AWS Partner Network (APN) Blog
Comparing AWS Lambda Arm vs. x86 Performance, Cost, and Analysis
By JV Roig, Field CTO – Cascadeo
By Josh DeMuth, Sr. Partner Solutions Architect – AWS
By Deborshi Choudhury, Sr. Partner Solutions Architect – AWS
By Rishi Singla, Sr. Partner Solutions Architect – AWS
 |
| Cascadeo |
 |
Since September 2021, AWS Lambda has offered customers the choice to run on x86 or Arm-based Graviton2 processors. If you’re a Lambda user who has yet to migrate your functions to Arm, how much performance uplift, cost savings, or both can you expect depending on the kind of workload or runtime you use?
That is exactly the question the team at Cascadeo, an AWS Premier Tier Services Partner and Managed Service Provider (MSP), had in mind when they reached out to Amazon Web Services (AWS) to design an experiment to tease out a data-driven view of Arm vs. x86 Lambdas functions.
From that experiment, we found that switching to Arm-based Lambdas can have significant benefits in terms of performance or cost—and a lot of times, even on both!
In this post, we share interesting findings that can help you gauge the benefits of a potential migration to Arm-based Lambdas, given your very different workloads.
The Big Picture
To cut to the chase, here is the grand result of the experiment, in giant infographic form.

Figure 1 – Results collated in giant infographic form. Click for full-res image.
While the headline results are straightforward, the details and nuances we found are also interesting. Did you know, for example, that Python seems to benefit more from a move to Graviton2 than Ruby?
Before we go deeper into the details, let’s talk about the experiment setup so you understand how we got the data.
The Setup
Using both Arm and x86 architectures, we created nearly 2,000 AWS Lambda functions with different architecture, runtime, memory, worker (threaded-ness / how many cores to attempt to use) and workload configurations. Worker setting and workload are implemented in the Lambda source code, while the rest are Lambda function configuration settings.
It’s near-impossible to test every possible runtime you could ever run on Lambda (especially if considering custom runtimes), so we identified some popular runtimes offered by Lambda out-of-the-box that supported both x86 and Arm architectures: Python, NodeJS, and Ruby. Currently, there are three supported Python versions (3.8, 3.9, and 3.10), three NodeJS versions (14.x, 16.x and 18.x), and only one Ruby version (2.7). This gave us a total of seven different runtimes to test on both Arm and x86.
A quick note on our chosen runtimes: There’s a lag time of several months between our actual activity and when this post was published. The Python, Ruby, and NodeJS versions we chose were what was available at the time.
For each runtime, we created Lambdas with 13 different memory sizes, ranging from 128MB to 10GB.
We also designed five different synthetic workloads to tease out performance differences in different situations:
- CPU-heavy, single-threaded workload (cryptographic hashing using SHA-256).
- CPU-heavy, multi-threaded workload (cryptographic hashing using SHA-256).
- Memory-heavy, single-threaded workload (reading >1GB data and doing an in-memory sort).
- Memory-heavy, multi-threaded workload (reading >1GB data and doing an In-memory sort).
- Light workload (accepting data and issuing a write request to Amazon DynamoDB using that data as payload).
For threaded-ness, we applied multi-core processing in the Lambda code controlled by an environment variable to allow us to run, for example, an Arm-based Lambda on Python 3.8 with 5GB of RAM to use three different worker threads in parallel. This allowed us to have one code that handles both the single-threaded and multi-threaded versions each for the CPU-heavy and memory-heavy synthetic workloads, effectively only needing three different Lambda deployment packages for the five synthetic workloads.
Depending on the synthetic workload, Lambda functions will use different sets of memory configuration. All CPU-heavy workloads use the 13 different memory sizes, and will use 1-6 cores. Memory-heavy workloads only start from 2.5GB of RAM, and only use 1-4 cores. Light workloads only ever use one core, and only scale up from 128MB to 3GB (which is already overkill for a single core)
With these rules, the total number of combinations we got was 1,680 unique Lambda functions (2 architectures x 7 runtimes x 5 workloads x [1-6] workers x [6-13] possible memory configs).
Of course, if we had to manually provision almost 2,000 Lambdas, it would take forever before we finish. Instead, we used the AWS Cloud Development Kit (AWS CDK) to provision the Lambdas programmatically. We then used Lambda Power Tuning and some custom Python code to invoke those Lambda functions and collect benchmark data for analysis. We averaged the performance data we got for each Lambda function across multiple executions.
