AWS Architecture Blog
Optimize AI/ML workloads for sustainability: Part 1, identify business goals, validate ML use, and process data
Training artificial intelligence (AI) services and machine learning (ML) workloads uses a lot of energy—and they are becoming bigger and more complex. As an example, the Carbontracker: Tracking and Predicting the Carbon Footprint of Training Deep Learning Models study estimates that a single training session for a language model like GPT-3 can have a carbon footprint similar to traveling 703,808 kilometers by car.
Although ML uses a lot of energy, it is also one of the best tools we have to fight the effects of climate change. For example, we’ve used ML to help deliver food and pharmaceuticals safely and with much less waste, reduce the cost and risk involved in maintaining wind farms, restore at-risk ecosystems, and predict and understand extreme weather.
In this series of three blog posts, we’ll provide guidance from the Sustainability Pillar of the AWS Well-Architected Framework to reduce the carbon footprint of your AI/ML workloads.
This first post follows the first three phases provided in the Well-Architected machine learning lifecycle (Figure 1):
- Business goal identification
- ML problem framing
- Data processing (data collection, data preprocessing, feature engineering)
You’ll learn best practices for each phase to help you review and refine your workloads to maximize utilization and minimize waste and the total resources deployed and powered to support your workload.

Figure 1. ML lifecycle
Business goal identification
Define the overall environmental impact or benefit
Measure your workload’s impact and its contribution to the overall sustainability goals of the organization. Questions you should ask:
- How does this workload support our overall sustainability mission?
- How much data will we have to store and process? What is the impact of training the model? How often will we have to re-train?
- What are the impacts resulting from customer use of this workload?
- What will be the productive output compared with this total impact?
Asking these questions will help you establish specific sustainability objectives and success criteria to measure against in the future.
ML problem framing
Identify if ML is the right solution
Always ask if AI/ML is right for your workload. There is no need to use computationally intensive AI when a simpler, more sustainable approach might succeed just as well.
For example, using ML to route Internet of Things (IoT) messages may be unwarranted; you can express the logic with a Rules Engine.
Consider AI services and pre-trained models
Once you decide if AI/ML is the right tool, consider whether the workload needs to be developed as a custom model.
Many workloads can use the managed AWS AI services shown in Figure 2. Using these services means that you won’t need the associated resources to collect/store/process data and to prepare/train/tune/deploy an ML model.

Figure 2. Managed AWS AI services
If adopting a fully managed AI service is not appropriate, evaluate if you can use pre-existing datasets, algorithms, or models. AWS Marketplace offers over 1,400 ML-related assets that customers can subscribe to. You can also fine-tune an existing model starting from a pre-trained model, like those available on Hugging Face. Using pre-trained models from third parties can reduce the resources you need for data preparation and model training.
Select sustainable Regions
Select an AWS Region with sustainable energy sources. When regulations and legal aspects allow, choose Regions near Amazon renewable energy projects and Regions where the grid has low published carbon intensity to host your data and workloads.
Data processing (data collection, data preprocessing, feature engineering)
Avoid datasets and processing duplication
Evaluate if you can avoid data processing by using existing publicly available datasets like AWS Data Exchange and Open Data on AWS (which includes the Amazon Sustainability Data Initiative). They offer weather and climate datasets, satellite imagery, air quality or energy data, among others. When you use these curated datasets, it avoids duplicating the compute and storage resources needed to download the data from the providers, store it in the cloud, organize, and clean it.
For internal data, you can also reduce duplication and rerun of feature engineering code across teams and projects by using a feature storage, such as Amazon SageMaker Feature Store.
Once your data is ready for training, use pipe input mode to stream it from Amazon Simple Storage Service (Amazon S3) instead of copying it to Amazon Elastic Block Store (Amazon EBS). This way, you can reduce the size of your EBS volumes.
Minimize idle resources with serverless data pipelines
Adopt a serverless architecture for your data pipeline so it only provisions resources when work needs to be done. For example, when you use AWS Glue and AWS Step Functions for data ingestion and preprocessing, you are not maintaining compute infrastructure 24/7. As shown in Figure 3, Step Functions can orchestrate AWS Glue jobs to create event-based serverless ETL/ELT pipelines.
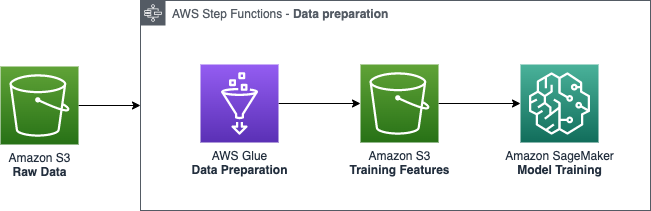
Figure 3. Orchestrating data preparation with AWS Glue and Step Functions
Implement data lifecycle policies aligned with your sustainability goals
Classify data to understand its significance to your workload and your business outcomes. Use this information to determine when you can move data to more energy-efficient storage or safely delete it.
Manage the lifecycle of all your data and automatically enforce deletion timelines to minimize the total storage requirements of your workload using Amazon S3 Lifecycle policies. The Amazon S3 Intelligent-Tiering storage class will automatically move your data to the most sustainable access tier when access patterns change.
Define data retention periods that support your sustainability goals while meeting your business requirements, not exceeding them.
Adopt sustainable storage options
Use the appropriate storage tier to reduce the carbon impact of your workload. On Amazon S3, for example, you can use energy-efficient, archival-class storage for infrequently accessed data, as shown in Figure 4. And if you can easily recreate an infrequently accessed dataset, use the Amazon S3 One Zone-IA class to minimize the total data stored.

Figure 4. Data access patterns for Amazon S3
Don’t over-provision block storage for notebooks and use object storage services like Amazon S3 for common datasets.
Tip: You can check the free disk space on your SageMaker Notebooks using !df -h.
Select efficient file formats and compression algorithms
Use efficient file formats such as Parquet or ORC to train your models. Compared to CSV, they can help you reduce your storage by up to 87%.
Migrating to a more efficient compression algorithm can also greatly contribute to your storage reduction efforts. For example, Zstandard produces 10–15% smaller files than Gzip at the same compression speed. Some SageMaker built-in algorithms accept x-recordio-protobuf input, which can be streamed directly from Amazon S3 instead of being copied to a notebook instance.
Minimize data movement across networks
Compress your data before moving it over the network.
Minimize data movement across networks when selecting a Region; store your data close to your producers and train your models close to your data.
Measure results and improve
To monitor and quantify improvements, track the following metrics:
- Total size of your S3 buckets and storage class distribution, using Amazon S3 Storage Lens
DiskUtilizationmetric of your SageMaker processing jobsStorageBytesmetric of your SageMaker Studio shared storage volume
Conclusion
In this blog post, we discussed the importance of defining the overall environmental impact or benefit of your ML workload and why managed AI services or pre-trained ML models are sustainable alternatives to custom models. You also learned best practices to reduce the carbon footprint of your ML workload in the data processing phase.
In the next post, we will continue our sustainability journey through the ML lifecycle and discuss the best practices you can follow in the model development phase.
Want to learn more? Check out the Sustainability Pillar of the AWS Well-Architected Framework, the Architecting for sustainability session at re:Invent 2021, and other blog posts on architecting for sustainability.
Looking for more architecture content? AWS Architecture Center provides reference architecture diagrams, vetted architecture solutions, Well-Architected best practices, patterns, icons, and more!