Front-End Web & Mobile
Multi Region Deployment of AWS AppSync with Amazon DynamoDB Global Tables
As organizations grow, they often need to serve geographically dispersed users with low latency, prompting them to have a distributed global infrastructure in the cloud. By leveraging the AWS Global Network to deploy applications into multiple AWS Regions, organizations can allow their users to connect to an API endpoint in the Region with the lowest latency to the API request’s origin, while accessing data automatically kept in sync in real-time across Regions. Furthermore, for applications that require a responsive User Interface (UI), organizations can implement subscriptions with GraphQL to allow the UI to easily query and mutate data in the back-end while being notified in real-time about data changes in any Region.
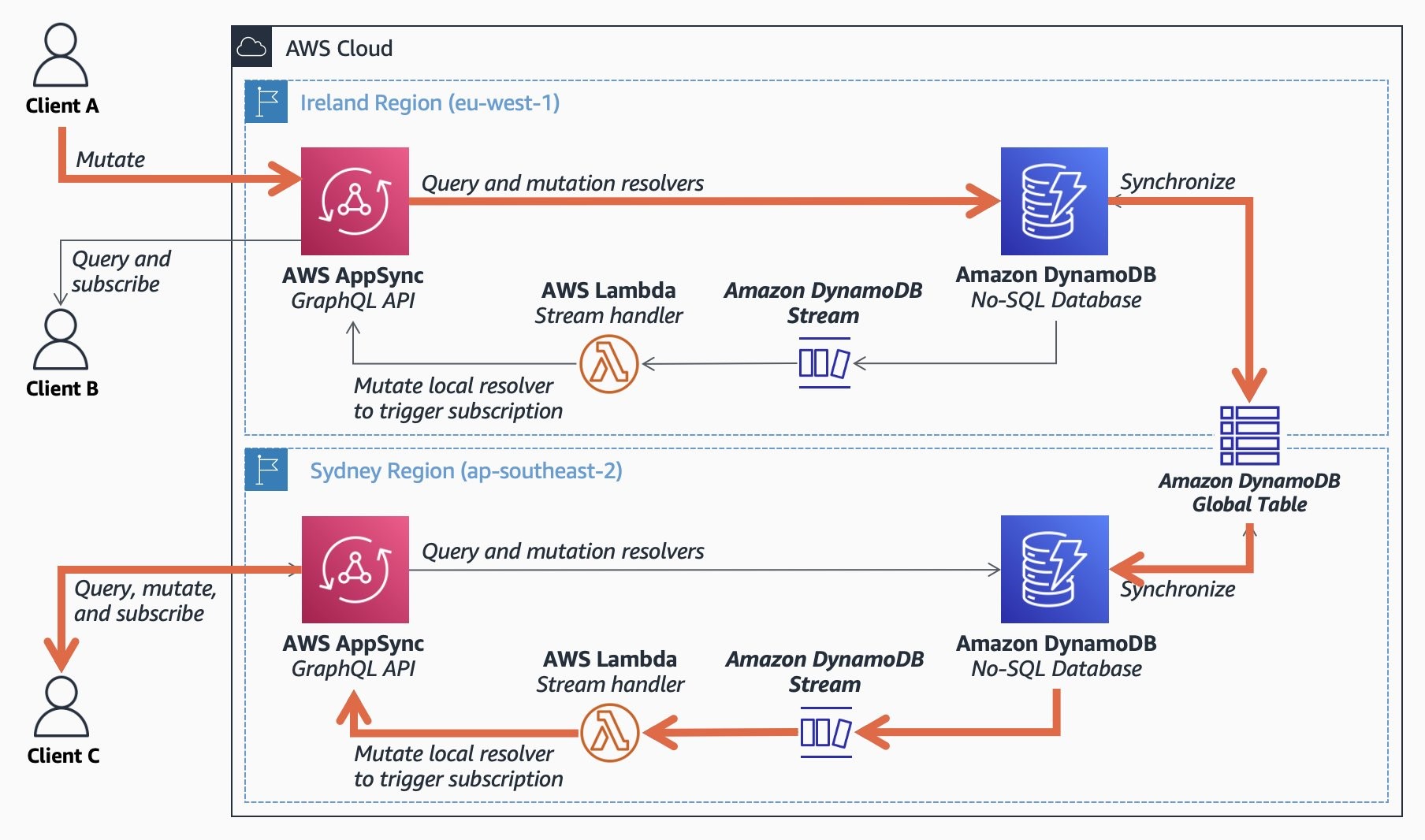
In the scenario depicted in the diagram below, any of the three clients (A, B, and C) can issue a mutation to any of the GraphQL API endpoints, which changes the underlying data in the database. Similarly, all three clients can query and subscribe to any API endpoint to retrieve data and receive notifications for data changes. This ensures that if Client A inserts or changes data through Ireland’s API endpoint, both Client B and Client C eventually receive updated data if they actively query for it, and are notified about the data change if they had subscribed to it, regardless of whether they connected to Ireland’s or Sydney’s API endpoint.

