AWS News Blog
New – AWS IoT Greengrass Adds Container Support and Management of Data Streams at the Edge

|
AWS IoT Greengrass extends cloud capabilities to edge devices, so that they can respond to local events in near real-time, even with intermittent connectivity.
Today, we are adding two features that make it easier to build IoT solutions:
- Container support to deploy applications using the Greengrass Docker application deployment connector.
- Collect, process, and export data streams from edge devices and manage the lifecycle of that data with the Stream Manager for AWS IoT Greengrass.
Let’s see how these new features work and how to use them.
Deploying a Container-Based Application to a Greengrass Core Device
You can now run AWS Lambda functions and container-based applications in your AWS IoT Greengrass core device. In this way it is easier to migrate applications from on-premises, or build new applications that include dependencies such as libraries, other binaries, and configuration files, using container images. This provides a consistent deployment environment for your applications that enables portability across development environments and edge locations. You can easily deploy legacy and third-party applications by packaging the code or executables into the container images.
To use this feature, I describe my container-based application using a Docker Compose file. I can reference container images in public or private repositories, such as Amazon Elastic Container Registry (Amazon ECR) (ECR) or Docker Hub. To start, I create a simple web app using Python and Flask that counts the number of times it is visualized.
from flask import Flask
app = Flask(__name__)
counter = 0
@app.route('/')
def hello():
global counter
counter += 1
return 'Hello World! I have been seen {} times.\n'.format(counter)
My requirements.txt file contains a single dependency, flask.
I build the container image using this Dockerfile and push it to ECR.
FROM python:3.7-alpine
WORKDIR /code
ENV FLASK_APP app.py
ENV FLASK_RUN_HOST 0.0.0.0
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . .
CMD ["flask", "run"]
Here is the docker-compose.yml file referencing the container image in my ECR repository. Docker Compose files can describe applications using multiple containers, but for this example I am using just one.
version: '3'
services:
web:
image: "123412341234.dkr.ecr.us-east-1.amazonaws.com/hello-world-counter:latest"
ports:
- "80:5000"
I upload the docker-compose.yml file to an Amazon Simple Storage Service (Amazon S3) bucket.
Now I create an AWS IoT Greengrass group using an Amazon Elastic Compute Cloud (Amazon EC2) instance as core device. Usually your core device is outside of the AWS cloud, but using an EC2 instance can be a good way to set up and automate a dev & test environment for your deployments at the edge.
When the group is ready, I run an “empty” deployment, just to check that everything is working as expected. After a few seconds, my first deployment has completed and I start adding a connector.

In the connector section of the AWS IoT Greengrass group, I select Add a connector and search for “Docker”. I select Docker Application Deployment and hit Next.

Now I configure the parameters for the connector. I select my docker-compose.yml file on S3. The AWS Identity and Access Management (IAM) role used by the AWS IoT Greengrass group needs permissions to get the file from S3 and to get the authorization token and download the image from ECR. If you use a private repository such as Docker Hub, you can leverage the integration with the AWS Secret Manager to make it easy for your connectors and Lambda functions to use local secrets to interact with services and applications.

I deploy my changes, similarly to what I did before. This time, the new container-based application is installed and started on the AWS IoT Greengrass core device.

To test the web app that I deployed, I open access to the HTTP port on the Security Group of the EC2 instance I am using as core device. When I connect with my browser, I see the Flask app starting to count the visits. My container-based application is running on the AWS IoT Greengrass core device!
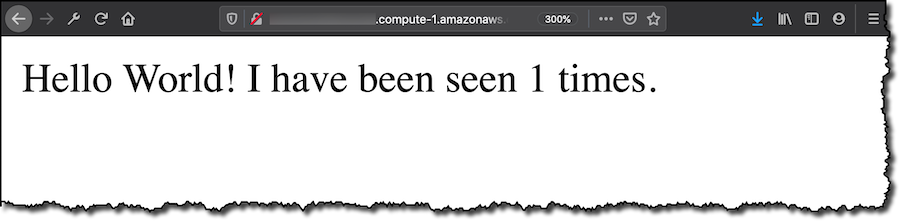
You can deploy much more complex applications than what I did in this example. Let’s see that as we go through the other feature released today.
Using the Stream Manager for AWS IoT Greengrass
For common use cases like video processing, image recognition, or high-volume data collection from sensors at the edge, you often need to build your own data stream management capabilities. The new Stream Manager simplifies this process by adding a standardized mechanism to the Greengrass Core SDK that you can use to process data streams from IoT devices, manage local data retention policies based on cache size or data age, and automatically transmit data directly into AWS cloud services such as Amazon Kinesis and AWS IoT Analytics.
The Stream Manager also handles disconnected or intermittent connectivity scenarios by adding configurable prioritization, caching policies, bandwidth utilization, and time-outs on a per-stream basis. In situations where connectivity is unpredictable or bandwidth is constrained, this new functionality enables you to define the behavior of your applications’ data management while disconnected, reconnecting, or connected, allowing you to prioritize important data’s path to the cloud and make efficient use of a connection when it is available. Using this feature, you can focus on your specific application use cases rather than building data retention and connection management functionality.
Let’s see now how the Stream Manager works with a practical use case. For example, my AWS IoT Greengrass core device is receiving lots of data from multiple devices. I want to do two things with the data I am collecting:
- Upload all row data with low priority to AWS IoT Analytics, where I use Amazon QuickSight to visualize and understand my data.
- Aggregate data locally based on time and location of the devices, and send the aggregated data with high priority to a Kinesis Data Stream that is processed by a business application for predictive maintenance.
Using the Stream Manager in the Greengrass Core SDK, I create two local data streams:
- The first local data stream has a configured low-priority export to IoT Analytics and can use up to 256MB of local disk (yes, it’s a constrained device). You can use memory to store the local data stream if you prefer speed to resilience. When local space is filled up, for example because I lost connectivity to the cloud and I continue to cache locally, I can choose to either reject new data or overwrite the oldest data.
- The second local data stream is exporting data with high priority to a Kinesis Data Stream and can use up to 128MB of local disk (it’s aggregated data, I need less space for the same amount of time).

Here’s how the data flows in this architecture:
- Sensor data is collected by a Producer Lambda function that is writing to the first local data stream.
- A second Aggregator Lambda function is reading from the first local data stream, performing the aggregation, and writing its output to the second local data stream.
- A Reader container-based app (deployed using the Docker application deployment connector) is rendering the aggregated data in real-time for a display panel.
- The Stream Manager takes care of the ingestion to the cloud, based on the configuration and the policies of the local data streams, so that developers can focus their efforts on the logic on the device.
The use of Lambda functions or container-based apps in the previous architecture is just an example. You can mix and match, or standardize to one or the other, depending on your development best practices.
Available Now
The Docker application deployment connector and the Stream Manager are available with Greengrass version 1.10. The Stream Manager is available in the Greengrass Core SDK for Java and Python. We are adding support for other platforms based on customer feedback.
These new features are independent from each other, but can be used together as in my example. They can simplify the way you build and deploy applications on edge devices, making it easier to process data locally and be integrated with streaming and analytics services in the backend. Let me know what you are going to use these features for!
— Danilo