Amazon Web Services ブログ
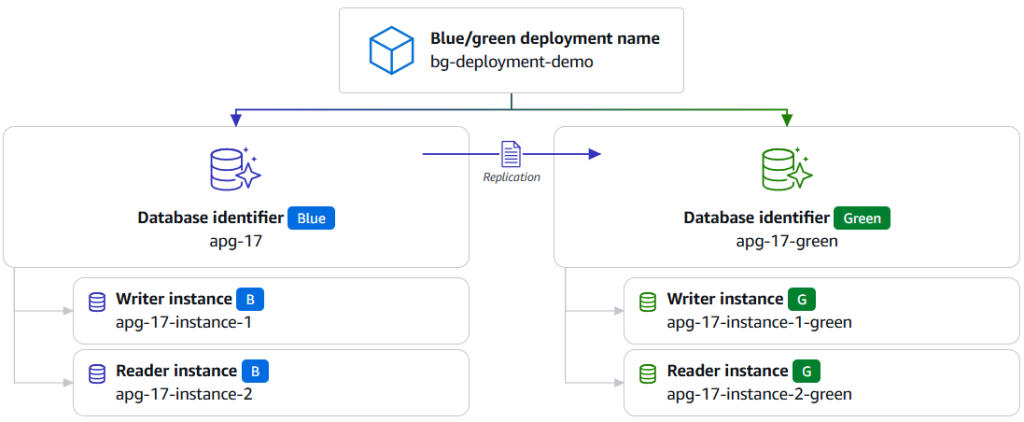
AWS JDBC Driver の Blue/Green デプロイメントプラグインでデータベースメンテナンスのダウンタイムをほぼゼロに
本記事では、AWS JDBC Driver の Blue/Green デプロイメントプラグインを紹介します。このプラグインは、Amazon RDS および Amazon Aurora の Blue/Green デプロイメント切り替え時に、接続ルーティングとトラフィック管理を自動化し、データベースメンテナンスのダウンタイムをほぼゼロにします。プラグインの設定方法とテスト結果を示し、従来の 30 秒超のダウンタイムを約 12 秒の一時停止に短縮できることを実証します。

Amazon Connect Customer とは?エージェンティック AI ソリューションの最新アップデート – 2026 年 4月
こんにちは、Amazon Connect ソリューションアーキテクトの梅田です。2026年 3 月号 はお読み […]

CIRT インサイト: AWS Organizations からの不正なアカウント離脱を防ぐには
AWS Customer Incident Response Team (CIRT) が観測している、攻撃者がお客様アカウントを侵害した後に AWS Organizations から離脱させ、SCP やガバナンス制御を回避する新しい手口について解説します。
具体的には、organizations:LeaveOrganization 権限を持つクレデンシャルが悪用されると、メンバーアカウントが Organization の保護下から外れ、CloudTrail の組織トレイル、GuardDuty の中央集約、SCP による制限、一括請求などの可視性と統制が失われます。
最も効果が大きく労力の少ない対策として、organizations:LeaveOrganization アクションを拒否する SCP (DenyLeaveOrganization) の実装を推奨します。あわせて、CloudTrail での AcceptHandshake / LeaveOrganization / InviteAccountToOrganization / RemoveAccountFromOrganization イベントの監視、IAM の最小権限原則の徹底、およびルートアクセスの一元管理についても解説しています。
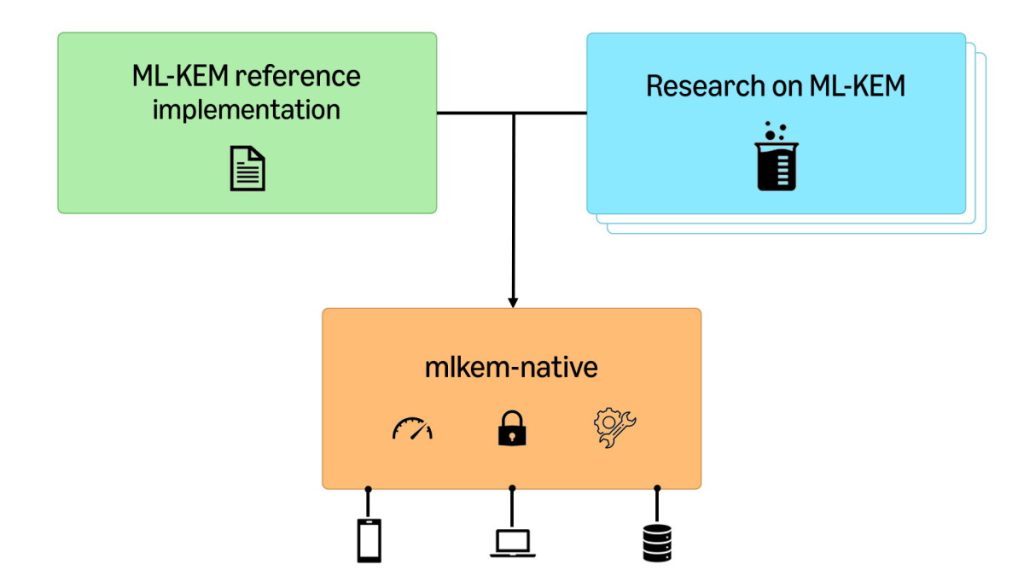
自動推論で実現する Amazon のポスト量子暗号の検証と最適化
AWS は、Amazon Automated Reasoning Group、AWS Cryptography、オープンソースコミュニティと協力し、ポスト量子暗号 (PQC) ML-KEM の形式的に検証された最適化実装 mlkem-native を開発しました。本記事では、CBMC によるメモリ安全性・型安全性の検証、HOL Light と s2n-bignum によるアセンブリ実装の正当性証明、SLOTHY によるマイクロアーキテクチャ最適化を組み合わせ、セキュリティ・性能・保守性を同時に実現した取り組みをご紹介します。AWS-LC への統合により、c7i や c7g で約 2 倍の性能向上を達成しました。

