AWS Public Sector Blog
Virginia Tech’s experience building modern analytics on Amazon Web Services
 Virginia Polytechnic Institute and State University (Virginia Tech) wanted to build a modern data warehouse to complete new requests and quickly answer difficult questions in order to make more informed decisions. To do this, we turned to Amazon Web Services (AWS).
Virginia Polytechnic Institute and State University (Virginia Tech) wanted to build a modern data warehouse to complete new requests and quickly answer difficult questions in order to make more informed decisions. To do this, we turned to Amazon Web Services (AWS).
We were looking for a way to build forecasting models faster so we could quickly react to changing conditions. Most tables in our Online Transactional Processing (OLTP) databases do not track the history of data, which meant we had no way of understanding what the data looked like over time. When we wanted to see if a forecasting model had value, we had to start capturing the history in a data mart, which could take three months to gather requirements and develop. Once developed, we would have to wait another six to nine months to capture enough data to derive any value.
With AWS Database Migration Service (AWS DMS), we can capture every table’s history, which allows us to forecast. Instead of the model taking 12 months to mature before I could derive any value from it, I can now see immediate value by ruling out models that do not provide the necessary information.
To improve the learning experience, Virginia Tech has been purchasing industry-leading products, many of which are Software-as-a-service (SaaS) products without access to the underlying database. The backbone of the applications that run Virginia Tech is an Oracle appliance. For most of the student and administrative data, this is our system of record. For reporting, we built a custom data warehouse in Oracle using Talend as our extract, transform, load (ETL) tool.
Getting started
Before we started the data lake project, we did a six-month proof of concept with senior technology team members across multiple departments and skillsets. The data scientist team at Virginia Tech was the primary end user. They were building a new budgeting model that required data from many sources.
Once the proof of concept was completed and we had approval and funding for a production data lake, we assembled a team that included a cloud architect and senior data engineer. To get started with different AWS tools, we attended an AWS Data Lab. This AWS Data Lab helped us to accomplish more in a week than we probably could have over several months.
The framework
The AWS tools are easy to use. For example, after building a framework and figuring out how to ingest data from Oracle, the new sources and tables can be set up as inserting records in a JavaScript Object Notation (JSON) configuration file or Amazon DynamoDB. With AWS, if you build your framework correctly, the need for coding can be eliminated.
The initial source systems included were an Oracle database and two sets of application program interfaces (APIs). The below diagram is how we architected the different zones in our data lake in order to move different types of data. This framework helps us with data governance and security.
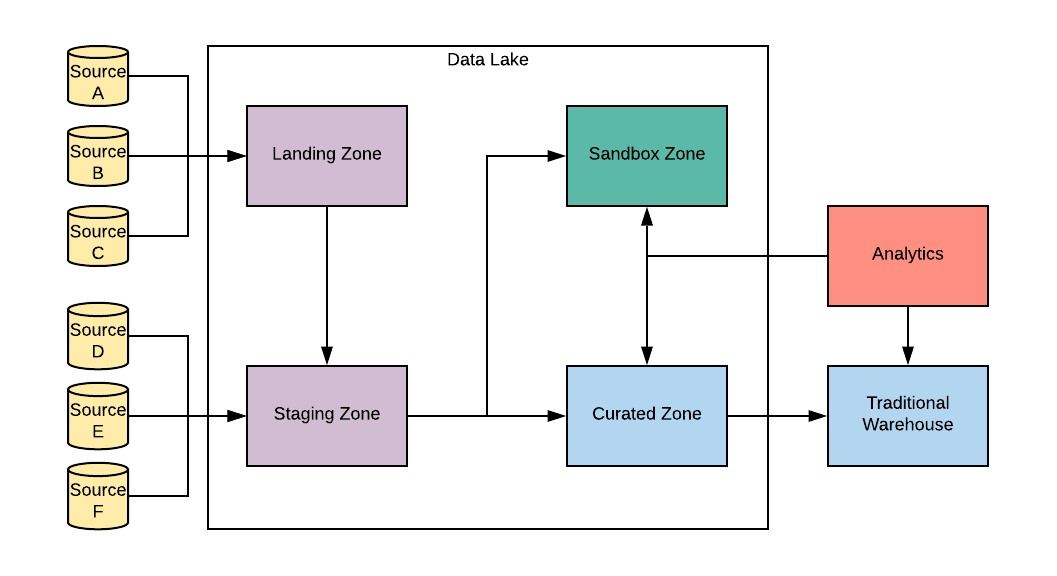
AWS DMS: To get data out of our Oracle database and into our Staging Zone, we use AWS DMS. Once we had AWS DMS set up, adding new tables to the sync became simple. This is a near real-time replication service. Once running, we rarely see a record take more than 10 seconds to make its way to AWS.
In the most recent release of AWS DMS (3.1.4), there is an option to automatically add the action taken (insert, update, delete) and the transaction log timestamp for when it happened. Many of our tables in our databases are either undated or have unreliable dates recorded. These two features help make historical reporting possible and help us to create the curated zone.
AWS Glue: Although we use AWS Glue to run our jobs, the code consists of a simple, 20-line Python script. This is how we kept the process dynamic. When moving data from the staging zone to the curated zone, we take the most recent record and transform the data into Parquet files. When we need to add a new table, we insert a new entry in the JSON, and the Python code knows to begin processing the file. The dates and action indicators that AWS DMS creates make this all possible. We process 100 tables using the same 20 lines of Python.
Amazon RedShift: This is our final structured reporting layer. AWS Glue solves our need to get data from the Curated Zone into Amazon Redshift. We use the AWS Glue crawler to create Amazon Athena (Athena) tables, which allows us to do basic joins and SQL transforms. This is where the standard ETL comes in and where custom code for each dimension table is needed.

Next steps
We run reports with Amazon Redshift. The initial value we see is combining demographic data in Amazon Redshift with web log data by using Amazon Redshift Spectrum. The ability to understand how students use learning tools is valuable.
Currently, we are building out our Amazon Redshift data marts. The more dimensions we add to the database, the more value we can derive from the web logs.
We are also reviewing AWS Step Functions to streamline our AWS Glue jobs. Now that our data in AWS is structured in an optimal way for machine learning (ML) tools, we are looking to build prescriptive models to help us make better decisions that we otherwise aren’t able to see immediately.
Having a strong understanding of AWS DMS, AWS Glue, Athena, and Amazon Redshift helped us get our project moving, and this will benefit us when we start using AWS Lake Formation.
Building our data pipeline in AWS made us rethink many best practices that typical data warehouse developers have relied on for many years. We look forward to expanding our data lake with more sources and features over the next several years.