To implement the solution in the diagram, we deploy AWS AppSync in two Regions. AppSync is a fully managed serverless service that makes it easy to develop and host a GraphQL API by handling the heavy lifting required to implement subscriptions, so that organizations can develop their applications with low operational overhead and can focus on the activities that bring value to their customers. AppSync APIs are deployed in a highly available, fault-tolerant and scalable infrastructure within a chosen Region.
To store the application’s data, you can use Amazon DynamoDB (a managed, serverless, key-value NoSQL database), and then enable the Amazon DynamoDB Global Tables feature to automatically replicate the application’s data across Regions with sub-second latency. DynamoDB Global Tables allow your applications to stay highly available even in the unlikely event of isolation or degradation of an entire Region, by constantly replicating your tables automatically across your choice of AWS Regions.
By default, AppSync endpoints only trigger GraphQL subscriptions in response to data mutations received on that same endpoint. This means that if data is changed by any other source or endpoint, as it is the case of multi-Region deployment, then AppSync is not aware of this change and the subscription is not triggered. To address this, you can use AWS Lambda functions and Amazon DynamoDB Streams to enable subscriptions to work globally across Regions. When you enable DynamoDB Streams, it captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores the information for up to 24 hours. Applications can access a series of stream records, which contain an item change, from a DynamoDB stream in near real time.
This blog post describes the key steps to extend AppSync, enabling global applications with GraphQL subscriptions. For ease of understanding, the steps are described in the context of the diagram’s scenario, with only two Regions being used: Ireland (eu-west-1) and Sydney (ap-southeast-2). There is also a pre-built AWS CDK solution that you can deploy to your AWS environment for testing purposes.
Solution Overview
Please note: You are responsible for the cost of the AWS services used while running this solution. As of the date of publication, the cost for running this solution with default settings in the EU West (Ireland) Region is less than $2 per month. This estimate varies based on the number of times the solution is tested, AWS Lambda functions invoked, and Amazon S3 storage fees. AWS AppSync, Amazon DynamoDB and AWS Lambda all offer Free Tier pricing, and we do not expect this solution to exceed those limits. Prices are subject to change. For full details, see the pricing webpage for each AWS service you are using in this solution.
Start by creating one AppSync endpoint in Ireland and another one in Sydney, connecting each of these endpoints to an DynamoDB Global Table. When clients send query requests to AWS AppSync, resolve those requests by querying the relevant data from DynamoDB and returning it back to clients. For mutation requests, insert, delete or update the relevant data in the table.
Then, in DynamoDB, enable the Global Table feature in the tables supporting the AWS AppSync endpoints so that any updates made in the Ireland Region are automatically replicated to the Sydney Region, and vice-versa. After that, enable the DynamoDB Stream feature in each table to further process the data changes received from other Regions via the DynamoDB Global Table feature.
Finally, in each Region, create an AWS Lambda function to invoke a mutation operation in AppSync based on DynamoDB changes, which then triggers GraphQL subscriptions. As a result, each time the DynamoDB table is updated in either Region, it triggers the function to notify the endpoint of the new data. Thus, any client subscribed to data changes in any endpoint, is notified about all changes in both Regions.
