AWS Partner Network (APN) Blog
Building a Serverless Trigger-Based Data Movement Pipeline Using Apache NiFi, DataFlow Functions, and AWS Lambda
By Nidhi Gupta, Sr. Partner Solutions Architect – AWS
By George Vetticaden, VP, Product Management – Cloudera
By Nijjwol Lamsal, Sr. Partner Engineer – Cloudera
 |
| Cloudera |
 |
Organizations today have a wide range of data processing use cases, collecting data from variety of sources, transforming it and loading it to different destinations to fulfill diverse business needs. The challenge is to control data collection and distribution in a simple, secure, universal, scalable, and cost-effective way.
To solve this problem Cloudera offers Cloudera DataFlow for the Public Cloud (CDF-PC). Cloudera is an AWS Data and Analytics Competency Partner that provides a fast, easy, and secure platform to help customers use data to solve demanding business challenges.
CDF-PC is a cloud-native service for Apache NiFi within the Cloudera Data Platform (CDP). It enables organizations to take control of their data flows and eliminate ingestion silos by allowing developers to connect to any data source anywhere with any structure—then process it and deliver to any destination using a low-code authoring experience.
With the flexibility and freedom to deliver data anywhere quickly, businesses can process real-time data faster, deliver applications more quickly, and turn data into insights more efficiently.
CDF-PC has added support for DataFlow Functions (DFF), which enables developers to build data movement pipelines using Apache NiFi’s low-code but extensible Flow Designer and deploy them as serverless functions.
With DFF, users have the choice of deploying NiFi flows not only as long-running auto scaling Kubernetes clusters on Amazon Elastic Kubernetes Service (Amazon EKS) but also as short-lived functions on AWS Lambda.
DFF provides a low-code user interface (UI) to build functions with increased agility and expands the addressable set of use cases.
In this post, we will learn about building a cost-effective, trigger-based, and scalable serverless application using NiFi flows to run as Cloudera DataFlow function within AWS Lambda.
Use Cases: Event-Driven, Batch, and Microservices
Since 2015, more than 400+ enterprise organizations have adopted Cloudera DataFlow, powered by Apache NiFi, to solve their data distribution use cases. These use cases typically involve high throughput streaming data sources where those streams need to be delivered to destinations with low latency, resulting in the need for always-running clusters.
Customers also have a class of use cases that do not require always-running NiFi flows. These range from event-driven object store processing and microservices that power serverless web applications, to Internet of Things (IoT) data processing, asynchronous API gateway request processing, batch file processing, and job automation with cron/timer scheduling.
For these use cases, the NiFi flows need to be treated like jobs with a distinct start and end. The start is based on a trigger event like a file landing in Amazon Simple Storage Service (Amazon S3), the start of a cron event, or a gateway endpoint being invoked. Once the job completes, the associated compute resources need to shut down.

Figure 1 – DataFlow functions in Cloudera DataFlow service.
With DFF, this class of use cases can be addressed by deploying NiFi flows as short-lived, job-like functions with AWS Lambda. A few example use cases for DFF include:
- Serverless trigger-based file processing pipeline
- Serverless microservices
- Serverless scheduled tasks
- Serverless workflows/orchestration
- Serverless web APIs
- Serverless customized triggers

