AWS Partner Network (APN) Blog
Empirical Approach to Improving Performance and Reducing Costs with Amazon Athena
By Michael Krauklis, Cloud Solution Architect – Innovative Solutions
By Shekar Tippur, Partner Solutions Architect – AWS
 |
| Innovative Solutions |
 |
Amazon Athena is a serverless interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL.
Amazon Athena provides an easy way to query data on Amazon S3 using standard SQL, thus providing a low barrier of entry to produce reports. Athena integrates with AWS Glue Data Catalog as a source for metadata.
Data stored in S3 can span gigabytes to petabytes. Querying such massive data poses unique challenges, and careful consideration of how data is stored and retrieved from S3 can boost the performance of an Athena query.
In this post, we present a use case-based approach to help evaluate these challenges and propose solutions to improve Amazon Athena query performance.
Innovative Solutions is an AWS Premier Tier Services Partner and certified AWS Well-Architected Partner specializing in cloud advisory, migration, optimization, modernization, and managed services. Their experienced team of cloud professionals works with customers to build cost-effective data solutions at scale using AWS analytics and data lake products, so you can achieve your business objectives.
Use Case
Amazon Athena users experiencing performance issues are often looking for directions on how to improve query performance.
In this approach, we have synthesized data to evaluate solutions to overcome problems that customers encounter while running Athena. The schema was designed to isolate common problems and easily measure query performance to contrast different data modelling configurations.
Using this schema, we were able to simulate long-running Athena queries taking tens of seconds if not minutes. The following sections outline experiment-based recommendations that could significantly improve real-world scenarios.
Performance Recommendations and Considerations
Depending on dataset, there may be multiple areas of opportunity to improve Amazon Athena performance:
- Avoid small files: Aggregate into larger files.
- Compression: GZIP compress.
- Partition projection: Leverage partition projection to overcome the Athena partition lookup penalty.
- Unpruned partitions: Avoid querying against partitions that do not exist.
- Parquet: Leverage a columnar file format.
- Tenancy structure: Break tenants into separate buckets/tables.
- Partition structure: Reorganize partitions.
Avoid Small Files
In this experiment, data in Amazon S3 was written as small objects, resulting in thousands of small (less than 1KB) files per partition. The experiment then evaluated performance between partitions containing numerous small files and partitions with a single aggregated file.
When querying against partitions with an aggregated file, the results showed a decrease in query times of 70-75%. We recommend consolidating smaller files to the AWS-recommended data size. Please refer to AWS documentation for details.
Use Compression
In this experiment, data was stored in raw JSON format. The experiment demonstrated the use of GZIP compression on the previously aggregated large files, and resulted in reducing query processing time further by an additional 10-20%.
An added benefit when using compression is the amount of data scanned by Amazon Athena decreased significantly, amounting to cost savings.
Partition Projection
Using partition projection, partition values and locations are calculated from configuration rather than read from a repository like the AWS Glue Data Catalog.
Two experiments were performed to test the hypothesis that the number of partitions returned by AWS Glue created a meaningful, quantifiable query penalty, and that partition projection could overcome this penalty.
The first experiment attempted to isolate the partition penalty by adding partitions over time without adding additional data. This test was executed two times: the first without partition projection and the second with.
Figure 1 – Table definition.
Partition projection was enabled by adding the following attributes to the table in the AWS Glue Data Catalog. For details about how to setup partition projection, follow the instructions in the AWS documentation.

Figure 2 – Partition metadata.
For the first experiment, partition pkey=0/skey=0 contained a single small CSV file with only five rows. The test application performed the following for 150 iterations:
- Perform the following query in Athena and record the execution time: select count(*) from athenatest where pkey=0 and skey=0
- Create 100 new partitions in an incrementally larger pkey (pkey=[1-150] & skey=[0-99]).
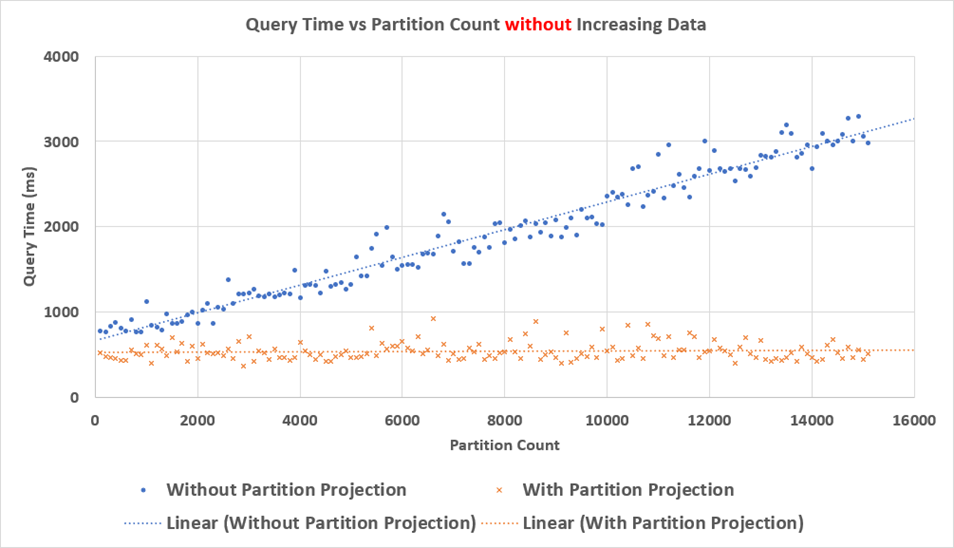
Figure 3 – Amazon Athena query performance.
As you can see, without partition projection Amazon Athena query times increased as the number of partitions increased.
Adding 15,000 partitions proportionally increased query times by approximately 2,200ms, showing that each additional 1,000 partitions increased Athena query time by approximately 150ms. With partition projection, however, no measurable performance penalty was seen as the number of partitions increased.
The second experiment followed the same methodology but also increased the amount of data with each partition added. In this experiment, each partition contained a single ~700MB compressed CSV file. The uncompressed file has 75 million rows and is ~1.5GB. For each iteration of the experiment, 100 partitions were created, each with the aforementioned file.