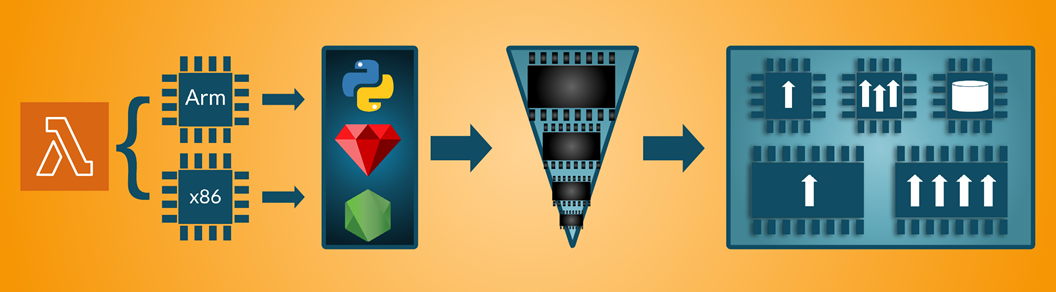
Figure 2 – High-level view of the experiment setup.
The Results
We crunched all of the data from the experiment and boiled it down to three overall figures: Performance, Cost, and Work/$ (which refers to how much more work or value you can get for every $ spent in Lambda). Note that this isn’t about the cost of worker threads, but rather the cost of actual processing accomplished.
Lambda functions powered by AWS Graviton2 result in better performance and lower cost in general, leading to significantly better work/$.

Figure 3 – Overall results (aggregate of all runtimes and workloads).
Let’s see what else we can find when we break down the results further.
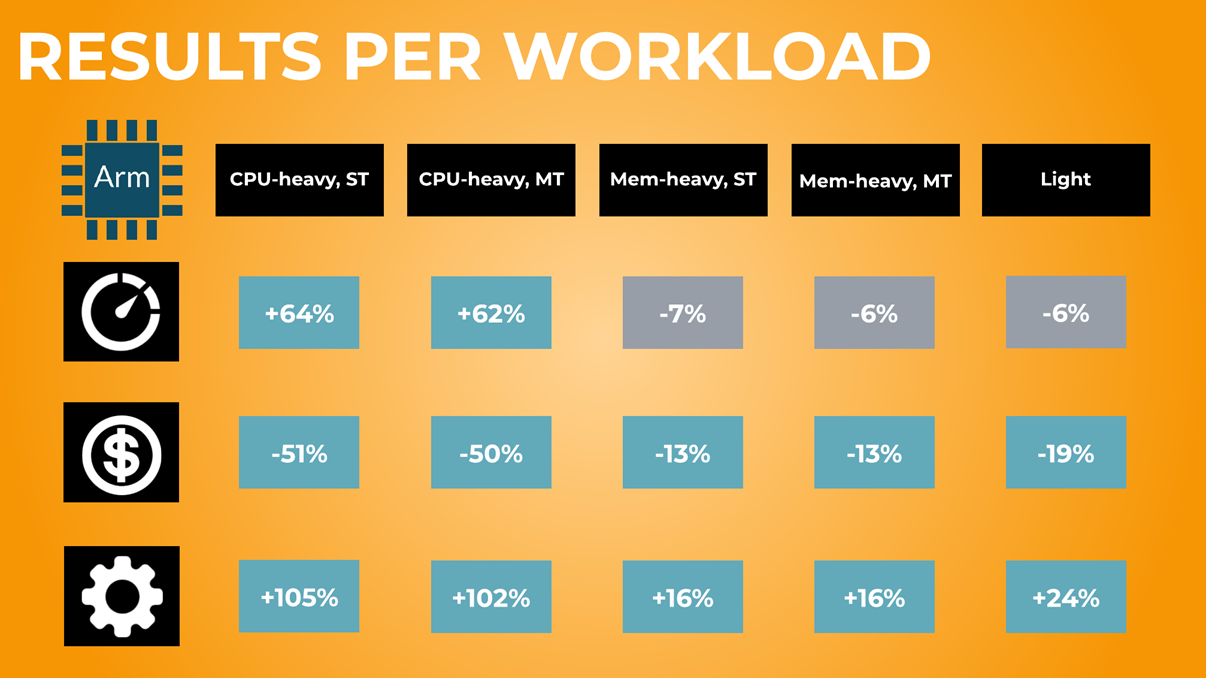
Figure 4 – Aggregating results based on workload.
Looking at the results in Figure 4 above, we can see some interesting variations when reviewing the results by average performance across multiple executions and aggregated by workload: extreme performance improvements in our CPU-intensive workloads, and slight performance deficits in memory-heavy and light workloads.
