AWS Storage Blog
How to accelerate your data transfers with AWS DataSync scale out architectures
Do you ever wonder how you can keep up with incoming requests for increased storage capacity without having to expand data center footprint, increase utility spend, and continually handle hardware refresh cycles? Customers are looking to free up space from on-premises storage systems or other clouds, whether it is for existing archival datasets, transitioning their data to be used with cloud compute capabilities, or somewhere in between. Customers that have the available bandwidth to perform online data movement may not want to invest in writing and maintaining scripts, and they may worry about how to verify data when moving data themselves. They are looking for ways to efficiently use their network while performing a migration.
AWS DataSync is an AWS service that helps customers tackle their large data transfer projects. DataSync enables customers to move their file and object data between on-premises storage, edge locations, other public clouds and AWS Storage services, as well as between AWS Storage services.
In the post, I discuss how to scale data transfers with DataSync. This enables you to maximize usage of your available network bandwidth while achieving higher data throughput, reducing overall migration timelines. You can look for scale-out opportunities when your dataset consists of mostly small files, file counts in the millions, or when you have more available network bandwidth than a single DataSync task can consume.
Scale starts with a building block
On-premises data transfers utilize a DataSync agent deployed in your hypervisor environment that acts as a client to connect to your local storage system. The DataSync service orchestrates data movement with the DataSync agent. Data is transferred to or from Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS), and all supported Amazon FSx file systems. A DataSync agent can run one task at a time, and when configured with 64GB of RAM an individual task has a maximum file quota of 50 million files and directories per task.
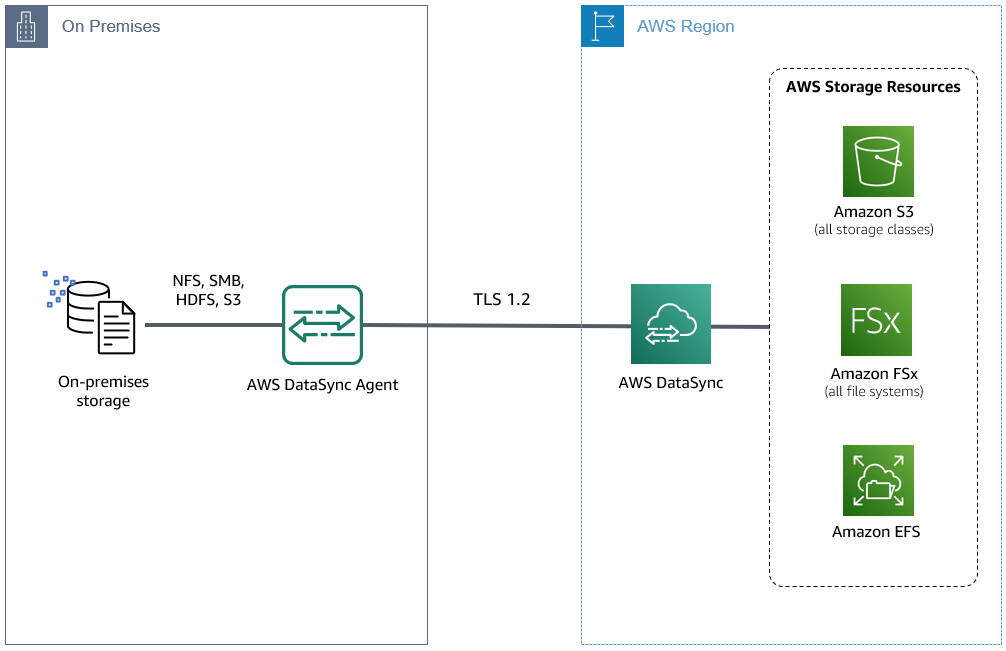
Figure 1: A single DataSync Agent deployed on-premises.
Data transfers between AWS Storage services do not require an agent and are handled entirely by the DataSync service.

Figure 2 : An agentless DataSync transfer
DataSync locations are used as a source or destination for data movement. Location types can be NAS servers (NFS, SMB), Hadoop clusters (HDFS), other clouds, self-managed object storage, and AWS Storage services. Locations configured as NAS servers (NFS, SMB), HDFS, or object storage use a DataSync agent.
