AWS Open Source Blog
Using PostgreSQL with Spring Boot on AWS — Part 1
This is the first installment of a two-part tutorial by Björn Wilmsmann, Philip Riecks, and Tom Hombergs, authors of the book Stratospheric: From Zero to Production with Spring Boot and AWS. Björn, Philip, and Tom previously wrote the blog posts Getting started with Spring Boot on AWS Part 1 and Part 2.
Introduction
Relational database management systems (RDBMS) are a key component of many types of software applications, web applications in particular. Amazon Relational Database Service (Amazon RDS) is an Amazon Web Services (AWS) service for running RDBMS and relational databases in the cloud.
In this two-part tutorial, we’ll first explore how to deploy an RDBMS on Amazon RDS, and in Using PostgreSQL with Spring Boot on AWS — Part 2, we’ll walk through how to use the database from a Spring Boot web application. We’ll cover the necessary infrastructure deployments and application settings, and techniques and approaches for using relational databases for storing and retrieving data.
Deploying a database
PostgreSQL is one of the most popular open source database products, as of June 2021, only trailing behind MySQL in terms of market share of open source database management systems. MySQL taking first place can be attributed (at least in part) to it being the database technology used by WordPress, an open source content management system that powers about 40% of all websites in 2021.
Even when taking non-open-source database products into account, PostgreSQL still comes in at forth place. PostgreSQL provides an array of features, including advanced features such as common table expressions, and cutting-edge features such as first-class support for JSON data types.
Spring Boot, on the other hand, is a widely used open source framework for building Java applications and the Java Virtual Machine (JVM) ecosystem. Building upon the Spring framework, Spring Boot adds auto-configuration and convention over configuration to simplify application development and deployment.
In this tutorial, we explain how to set up and use a PostgreSQL database with a Spring Boot application on Amazon Web Services (AWS), and Amazon RDS in particular.
Web applications and databases
When providing a web application—or in fact most kinds of software—we need a way of persisting both user and system data across sessions. For that, we need some sort of data storage.
Web applications commonly use relational database management systems (RDBMS) for storing data. Due to the language generally used for interacting with them, these database systems are also more commonly known as SQL (Structured Query Language) databases. RDBMS are useful for common CRUD (Create, Read, Update, Delete) operations or time series data, for example.
In this tutorial, we’ll present code examples from a sample Spring Boot application we provide as a showcase for the techniques and use cases presented in our ebook. We’ll use a PostgreSQL database for storing todos, managed by Amazon Relational Database Service (Amazon RDS).
For the database setup and the requisite infrastructure deployment, we’ll use the Java implementation of the AWS Cloud Development Kit (AWS CDK).
Although setting up the database itself involves AWS specifics, using it in our Spring-based application works as one would expect from an ordinary, non-cloud, non-AWS database.
Before going into the details of how to use the database from our Spring Boot application, let’s explore what Amazon RDS offers and how we can automate the provisioning of a database for our application.
Introduction to Amazon Relational Database Service
Amazon Relational Database Service (RDS) is the AWS service for running and managing relational databases.
Apart from PostgreSQL, MySQL, MariaDB, Oracle Database, and Microsoft SQL Server, Amazon RDS also supports Amazon’s own Amazon Aurora database technology. Aurora is a MySQL- and PostgreSQL-compatible RDBMS designed with requirements of highly scalable cloud applications in mind.
Amazon RDS allows us to create and manage relational databases on AWS using its common tools and techniques such as the AWS Command Line Interface (AWS CLI), AWS Identity and Access Management (IAM), and AWS Cloud Development Kit (AWS CDK).
In addition to using the preceding tools to integrate the database into our AWS environment, we can manage the database through the AWS Management Console.
As usual with AWS services, Amazon RDS provides a scalable infrastructure that grows according to our application’s and our users’ needs. The underlying environment is managed entirely by AWS, which frees us from maintenance headaches.