To notify the endpoint of the new data, the Lambda Function sends a mutation to the GraphQL API that is linked to a Local Resolver. Instead of calling a remote data source, the Local Resolver just forwards the result of the request mapping template to the response mapping template. This is achieved by using the ‘None’ type data source. Because the request doesn’t leave AWS AppSync, this means that the data sent by the Lambda function is not persisted to the DynamoDB table, ensuring that data is not duplicated.
Active/Active and Active/Passive Configurations
Disaster Recovery strategies can be categorized as Active/Active or Active/Passive. Readers might be interested in how our solution in this blog post can be extended to implement either of these two strategies.
Active/Passive workloads operate from a single AWS Region, which handles all requests. The infrastructure is duplicated in a passive Region. If a disaster event occurs and the active Region cannot support workload operation, then the passive site becomes the recovery site. With AWS AppSync custom domains, an Active/Passive approach can be achieved out of the box by re-assigning the domain (either manually or programmatically) from the primary Region to the passive endpoint in the healthy region in case of a disaster.
If an Active/Active configuration is desired with a single custom domain, our solution in this blog post can be extended by putting an Amazon API Gateway regional API in front of AWS AppSync in each Region, and use latency-based routing in Amazon Route 53 to direct traffic to the backend with the lowest latency. In this case, clients in both Sydney and Ireland can connect to a single DNS custom domain, and regional issues wouldn’t cause unavailability as Route 53 would route traffic to the healthy region. In case cross-region real-time subscriptions is a requirement then Amazon CloudFront should be used instead, you can find more details with both options in the Multi-Region custom-domain AppSync proxy API and the Multi-region GraphQL API with CloudFront reference architectures.
For more information on Disaster Recovery strategies, see this blog post. For more information on AWS AppSync custom domains, see here.
Authorizers
In the example solution, you set up both AWS AppSync endpoints to use API Key Authorization. This means that the client must present a valid API key with each request to be authenticated. An API key is a hard-coded value in your application that is generated by the AWS AppSync service.
AWS AppSync supports a number of different authorization methods to suit different use cases. AWS Lambda authorization allows you to implement your own authorization logic using an AWS Lambda function. In an Active/Active configuration as detailed above, AWS Lambda authorization could be set as the authorization method for all AWS AppSync endpoints, which could allow the same authorization token to be used for any region.
Other authorization types include OpenID Connect (OIDC) to leverage users and privileges defined by third-party OIDC providers, Amazon Cognito User Pools, and AWS IAM authorization. For more information, read the Authorization and Authentication documentation.
Prerequisites
To deploy this solution, the following prerequisites are required.
- An AWS account.
- The AWS CLI – this allows you to interact with AWS services from a terminal session.
- Node JS – check if you already have it installed, using
node --version. - The AWS CDK Toolkit – this is a command line utility that allows you to work with CDK apps; check if you already have it installed using cdk. If it is not installed, then run the following command:
npm install -g aws-cdk - Python and Pip – our CDK project is written in Python, so you’ll need version 3.6 or later.
Note: if you deploy AWS Cloud9, then AWS CLI, Node JS, Python and Pip will already be pre-installed.
Deploy the Solution
Our solution is hosted in the AWS Samples GitHub, and you can find our repository here. Let’s deploy the solution, assuming that you’re using Cloud9.
- Ensure that you have set up a Cloud9 environment in the Ireland region.
- Get the code from the repository onto your Cloud 9 instance. Clone it directly onto your Cloud9 instance using:
- Change directory into the directory by typing:
- Launch the infrastructure contained in these stacks by running the
setup.shscript with the following command: - This setup script occasionally prompts you to confirm if you wish to deploy infrastructure in your account. Type
yand press the return key to grant permission to deploy the infrastructure detailed on screen within your account.
Testing the solution
To test our solution, open the AWS AppSync Console in Ireland in one browser window. In a separate browser window, open the AWS AppSync Console in Sydney. Keep these browser windows side by side and verify that the regions are correct in the top-right corner.