Data is transferred as part of a DataSync task that runs manually or on a schedule. A task consists of source and destination locations, as well as various options that define the data transfer. Tasks can transfer an entire dataset from the source location or a task can be configured with include/exclude filters to only transfer essential data.
In use cases where you are transferring archival data that is not changing, a single task execution may be all that is required to transfer an entire dataset. In scenarios where data is changing frequently at the source, you can run a task multiple times and DataSync only transfers data that has changed. Scheduling a task keeps the destination up to date until you are ready for a cutover.
DataSync agents, locations, and tasks are the building blocks for data transfers using DataSync. These components provide a scalable data transfer architecture that helps accelerate your data movement. A scale-out approach consists of running multiple concurrent tasks from different source datasets simultaneously.
Diving into a DataSync task
A DataSync task proceeds through launching, preparing, transferring, and verification phases. When a task is started, it enters the launching phase that initializes the DataSync service to coordinate the data transfer. Then, the task enters the preparing phase that consists primarily of metadata operations as the source and destination locations are scanned to find changes and determine what data must be transferred. Depending on the number of files in your dataset, the prepare phase can take a few minutes to several hours to build the transfer inventory. Next is the transferring phase, which is the data transfer operation that copies data from the source location to the destination location. The last phase is the verify phase. Depending on your selected verification option, the task either verifies only the data transferred, all data on the source and destination, or it skips the final verification step. Regardless of the verification option, all data is verified in flight. The recommended option is to verify only the data transferred.
The performance of a DataSync task is dependent on numerous factors, such as the available network bandwidth, performance of the source and destination storage, as well as the average file size. A task has higher data throughput with larger files from MB to TB in size. Tasks that are transferring small files in the KB range provide higher file throughput.
Scale your data transfers with multiple DataSync tasks
You may now be thinking, “my use case consists of a rather large dataset that contains millions of files across multiple directories, or spans across multiple storage systems. What type of approach can I take to transfer this data efficiently?” For large datasets, we recommend scaling the data transfer using a multi-task and multi-agent architecture. Running multiple tasks in parallel enables you to speed up the data transfer phase by spreading the workload across multiple agents. This approach reduces the number of files and directories that must be processed per task. Furthermore, it results in the simultaneous calculation of file deltas across a large file set. This helps reduce the overall prepare and transfer windows when planning a migration and cutover.
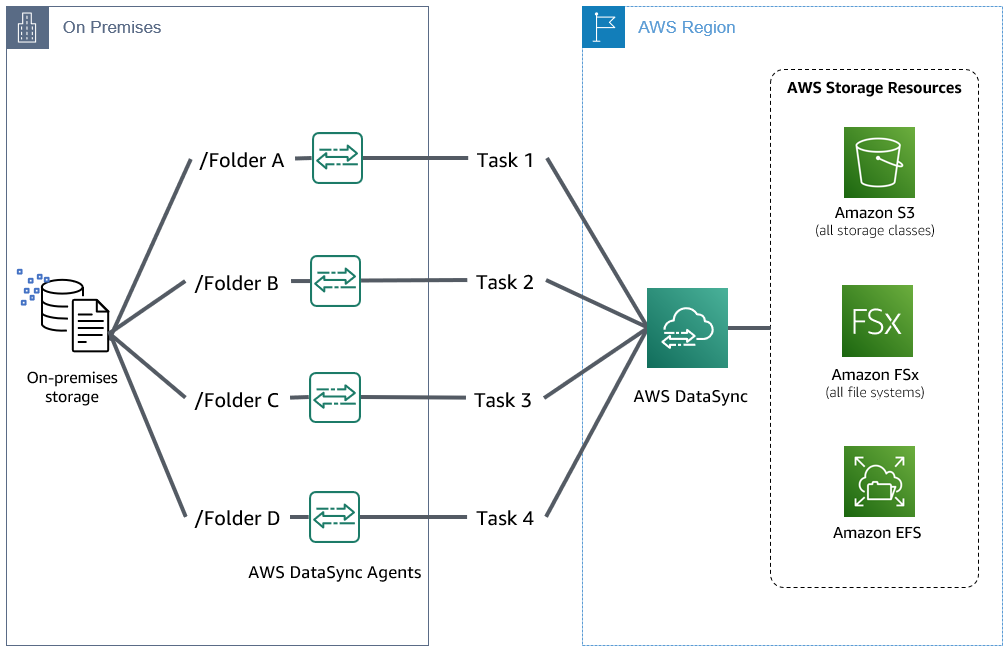
Figure 3: Multiple DataSync Agents deployed on-premises with multiple parallel tasks from a single storage system.