Cost and overall work/$ is still in favor of Arm, thanks to the cheaper pricing of Arm-based Lambdas.
As shown below in Figure 5, some runtimes benefit more than others. Python gets the highest performance and cost improvements, while Node gets the lowest. Still, a +44% improvement in work/$ (the worst result here) is nothing to scoff at.
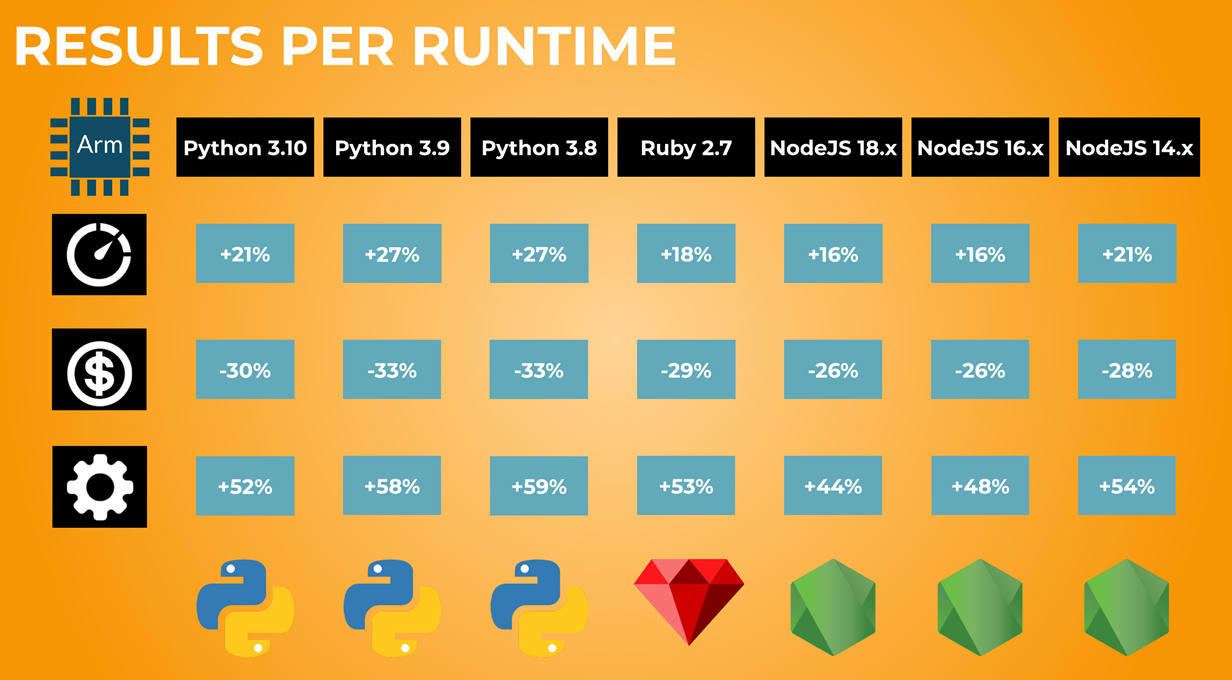
Figure 5 – Aggregating results based on runtime.
We get a more nuanced view of performance when we aggregate based on both workload and runtime. For example, we previously saw from the per workload results (Figure 4) that memory-heavy workloads show a slight performance decrease. In Figure 6 below, we see the impact of that performance decrease varies wildly depending on runtime. The memory-heavy workloads are less problematic for Python than NodeJS or Ruby.
It’s also worth noting that in every configuration, work/$ is still in favor of Graviton2.