Figure 4 – Amazon Athena performance with larger dataset.
This experiment produced the following observations:
- There is a baseline cost for processing the compressed CSV file of approximately 18s.
- There is still a measurable increase in query time as the number of partitions increase which goes away with partition projection.
- Compared to the previous experiment, this experiment produced approximately the same ratio of increase-in-partitions to increase-in-query-time when not using partition projection (1000partitions:150ms).
Unpruned Partition Penalty
Partition pruning gathers metadata and “prunes” it to only the partitions that apply to your query.
It was also shown there’s an additional penalty for un-pruned partitions regardless of the data they contain. This applies to both partition projection and catalog-defined partitions. As such, care should be taken to appropriately prune but also to not create/project partitions needlessly.
In this experiment, the same no-increasing-data, no-partition-projection methodology was executed but without the partition-key-values specified in the “where” clause:
select count(*) from athenatest.
As you can see below, the query time without partition key in the “where” clause, resulting in a much steeper slope (roughly a 1 partition/1ms ratio).

Figure 5 – Amazon Athena performance without partition key in the “where” clause.
Use Columnar Storage Formats
Parquet is a columnar storage format that provides efficient storage and retrieval of big data. In this experiment, the partition projection experiments were expanded upon to include Apache Parquet instead of compressed CSV.
The resulting file size was ~450MB (vs ~700MB compressed CSV). To validate partition projection when using Parquet, an additional 50 iterations were executed without it to demonstrate the performance penalty.

Figure 6 – Amazon Athena performance using Parquet format.
The results further validated the performance benefit of using partition projection. They also showed a major query performance improvement when compared to queries against compressed the same data in compressed CSV.
It should be noted the query used (select count(*)) is particularly efficient in Parquet as this information is stored in the Parquet file’s footer, minimizing the amount of data retrieved. However, similar performance was seen when manually querying the dataset and specifying a column-based predicate to reduce the amount of data returned.
Using a columnar format such as Parquet can significantly improve performance and reduce costs.
Physically Separate Tenants
It’s generally recommended to separate tenants entirely into their own Amazon S3 bucket and AWS Glue Data Catalog table rather than including them in the partition structure.
The advantages of doing so include:
- Security: Physical tenant isolation reduces the possibility of accidental co-mingling of tenant data, and provides opportunity to create tenant-specific data access authorization.
- Performance: Physical separation will reduce the number of partitions created/projected per table. This also removes the need to keep the projected partitions synchronized as tenants are added.
Optimize Partition Levels
The partition structure should be chosen with the following considerations:
- Optimize partition pruning to create partition levels for columns commonly found in query “where” clauses.
- Don’t create/project unnecessary partitions.
- Optimize file size, removing partition levels to create larger files ideally 128MB or larger.
- Choose partition levels that can be specified with a range or have low cardinality.
Conclusion
Data presented in this post demonstrates the benefits of organizing data. Prioritizing the benefits outlined here, aggregating small files, and using a columnar format can provide the most value. With minimum effort, query time can be improved by over 70%.
Before implementing the partition structure, we highly recommend considering the data retention and future growth. Time spent in evaluating the storage needs will bear fruit as the data grows.
Please note that AWS has announced enhancements to Amazon Athena performance by adding support to AWS Glue Data Catalog partition indexes.
.

.
Innovative Solutions – AWS Partner Spotlight
Innovative Solutions is an AWS Premier Tier Services Partner specializing in cloud advisory, migration, optimization, modernization, and managed services.
Contact Innovative Solutions | Partner Overview
*Already worked with Innovative Solutions? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.