Using a parallel approach, each task is configured to read from a different source dataset by specifying a target path as part of the source location, using task filtering to include or exclude specific data, or a combination of both.
When creating a DataSync location that requires an agent, you specify an agent along with a mount path, share name, or folder, which enables you to narrow the scope of a task to a specific folder in your dataset.
Task filtering can be used to limit reading from a specific set of folders or files on the source location. This is useful if you want to include multiple folders from a top-level export path or further narrow a dataset within the specified source location path. Using an include filter, you can specify unique folder paths for each DataSync task, then run those tasks in parallel.
For example, you have a file share that contains a top level folder called “customers”. The “customers” directory contains additional folders created with unique account names starting with a range from A-Z. You can distribute the data transfer across multiple tasks using include filters unique to each task that consist of “/customer/a*” | “customer/b*” throughout the alphabet range. Using * as a wildcard character includes all customers that begin with a specific letter as part of the task. Note that filters are case sensitive, so you may need to include “/customer/a*” and “/customer/A*” depending on your folder naming conventions. You can combine include filters with exclude filters to also ignore specific datasets as part of the transfer.
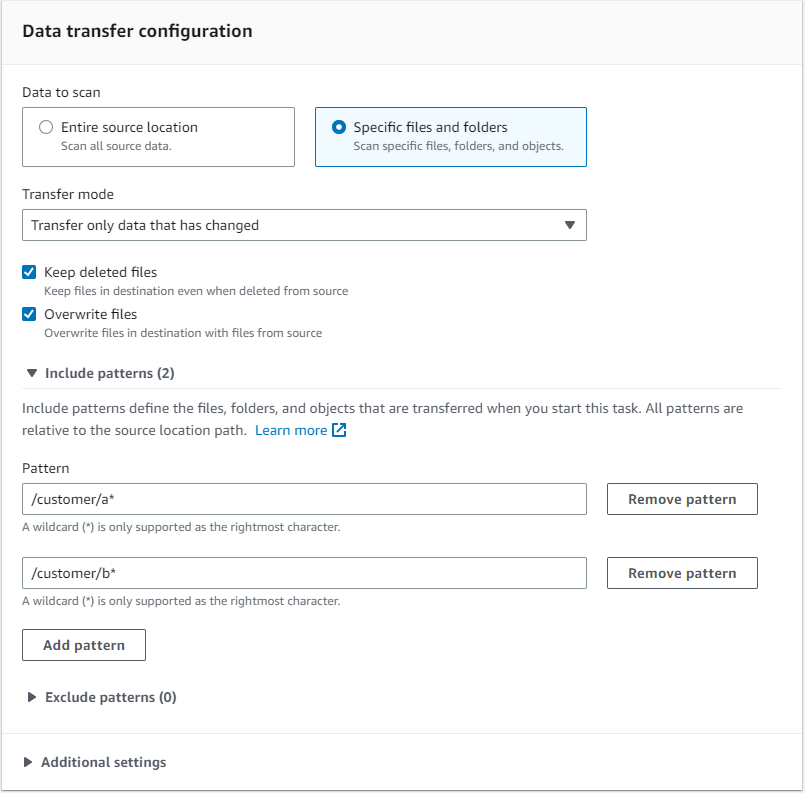
Figure 4: Task filtering options using include patterns to specific folder paths.