In the Ireland Region, open the GraphQL API titled “IrelandGQLSchema” by clicking on its title.
In the Sydney Region, open the GraphQL API titled “SydneyGQLSchema” by clicking on its title.
In both the Ireland and Sydney browser windows, click on the ‘Queries’ tab on the menu on the left.
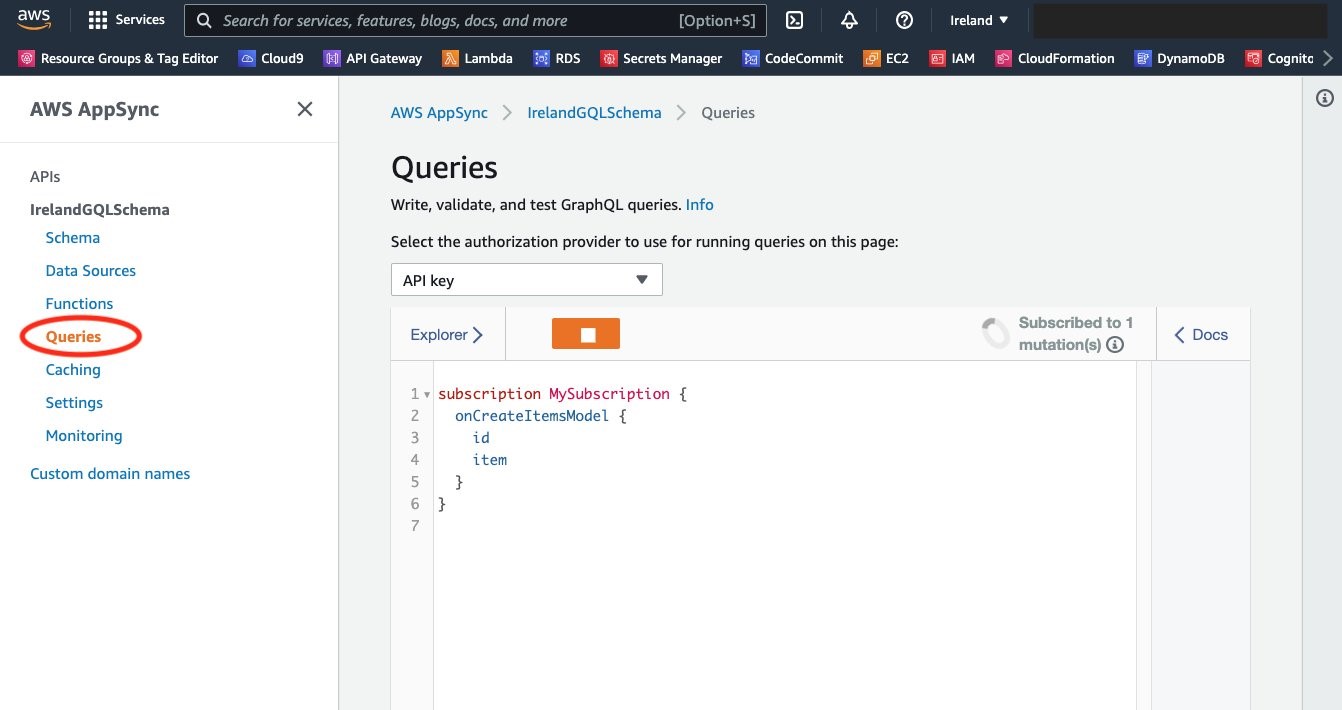
In the Ireland Region, enter the following query into the Query window and click the play button to open a subscription to the Ireland AppSync endpoint.
In the Sydney Region, enter the following mutation into the Query window and click the play button to send the data to the Sydney AppSync endpoint.
In the Ireland Region, where you have a subscription open, observe the new data being received by the client. You should see it appear as below.