【開催報告】ガバメントクラウドワークショップ 2026 春 ~ AI で実践する開発・モダナイズ・運用 ~
こんにちは。ソリューションアーキテクトの東 健一です。普段はパブリックセクター技術統括本部で中央省庁のお客様の […]

3 か月で開発スピード 3 倍を達成:キヤノン IT ソリューションズ様が実践した AI Coding Agent 導入・普及の仕組みづくり
本記事では、キヤノン IT ソリューションズ株式会社様が 、Amazon Q Developer を開発現場に導入し、3 か月間効果検証を実施した取り組みをご紹介します。コード生成やレビュー支援による効率化、現場での活用事例、そして検証から得られた知見について詳しく解説します。

AWS における AI エージェント対応のデータ基盤 (2) — SageMaker Catalog で行・列レベルのアクセス権を透過的に適用する
本記事は、シリーズ「AWS における AI エージェント対応のデータ基盤」の第 2 回です。第 1 回では、A […]

AWS における AI エージェント対応のデータ基盤 (1) — ツールを配る時代から、データを返す時代へ
AI エージェントに本番データを分析させるには、単にモデルと API をつなぐだけでは足りません。認可、ビジネ […]

Sim-to-Real と Real-to-Sim: 高性能な Physical AI を支える原動力
はじめに、物理 AI システム(現実世界で知覚・推論・行動するロボット)は急速に進化しています。この進歩の中心にあるのが Sim-to-Real パイプラインです。しかし、実験室の外でも安定して動作するモデルを構築することは、この分野で最も難しい課題の一つであり続けています。シミュレーションで機能するものと […]
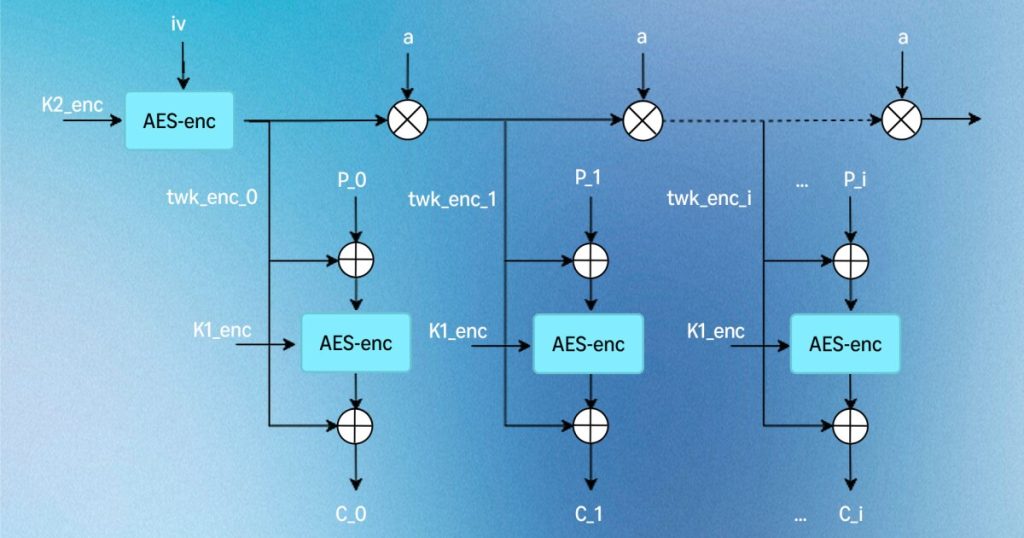
形式的検証済み AES-XTS: s2n-bignum に加わった初の AES アルゴリズム
AWS は AES-XTS 復号の最適化された Arm64 アセンブリ実装の形式的検証に成功し、s2n-bignum ライブラリに初の AES アルゴリズムとして追加しました。本記事では、コア演算のアセンブリコードを単純化することで SLOTHY による自動最適化を可能にし、HOL Light 対話型定理証明器を用いて IEEE 1619 仕様への適合を数学的に証明したプロセスを紹介します。暗号文スティーリングや定数時間設計、メモリ安全性の検証についても解説します。