AWS Database Blog
How New Innovations migrated their residency management platform from Microsoft SQL Server to Amazon Aurora PostgreSQL
This is a guest post by Stephen Sciarini, IT Manager at New Innovations.
New Innovations has built a business around shared ideas and beliefs that all point to a larger purpose—empowering medical educators and administrators to provide quality medical education. Intelligence is advancing to the point where there is no separation between task and technology, and the result is that medical trainees and educators can be relieved of mundane administrative duties. Our partners in medical education work with us so that one day this ideal future becomes a reality.
The future is not far away, and thanks to AWS and Amazon Aurora PostgreSQL, our company has been able to build an infrastructure that scales to meet our customers’ demands. AWS Database Migration Service (AWS DMS) made our transition to Aurora PostgreSQL a seamless experience for both our customers and our software developers, while minimizing the risk. We used AWS DMS to fully migrate 700+ instances of Microsoft SQL Server to Aurora PostgreSQL. In addition, Amazon RDS Performance Insights now gives us excellent visibility into our database layer and allows us to respond quickly to any abnormalities.
Company background
Since 1995, New Innovations has been reimagining the way medical trainee data is collected and administered. We provide everything graduate medical education (GME) and undergraduate medical education (UME) programs could need in a single system, including features for achieving and maintaining accreditation. Our suite does the hard work of simplifying administrative and actionable tasks, freeing up their faculty and staff to focus on education. From the intake of students, residents, and fellows to scheduling and performance analysis, New Innovations puts control at their fingertips.
Today our software spans the globe, serving numerous healthcare education disciplines in hospitals, medical schools, and private practices. Our dream is a world free of the administrative constraints facing medical education, so institutions can focus on developing the caregivers who will one day take care of us all.
In the beginning…
Prior to 2014, our infrastructure was hosted in local data centers. But as our footprint expanded, so did our need for more servers and more storage. Anyone who has worked with traditional servers in a data center environment understands the pain and the laborious process of standing up new servers, configuring, hardening, copying data, and so on. Weekly trips to the data center to swap out failing drives and inspect our hardware were not an uncommon occurrence. It was at this point that we started considering cloud hosting, and because of Amazon’s cost, reputation, and HIPAA/FERPA certifications, they were a clear choice for hosting our platform.
At the beginning of 2014, we started migrating our Microsoft SQL Server databases and IIS web servers from our data centers to Amazon EC2. By April of that year, we had migrated our entire workload to AWS and immediately realized cost savings and performance improvements as our site performance increased by over 40 percent. This was completed while achieving less than 15 minutes of planned downtime. Because of the ease of migration, we immediately started taking advantage of other AWS services such as Amazon S3 for file storage, AWS Lambda, AWS WAF, Amazon DynamoDB, and many others.
The problem
After the migration, it became clear that we were starting to outgrow the SQL Server instances—they were costly to run and were becoming a bottleneck for our system. We were running SQL Server 2005, so the team started weighing a number of different options. Upgrading to SQL Server 2014 would have cost us millions of dollars per year in licensing. So the business greenlighted the team’s decision to switch to an open-source database server. PostgreSQL was our choice due to its community, reliability, stability, and option for paid support, if needed.
Next came the decision of hosting. We experimented with a few options such as Amazon RDS and running our own EC2 instances (Aurora PostgreSQL had not yet been announced at this point). AWS already made it effortless to start up a fleet of redundant PostgreSQL servers with Amazon RDS. So we quickly settled on this as our strategy and turned our sights to converting our MSSQL stored procedures and functions to PL/pgSQL.
Object and schema conversion
By far, the object conversion was the most arduous part of the process due to the nearly 11,000 objects in each database. To simplify this process, we created a tool to convert our functions and add comments to a file to indicate how it would need to be rewritten. For example, if a stored procedure had a “TOP 5,” the file that was generated would indicate in comments to the person converting the function to change this to a “LIMIT” clause in PostgreSQL. It was a rather basic program, but it handled many cases and saved us several weeks of work.
In many cases, the code also needed to be updated to work with PostgreSQL depending on the parameter types of functions. This was done in such a way that we could switch our web servers between the PostgreSQL driver and the SQL Server driver with a simple web configuration change.
This was several years ago, and we decided to create our own tool to convert the schema. Since then, customers have widely adopted the AWS Schema Conversion Tool (AWS SCT) as a way to automate the schema conversion process.
Data conversion process
While the developers worked on the object conversion, our DevOps team worked on creating an “easy button” to convert our client databases. In our platform, each client is separated at the database level, and no data is ever co-mingled among clients. The tool would do all the necessary pre-work, set up AWS DMS endpoints and tasks, start them, and also do a little bit of manual conversion on selected tables. Once complete, it would apply indexes, foreign keys, and triggers to the tables and then upload the log files to Amazon S3 for future reference.
PostgreSQL does not have a great way to disable indexes, foreign keys, and triggers, so we followed the PostgreSQL documentation for optimal throughput and added these after all the data was imported. This caused high CPU usage on the servers after the conversion, but it was necessary to shorten the conversion time. To help manage this load, we applied only four indexes at a time. This allowed extra CPU for the other conversions that were running.
We practiced this process multiple times on each of our client databases to verify a smooth and seamless experience for our clients. Part of the “easy button” was a tool built by our DevOps engineer that also verified the data after the conversion. This allowed us to check the integrity of the converted database to make sure that there were no missing records. (Note that AWS DMS had not yet introduced the data validation feature. It has this capability now.)

