that support structured metadata analysis, captioning, and most any timeline-based search metaphor. Levels Beyond can support customers further by configuring the services to add additional metadata faceting as well as automating the processing of content for production, OTT, digital publishing and other content related services.
NOMAD-CMS
Our latest partner, Nomad CMS, gives businesses the ability to bring an OTT metadata enrichment and discovery system to their existing S3 assets. Nomad augments S3 asset storage without requiring any changes to the existing asset structure or files themselves – and automatically integrates with Media2Cloud and other AWS AI/ML services. Confidence scores, labels, transcriptions, and other AI enrichment is used to tag each asset with appropriate discovery information. Searching and publishing activities are used to make the resulting metadata available to custom solutions or in support of other integration activities.
MEDIA2CLOUD RAMPING UP TO POPULATE CONTENT LAKES IN AWS
Content Lakes help customers evolve from legacy environments where content is stored in multiple locations like NAS, SAN, HSMs, LTO Robots, desktops, and offline physical media. The Amazon Simple Storage Service (S3) integrated with Glacier and Glacier Deep Archive creates an environment where all content can be stored centrally and leveraged by multiple services, organizations and third-party service providers. Content access is controlled with multiple security mechanisms including encryption at rest and in transit. Content owners don’t need to be worried about the disappearance of critical creative content on an LTO or portable hard drive. The 11 nines of durability, high performance capabilities of S3, combined with the economical tiering with Glacier and Glacier Deep Archive, provide a safe storage environment free of technology refresh issues. The introduction of Intelligent Tiering in storage removes the need to guess at life cycle policies; content owners can store their content in S3 and let it move automatically to the most economical storage tier based on usage. The centralized storage structure helps customers designate a logical storage structure that reduces complexity and redundant processes.
CONCLUSION
Serverless and Machine Learning powered ingest provides an infrastructure capable of supporting both production and archive migrations within the same workflow; the infrastructure will expand and contract to match the processing needs required to create standardized assets and descriptive metadata. Most content owners will tell you that due to the varying state of metadata assets on-premise, they struggle to find what they are looking for in a timely manner. This is also true for content stored in LTO Robots and MAM systems. As employees turn over, often times the understanding of where to find valuable assets in the archive is lost. Establishing a metadata strategy that includes machine learning on each video asset will continue to evolve and raise the bar for search and discovery. Customers can finally tackle metadata atrophy in their process and provides a sustainable means to improve management of content.
The most important point of the design: the customer truly has control of their content!
The point here is that this process can be managed within the customer’s AWS storage. The assets and metadata are published in a manner that removes proprietary formatting. The structure of the content lake creates an ideal environment for maintaining structured metadata, storage and access policies, and automated maintenance; all these factors result in reduced complexity and manual intervention. Customers can focus on higher business challenges such as greater content utility by improving the user experience and media tools that access the content. Customers can provide access to one or more MAM technology providers to empower different use-cases. This enables customers to choose to their MAM partners based on their ability to enable their content driven strategy. The new Media2Cloud template is expected to be available on the AWS website later this year. For more information on Media2Cloud, click here. For more information on Media2Cloud, click here for the solution.