Figure 2 – Serverless applications using Data Flow Functions.
Trigger-Based Data Movement Pipeline
One of the common use cases for DataFlow Functions is processing files when they are uploaded to Amazon S3 using the S3-based event triggers.
For example, telemetry data from various sensors are batched in a file and sent to a landing zone in a cloud storage bucket on S3. Each line in the telemetry batch file represents one sensor event.
The telemetry batch files are sent periodically throughout the day. When a telemetry batch file lands in S3, the events in the file need to be routed, filtered, enriched, and transformed into parquet format and then stored in S3.
Since the files are sent periodically and don’t require constantly running resources, the need to have a true pay-for-compute model is critical. Once the file is processed, the function and all corresponding resources should be shut down and usage charges should only be attributed for the time the function was executed. The use case mandates providing a cost-effective solution with trade off on high throughput.
The key functional requirements are:
- Routing: Events in the telemetry file need to be sent to different S3 locations based on the “eventSource” value.
- Filtering: Certain events need to be filtered based on various rules (speed > x).
- Enrichment: Geo events need to be enriched with geo location based on the lat/long value using a lookup service.
- Format conversion: The events need to be transformed from JSON to Parquet based on the provided schema.
- Delivery: The filtered, enriched data in Parquet format needs to be delivered to different S3 locations.
The key non-functional requirements are:
- Agile low-code development: Provide a low-code development environment to develop the processing logic with strong SDLC capabilities, including developing and testing locally with test data and promoting to production in the cloud.
- Serverless: The telemetry processing code needs to be run without provisioning or managing infrastructure.
- Trigger-based processing: The processing code and related resources should only be spun up when a new file lands, and once processing completes all resources should be shut down. The need for long-running resources is not required.
- Pay only for compute time: Only pay for compute time used by the processing code; this should not require provisioning infrastructure up front for peak capacity.
- Scale: Support any scale from processing a few files a day to hundreds of files per second.
Implementation
In the use case below, a company collects data from hundreds of telemetry sensors. The telemetry data are batched in a file and sent to S3 data lake throughout the day. The data in S3 needs to be processed and transformed into Parquet format and sent to another set of S3 buckets for further analytics.