Data conversion process
Each client’s database averages tens of gigabytes of data to convert, and most completed in 20 minutes or less. During the initial tests using Amazon RDS, we found our bottleneck in this process to be the write throughput to the database.
Enter Aurora PostgreSQL
In the spring of 2017, we received access to the Aurora PostgreSQL beta and immediately began the work of moving from RDS for PostgreSQL to Aurora PostgreSQL. We spun up an Aurora PostgreSQL cluster and converted our development database. We found out that it was a drop-in replacement for Amazon RDS with a few very important improvements: write throughput and automatically expanding storage.
On average, write throughput to Aurora was about three times faster than traditional RDS. The conversion process immediately benefited from this.
The storage subsystem of Aurora automatically expands as needed. In Amazon RDS, we had to create 1 TB volumes for each of our servers because we needed to plan for future storage needs. With Aurora, we pay only for what we use, and we never have to worry about expanding space months down the road.
One of the most valuable tools AWS provides for Aurora is Performance Insights. Our DBA uses this dashboard on a daily basis and is able to isolate slow or CPU-bound queries. It provides a clean way to sort through millions of running queries and pinpoint issues, and it allows us to look at historical data.
In the following example, we found a query that was inefficiently using a temp table. Swapping this to an array variable reduced CPU usage.

Inefficient query causing a spike in CPU usage
Connection pooling
For connection pooling, we knew we could use either pgpool-II or PgBouncer. We opted for PgBouncer because of its simple configuration. To best use Aurora, we had three instances of PgBouncer per Aurora cluster with HAProxy load balancing between them. This setup also allowed one instance of PgBouncer per cluster to be for the read-only instances. We used multiple PgBouncer instances in each Availability Zone for redundancy.
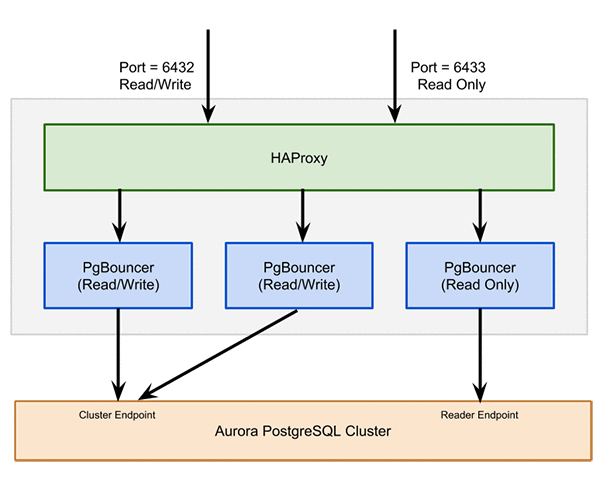
An example of one of our PgBouncer configurations (gray)
Conversion begins
In January 2018, we started our conversion of client databases. It was slated to take us a month to slowly convert each of the 700+ client databases. Each night, we would convert groups that would give us a good mix of different client types based on their usage patterns. We started out with the smaller databases and slowly added more load to each of the servers. Each server handled the load extremely well, so we increased the number of conversions each night.
Although we did performance and load testing in our development environments, it was impossible to do extensive testing on all of our clients. Even though the functions were the same across each client, they may have had different setups and configurations that would have produced different performance issues. Once again, Performance Insights was there to help make sure that we were still maintaining a high level of performance, and it alerted us when there were any issues with specific queries. Identifying these early gave us time to optimize and release updates to production in the evening before it became a problem for our clients when they started work the next morning.
And thanks to the increased write throughput of Aurora, all conversions were finished in just two weeks!
Conclusion
We LOVE Amazon Aurora PostgreSQL and the simplicity of management it provides. Gone are the days of dealing with tuning and tweaking configuration files for optimal performance. Although we didn’t focus on it in this article, AWS Database Migration Service was a fantastic tool for migrating data. It allowed us to focus our efforts on the automation that made this such a successful project.
Now that all of the excitement of the conversion process has died down, we are looking to improve our development environment. In combination with PostgreSQL and Docker, we are working on automating the creation of a Docker image that contains a copy of our production schema. With this, developers can always pull the latest copy and run their migrations and code locally before it even hits our development environment. This was not possible with Microsoft SQL Server without a lot of overhead.
Of course, after an effort that took approximately two years of planning, set up, converting, testing, and re-testing (followed by even more testing), a celebration was in order. Our company provided an afternoon of fun for the employees, including catered BBQ and a keg from a local brewery!

The New Innovations management team with the mobile BBQ truck
Special thanks go to all the employees who spent nights and weekends testing our software during the conversion process. We are proud that the entire company came together to make this such a successful project.
About the Authors
 Stephen Sciarini is the IT Manager at New Innovations and is responsible for security and strategic planning of AWS cloud and other company computing resources. Prior to New Innovations, he was a part time instructor for computer science courses at The University of Akron and worked as a private contractor on a number of projects ranging from charity sites to online application portals.
Stephen Sciarini is the IT Manager at New Innovations and is responsible for security and strategic planning of AWS cloud and other company computing resources. Prior to New Innovations, he was a part time instructor for computer science courses at The University of Akron and worked as a private contractor on a number of projects ranging from charity sites to online application portals.
 Rich Hua is a business development manager for Aurora and RDS for PostgreSQL at Amazon Web Services.
Rich Hua is a business development manager for Aurora and RDS for PostgreSQL at Amazon Web Services.