Prerequisites
You should have basic experience with RDBMS and SQL databases and Spring Boot. If you’d like to automatically and programmatically provision and deploy the necessary infrastructure and resources, a general understanding of AWS Cloud Development Kit (CDK) concepts and how to apply those is required, too.
Deploying the required infrastructure and resources
Next, let’s walk through how to programmatically provision the resources required for running a PostgreSQL database—and a Spring Boot application backed by that database—on AWS and Amazon RDS, specifically.
If you’re not interested in the nitty-gritty of how automated infrastructure deployments work for Amazon RDS, you can have a look at these excellent guides and tutorials from the official AWS documentation that will help you to get up and running with Amazon RDS quickly:
- Setting up for Amazon RDS
- Creating a PostgreSQL DB instance and connecting to a database on a PostgreSQL DB instance
- Tutorial: Create a web server and an Amazon RDS DB instance
- Configuring an Amazon RDS DB instance
In that case, you might want to skip ahead to the section on “Configuring the Database in the Application,” where we’ll connect the database to our Spring Boot application.
Setting up IAM permissions
To access Amazon RDS resources during development, we must attach the AWS managed AmazonRDSFullAccess policy to those IAM groups our application developers are in.
This access is needed to deploy a new database or make changes to an existing database instance via the AWS Management Console or via the CDK app that we’re going to build for that purpose. Once the database is deployed and ready to use, removing full access again is best, at least for production-like environments.
The application itself also needs access to the database, but we will include the permissions for that in the CDK code we’re about to dive into. Hence, the application is decoupled from developer IAM permissions.
Creating a database CDK app
If you want to browse the full CDK code for this tutorial, you can find the relevant files on GitHub. This CDK project uses Java and Maven for provisioning the necessary infrastructure.
The following diagram gives an overview of the infrastructure we’re going to create for our database:
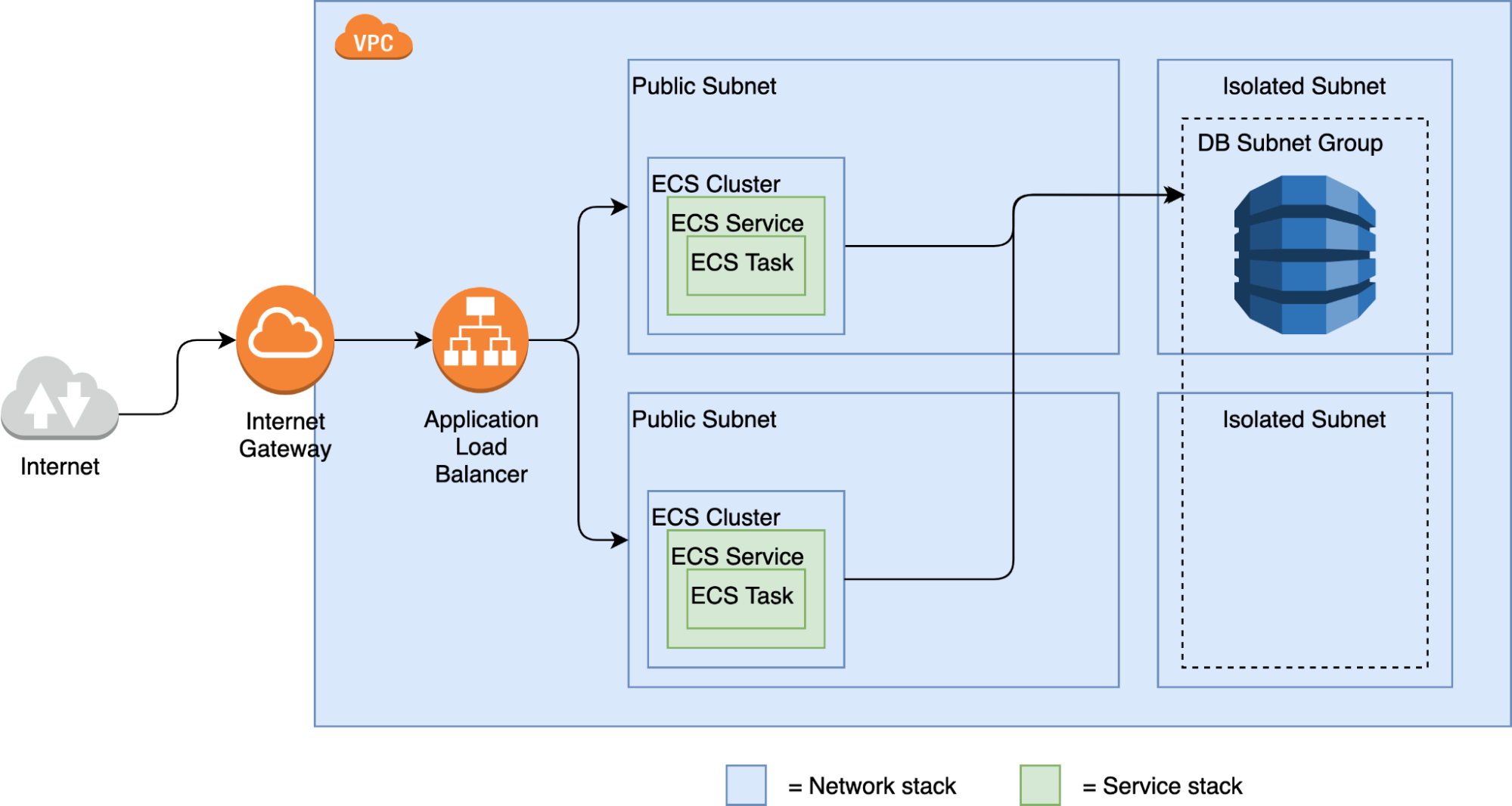
Figure 1: Infrastructure overview
First, we’ll create a new CDK stack for the database. This stack will place a PostgreSQL database instance into private subnets provided by a network stack. The application, which runs in a service stack, will then connect to the database.