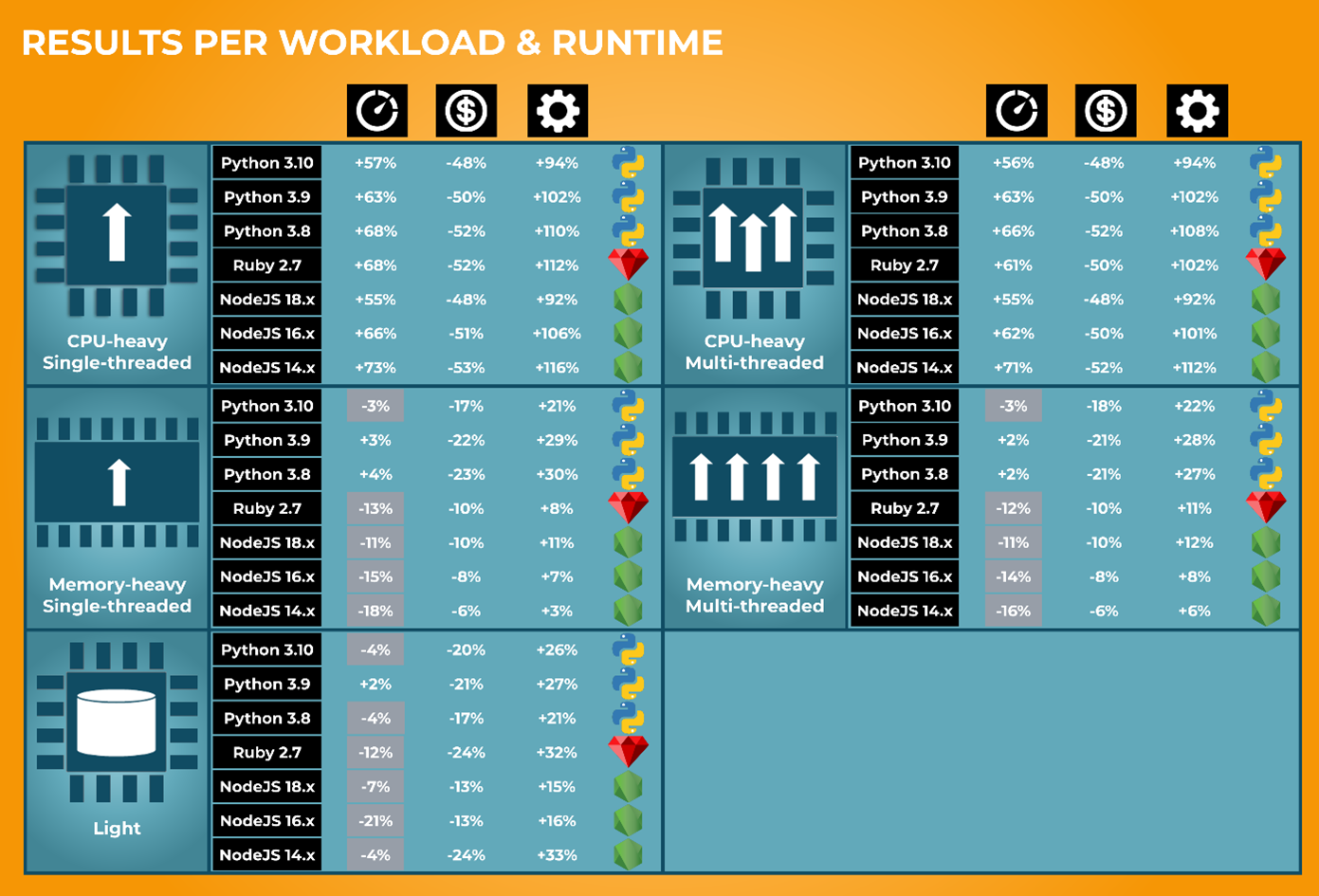
Figure 6 – Aggregating results based on workload and runtime.
Sustainable Computing
Graviton2 helps you spend less for the Lambda computing power you need, and Graviton processors are designed to be more energy efficient, using up to 60% less energy for the same performance compared to their x86 counterparts. For every Lambda workload you have running on the Arm architecture, you are friendlier not just to your corporate budget but also to the environment, reducing your carbon footprint.
Conclusion
From this experiment, we see the benefits of migrating from x86 to Arm-based AWS Lambda functions are almost universal. No matter what Lambda you have, you’ll probably gain performance while saving on cost. The magnitude of those benefits depends a lot on runtime (programming languages and their different versions) and workload, but you’ll almost always get a boost.
The sole exception is memory-heavy workloads. If your Lambda function is doing memory-heavy work (such as reading huge data files and operating on them in memory) and is latency-sensitive (for example, you need absolute performance), then you may be better off sticking with x86-based Lambdas.
That specific and probably somewhat-rare case aside, you can easily get an idea of how much money you’re leaving on the table by not migrating to Graviton2-based Lambdas, just by scanning the results in Figures 3-6 above.
If AWS Lambda forms a significant part of your cloud bill, it’s probably worth it to default to the Arm architecture for your Lambda functions whenever it’s supported. Overall, you’ll get better performance, lower costs, and more value for every dollar you spend, all while reducing your carbon footprint.
If you’re interested in applying this kind of performance and cost analysis to your own workloads (serverless or otherwise), contact Cascadeo to see how your workloads can be made more performant, efficient, cost-optimized, and stable.
.

.
Cascadeo – AWS Partner Spotlight
Cascadeo is an AWS Premier Tier Services Partner and MSP that specializes in cloud migrations, DevOps, and 24×7 managed services.