Be mindful of additional workloads within your infrastructure
When running parallel DataSync tasks, note the performance characteristics of the source and destination storage systems and the available network bandwidth in your environment. Running tasks simultaneously increases I/O operations on both the source and destination. Work with your storage team and plan I/O workloads before beginning large scale data transfers.
Amazon EFS and Amazon FSx file systems also have sizing considerations for IOPS and throughput. Consider using Elastic Throughout mode for Amazon EFS during a data transfer to automatically scale throughput performance when a task is running.
Amazon FSx file systems have various tuning capabilities that factor into performance. File systems can be deployed with HDD or SSD storage that provide different disk throughput performance, as well as configurations for throughput capacity and provisioned IOPS. Consider adjusting your file system configuration to tune for high throughput data transfers, and then monitor file system performance throughout the transfer. Monitoring performance is important for understanding the utilization of your storage resources before and during a data transfer.
You can monitor AWS file systems using Amazon CloudWatch and the AWS Management Console for each Amazon FSx service. These provide metrics to monitor throughput and IOPS. References to AWS documentation for monitoring and performance details are provided in the following table.
Parallel tasks also increase bandwidth consumption on your network. Starting from a building block approach with a single task, you can estimate throughput performance for your dataset. If each task is achieving 300 MiB/s, then multiple tasks can quickly lead to full utilization of a 10Gb AWS Direct Connect, or your public Internet connection. Planning your expected utilization with your networking team is also an important preliminary step. This same approach can be taken whether you are transferring from a single storage system as in Figure 3, from multiple storage systems as in Figure 5, or across AWS Storage services.
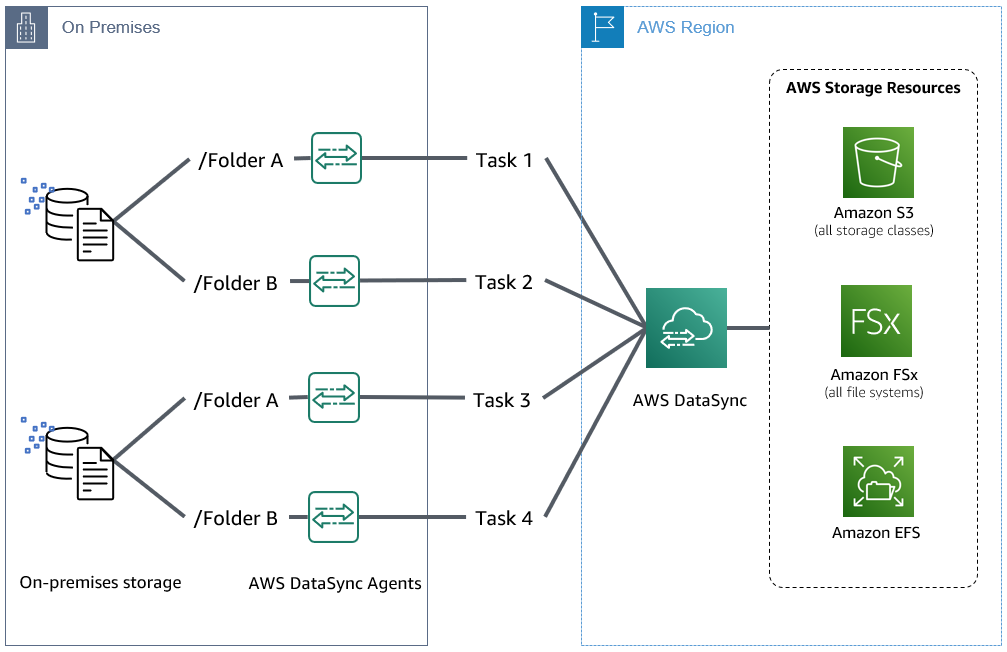
Figure 5: Multiple DataSync Agents deployed on-premises with multiple parallel tasks from multiple storage systems.