The PostgresDatabase CDK construct
To create the necessary environment for our database, we’ll use the PostgresDatabase construct from an open source constructs library we created for Stratospheric. You can browse the construct code on GitHub.
The network stack takes care of creating the basic resources we must run our Spring Boot application and our database. When deployed, it writes a few parameters to the SSM Parameter Store, including information about the isolated subnets it created for the database. The PostgresDatabase construct loads these parameters from the Parameter Store using the the helper method Network.getOutputParametersFromParameterStore():
In case these parameters are not present in the Parameter Store (when the network stack hasn’t been deployed before), the PostgresDatabase construct will fail to deploy.
The PostgresDatabase construct also takes an object of type DatabaseInputParameters as a parameter, which contains configuration parameters it needs to set up the database.
Let’s walk through the PostgresDatabase code to see what it’s doing with all these parameters.
Database security group
First, the construct creates a database security group into which we’ll later put the database. Also, it adds a database subnet group, which combines a set of subnets into a group to be used by database instance:
We later will pass both the subnet group’s name and the security group’s ID into the CfnDBInstance construct that creates our database instance.
Secret for database authentication
Next, we’ll create a Secret called databaseSecret, which will be used as a password for the database:
The secretStringTemplate() method’s argument specifies a JSON structure with the user name. The argument of the generateStringKey() method defines that the generated password be added to this JSON structure in the password field. The resulting JSON string will look like this:
Using the excludeCharacters() method we’re excluding some characters from the password creation because they are not allowed in PostgreSQL RDS instances. If the password contained any of these characters, we’d get an error message saying that “Only printable ASCII characters besides '/', '@', '"', ' ' may be used.”
Database instance
The core of a database stack is the database instance:
We pass the previously created subnetGroup, databaseSecurityGroup, and databaseSecret into the DB instance configuration.
The rest of the configuration parameters we either set statically—like the publiclyAccessible parameter, which we set to false—or we read them from the databaseInputParameters or the networkOutputParameters.