The requirement is to provide an agile low-code development for building a cost-effective trigger based scalable serverless architecture.
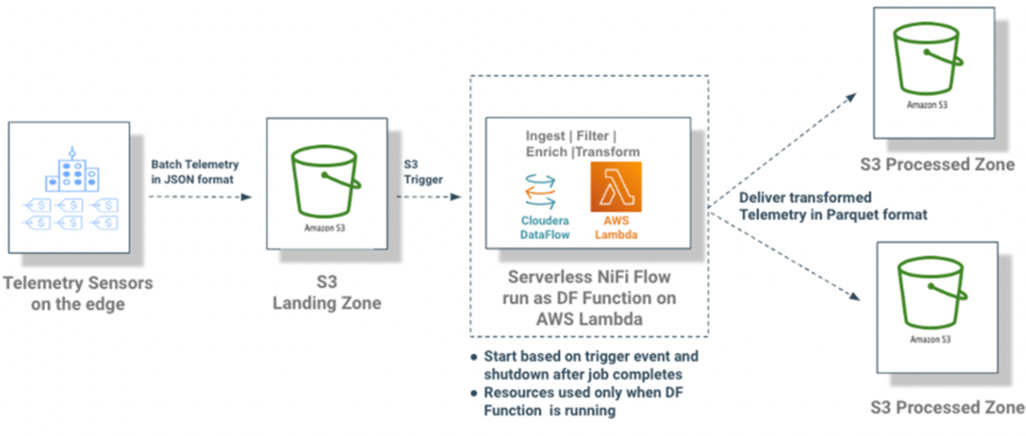
Figure 3 – Low-code, trigger-based, scalable serverless data processing pipeline.
Cloudera implemented this use case using following key services/components:
- Apache NiFi: Apache NiFi’s UI flow designer was used to develop and test the flow locally on the local developer workstation. Cloudera implemented the functional requirements around filter, routing, enrichment, format conversion, and delivering the transformed data in parquet format into different S3 buckets.
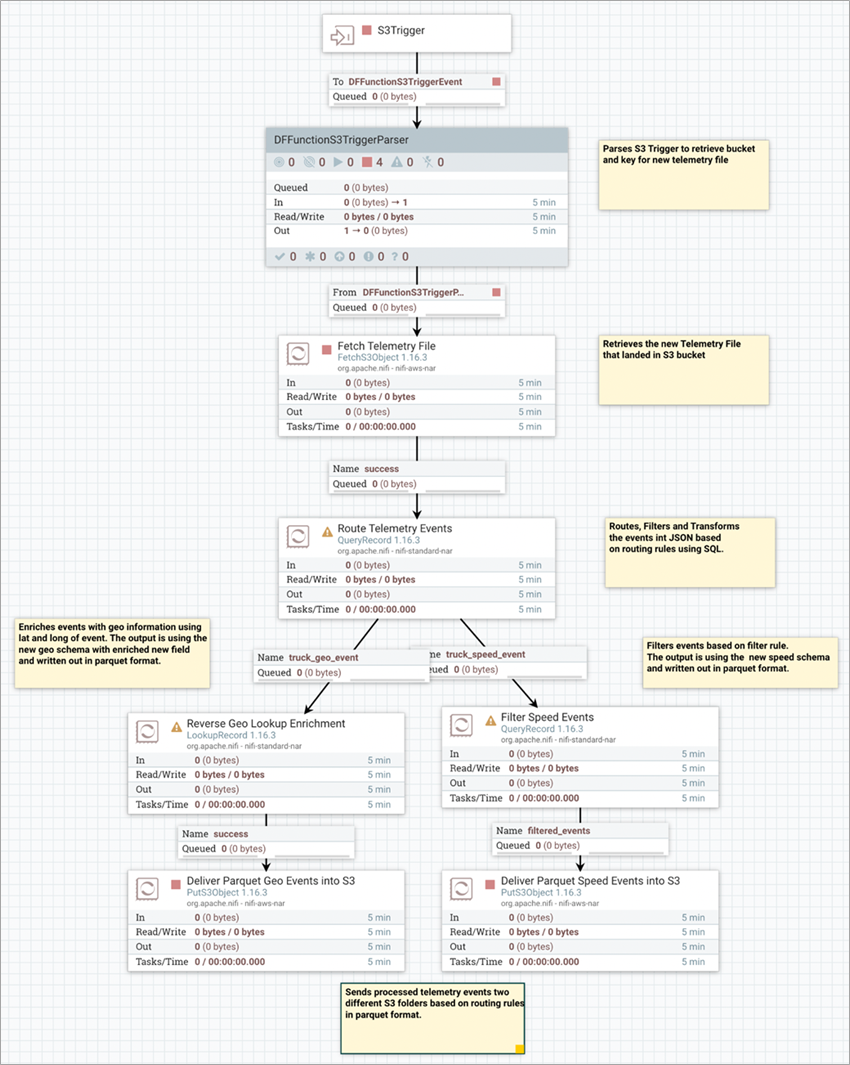
Figure 4 – Building NiFi flows using Apache NiFi flow designer.
- Cloudera DataFlow Service: The locally developed flow is downloaded and registered as DataFlow Function in the DataFlow service catalog.
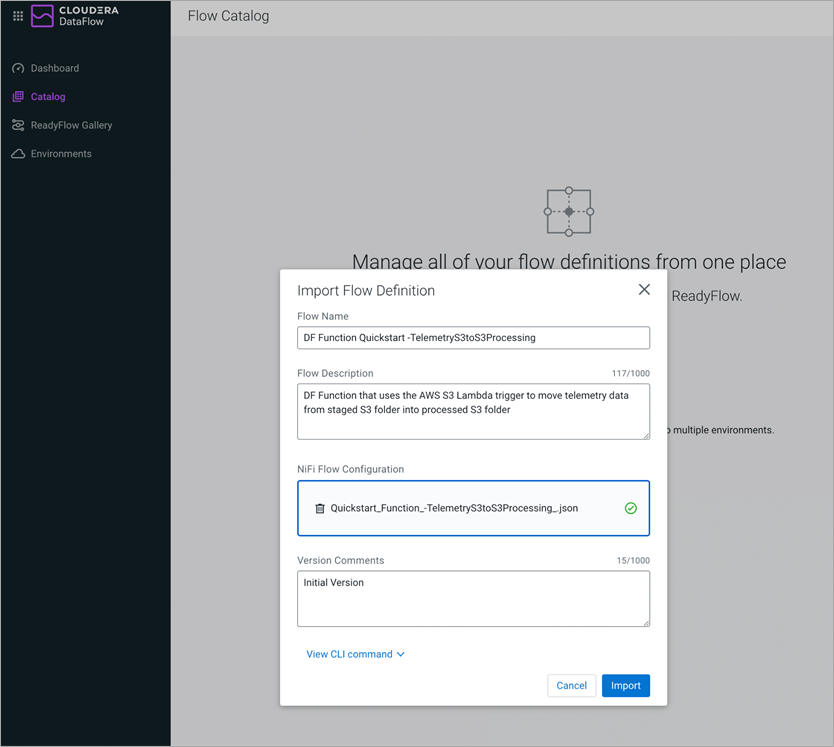
Figure 5 – Registering NiFi Flow in Cloudera DataFlow service catalog.
- DataFlow Functions: In Cloudera DataFlow service, download the Lambda function binaries to run your NiFi flow as a function in AWS Lambda.
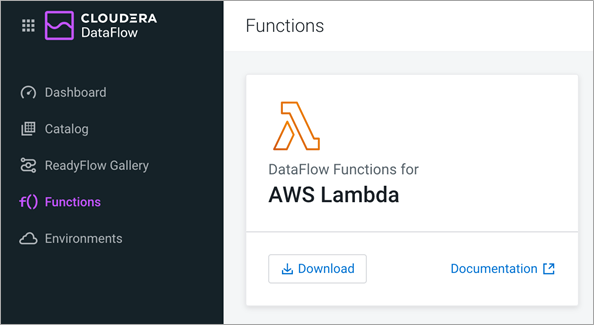
Figure 6 – Download AWS Lambda function handler libraries.
- AWS Lambda: With the NiFi flow developed, tested locally, and registered as a DataFlow function in CDF-PC, you can create the function on AWS Lambda using the AWS Management Console or AWS Command Line Interface (CLI), configure the S3-based event trigger, and test the function.

Figure 7 – Creating AWS Lambda function with Amazon S3 trigger.
The diagram below summarizes the workflow used to implement the trigger-based file processing use case.

Figure 8 – Trigger-based file processing using DataFlow function on AWS Lambda.
Check out the following video for a full end-to-end demo: Serverless NiFi Flows with DataFlow Functions and AWS Lambda.
Summary
In this post, we showed you how to use Amazon S3 to launch a NiFi flow to run as a data flow function that starts based on the trigger event and shuts down after the job is complete.
DataFlow Functions, combined with the serverless compute services provided by AWS Lambda, enables developers to implement a wide spectrum of use cases using the low-code NiFi flow designer UI, and deploy the flows as short-lived serverless functions.
To learn more, check out the DataFlow Functions Product Tour on the Cloudera DataFlow page.
Try it out yourself using the DataFlow Functions quickstart guide that walks you through provisioning a tenant on CDP Public Cloud using the 60-day CDP Public Cloud trial, and shows you how to deploy your first serverless NiFi flow on AWS Lambda.
.

.
Cloudera – AWS Partner Spotlight
Cloudera is an AWS Data and Analytics Competency Partner that provides a fast, easy, and secure platform to help customers use data to solve demanding business challenges.