Scale out performance with a single DataSync task utilizing multiple agents
Another option to increase the performance of a data transfer is to configure multiple agents as part of a single DataSync task location, as shown in Figure 6. There are scenarios where a data transfer consists of millions of small files and configuring a location to use multiple agents provides additional parallelization that can result in increased file and data throughput. This architecture is beneficial for increasing throughput. However, it won’t reduce the duration of a task’s prepare phase. Additionally, note that multiple agents assigned to a location do not provide high availability. All agents must be online for the task to run successfully.
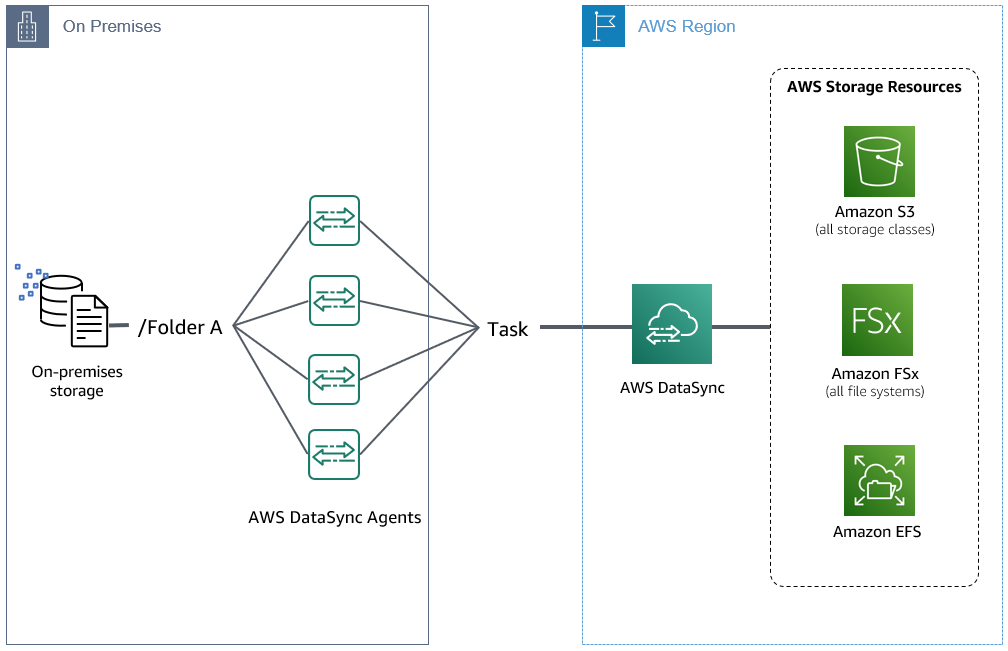
Figure 6: Multiple DataSync Agents deployed on-premises configured with a single location and task.
Mix and match DataSync multiple agent and task methodologies
The ability to scale out multiple tasks and utilize multiple agents per task can also be combined for data transfers at large scale. You can configure multiple tasks to run in parallel, specifying multiple agents as part of each task’s location. This provides the ability for various data transfer use cases, such as the need to migrate an archive dataset while simultaneously running incremental task transfers for changing data. These DataSync scale-out architecture methods can be implemented to the limits that your environment is capable of sustaining.
Conclusion
In this post, I discussed the building blocks of a DataSync data transfer and an overview of various methods to scale out DataSync transfers using multiple agents and multiple tasks. I discussed a multi-task approach using a single agent per task to parallelize data transfers and increase data throughput. I also highlighted the need to plan around multiple factors that include analyzing your available network bandwidth, as well as assessing I/O characteristics of your source and destination storage systems. In addition, I reviewed how to scale out an individual task by utilizing multiple agents as part of a single task location.
You can use these parallelization methods with DataSync to help scale out your data transfer projects. Although I primarily focused on data transfers to and from your on-premises storage, the same scale out technique with multiple tasks also applies to transfers between AWS Storage services, or other public clouds.
These methods enable you to reduce the time to migrate data from storage systems in your data center to an AWS Storage service, transfer data between AWS Storage services, or move your data to the cloud for data processing pipelines.
You can get your data transfer projects started today with DataSync. Read about how Globe Telecom migrated petabytes of HDFS data with DataSync combining the scale out methodologies in this post. To learn more, visit AWS DataSync getting started.