Secret attachment
Finally, we attach the secret to the database:
This associates the secret with the database, so we can take advantage of the secret rotation feature provided by the AWS Secrets Manager.
Output parameters
Finally, the PostgresDatabase construct exports resources from the database stack, so we can use them from other stacks like our service stack:
We’ll need the endpointAddress, endpointPort, databaseName, securityGroupId, and secret parameters in the service stack to connect our Spring Boot application to the database.
Note that parameters stored in the Parameter Store are not encrypted. We are storing the database user name and password here anyway. That means they are visible for anyone with access to the Parameter Store. If that is not sufficient for your security purposes, make sure to store these parameters in the AWS Secrets Manager instead.
Database CDK app
Finally, to be able to deploy our PostgresDatabase construct, we wrap it in a CDK app called DatabaseApp. (The full DatabaseApp code is available on GitHub.)
The app creates a Stack and adds a PostgresDatabase construct to it using the default DatabaseInputParameters. If we wanted to make any of the parameters in DatabaseInputParameters configurable, we could pass them into the app and then into the DatabaseInputParameters from there.
Deploying the database stack
We can run these scripts from the command line to deploy a database stack:
Modifying the service stack
What’s left is to tell our Spring Boot application to use the new database. For this purpose, we modify the service stack that’s responsible for deploying the Docker container in which our application resides. We add the default environment variables Spring Boot uses for defining the database connection:
SPRING_DATASOURCE_URL,SPRING_DATASOURCE_USERNAME,andSPRING_DATASOURCE_PASSWORD.
Spring Boot automatically will read these environment variables and create a data source pointing to our new database.
To this end, in the ServiceApp we first load a NetworkOutputParameters object from the PostgresDatabase construct:
The method getOutputParametersFromParameterStore() is a convenience method we built into the database construct. This method loads all the output parameters we discussed previously into a single object.
Then, we pass these parameters into the environmentVariables() method, which creates a map of all environment variables that should be injected into the Docker container of our Spring Boot app:
We combine the parameters EndpointAddress, EndpointPort, and DBName to create a valid JDBC URL of this format:
We load the user name and password from the Secret we created in the database stack. Note that this secret never leaves the AWS servers. We don’t need to put it into a configuration file anywhere.
Also note that, because the service stack now depends on the output parameters of the database stack, we must deploy the database stack before the service stack.
At this point, our AWS-specific database infrastructure work is done. We now can reap the rewards of our efforts: We can use our newly created database stack and the PostgreSQL database it contains from our Spring Boot application like any other PostgreSQL database.
Conclusion
That’s it so far regarding the deployment of a PostgreSQL database on Amazon RDS. In the second part of this tutorial, we’ll have a look at how to use that database from a Spring Boot application.
 width=”150″ height=”150″ />
width=”150″ height=”150″ />
Björn Wilmsmann
Björn Wilmsmann is an independent IT consultant who helps companies transform their business into a digital business. A longtime software entrepreneur, he’s interested in web apps and SaaS products. He designs and develops business solutions and enterprise applications for his clients. Apart from helping companies in matters of software quality and improving the availability of and access to information through APIs, Björn provides hands-on training in technologies such as Angular and Spring Boot.
 width=”150″ height=”150″ />
width=”150″ height=”150″ />
Philip Riecks
Under the slogan Testing Java Applications Made Simple, Philip provides recipes and tips & tricks to accelerate your testing success on both his blog and on YouTube. He is an independent IT consultant from Berlin and is working with Java, Kotlin, Spring Boot, and AWS on a daily basis.
 width=”150″ height=”150″ />
width=”150″ height=”150″ />
Tom Hombergs
Tom is a senior software engineer at Atlassian in Sydney, working with AWS and Spring Boot at scale. He is running the successful software development blog reflectoring.io, regularly writing about Java, Spring, and AWS with the goal of explaining not only the “how” but the “why” of things. Tom is the author of Get Your Hands Dirty on Clean Architecture, which explores how to implement a hexagonal architecture with Spring Boot.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.