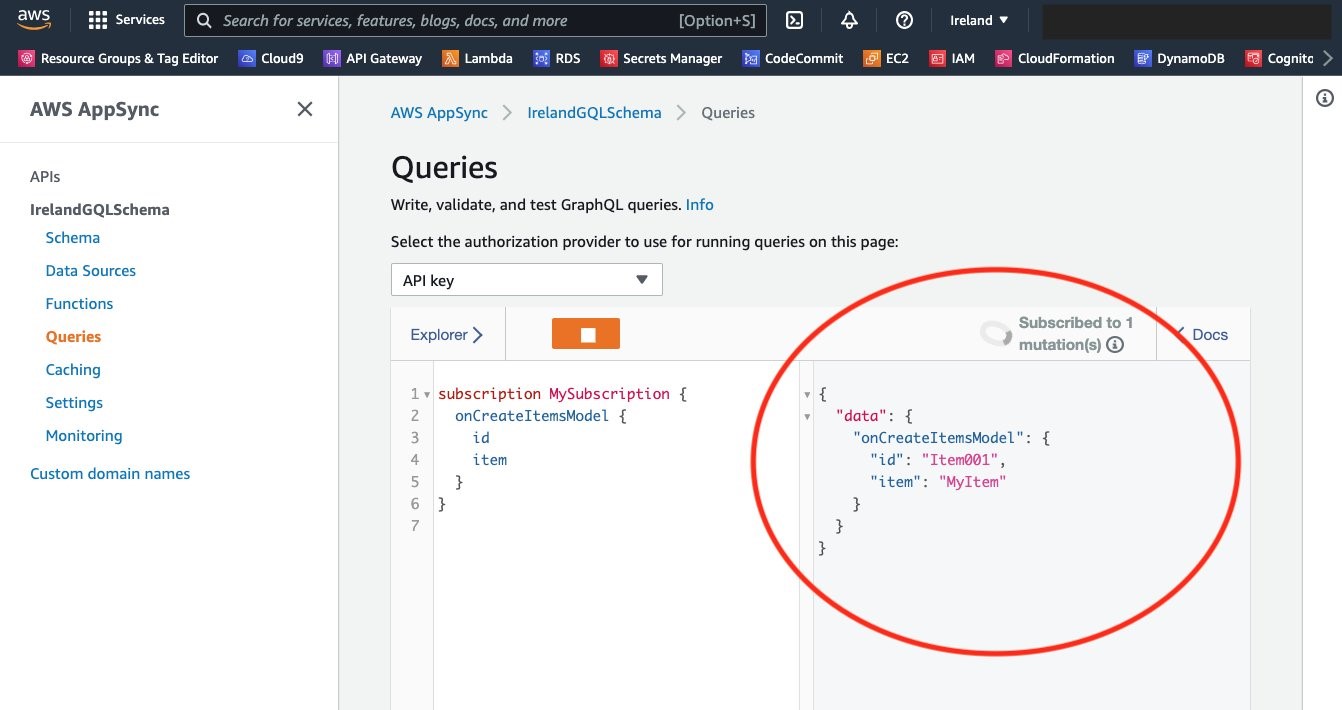
This item was inserted into the Ireland AppSync endpoint, which puts it into DynamoDB. DynamoDB Global Tables replicated data changes across to Sydney. DynamoDB Streams in Sydney triggered the Lambda function with the changes that issued a related mutation to the AppSync endpoint. The update is then automatically pushed to subscribed clients.
You just inserted data, and the global infrastructure ensured that it was received by a separate client subscribed in a separate Region. The journey that your data made is detailed on the following diagram.
Clean up
To clean up the infrastructure launched, execute the following commands from your Cloud9 environment.
Conclusion
This blog post described how organizations can scale their workload globally in the cloud with low latency for geographically dispersed users. The solution provided allows users to connect to the GraphQL API endpoint closest to them and have access to the same data replicated between AWS Regions automatically, by leveraging services like AWS AppSync, AWS Lambda, and AWS DynamoDB with Streams and Global Tables enabled. All the services used in this solution are serverless. Serverless technologies feature automatic scaling, built-in high availability, and a pay-for-use billing model to increase agility and optimize costs. These technologies also eliminate infrastructure management tasks like capacity provisioning and patching, so you can focus on writing code that serves your customers. The solution made use of GraphQL, which allows you to optimize data access with fewer network calls and built-in realtime features.