AWS Partner Network (APN) Blog
From Data Chaos to Data Intelligence: How an Internal Data Marketplace Transforms Your Data Landscape
By Subhasis Bhattacharya, Sr. Partner Solutions Architect – AWS
By Matt Hutton, VP, Cloud Engineering – Protegrity
By Koen Van Duyse, VP, Partner Success – Collibra
 |
In many of today’s organizations, data is stored across a range of sources and silos with inadequate data access, data governance, and data quality provisions.
This contributes to data consumers’ difficulty in finding, understanding, trusting, and accessing the data they need, and inhibits the effective use of data in business decisions.
Increasingly, the concept of an Internal Data Marketplace (IDM) is resonating with data organizations. An IDM is a secure, centralized, simplified, and standardized data shopping experience for data consumers.
IDM empowers data consumers to search a comprehensive data catalog and review data lineage and data quality benchmarks to gain the trust on data. IDMs simplify the data consumption experience by introducing a shopping cart experience; data consumers can easily add data sets to the shopping basket, check out, and consume data securely with just a few clicks.
IDM includes data governance and data catalogs, role-based access controls (RBAC), data profiling, and powerful contextual search to easily identify the most relevant data. The centralized data catalog and data discovery module acts as a single pane of glass to showcases the entire organization’s data landscape. Meanwhile, machine learning-based data quality scores highlight data quality benchmarks.
Integrated shopping carts and data protection features make it easy to add data sets to the shopping cart and get access to data securely based on RBAC and data access workflows.
Leveraging IDM architecture, customers can rapidly integrate and deploy functionality to access, evaluate, and rank all organizational data assets. The end result is a seamless data consumption experience for the end user, driving data democratization and data trust while mitigating data liability and maximizing return of investment (ROI) on data assets.
Internal Data Marketplaces are built with leading AWS services and partner solutions, such as:
- AWS Lake Formation for fine-grained access control.
- Collibra for data governance and centralized metadata repository.
- Protegrity for data security.
- Amazon S3 for data lakes.
- Amazon Athena for data consumption.
The flexible architecture of an Internal Data Marketplace allows customers to integrate into their own data sources, applications, and technologies. It also allows organizations to accelerate the time to secure, democratize, and facilitate data-driven decision making.
In this post, we will focus on key strategies and technologies of the IDM framework, which can be leveraged to build your own Internal Data Marketplace on Amazon Web Services (AWS).
Key Strategies for Building and Managing an IDM Framework
- Build an API-driven framework, identify and use a specific API integration strategy, and offer customers the ability to pick and choose solutions to integrate with their marketplace easily.
. - Integrate with a governed data catalog that enables users to search for and review data availability quickly. Catalogs that offer a text search based on business definitions, technical definitions, keywords, and data element names provide audiences the chance to leverage searches that are unique to their workflow and function.
. - Ensure your data can be trusted and easily viewed against data quality metrics so users can view the source, owner, uses of that data, and data quality metrics to see the overall rating of that data set. Establish an auto-generated data quality rules to monitor data objects continuously, automatically initiate remediation workflows, audit data, and generate reports to help build confidence and trust in the data.
. - Architect your marketplace to automate data access requests compliant with internal compliance policies around personally identifiable information (PII) and external regulations. Limit access to sensitive data sets and enable your organization to mitigate data exposure risks and further enhance users’ confidence in searching for and requesting access to data.
.
Users will know the data is identified correctly and access is provisioning based on compliant workflows. Protect sensitive data by utilizing format preserving tokenization or strong encrypt algorithm and key management services.
Below is the concept diagram that depicts a scenario where a user starts with a data catalog search (bottom middle) to discover data sets, reviews the data quality score, and adds the data sets to the shopping cart to get the data access based on RBAC.

Figure 1 – Concept diagram of IDM framework.
Key Components of IDM Framework
The Internal Data Marketplace framework is comprised of six building blocks:
(1) Data governance and (2) sensitive data protection are integrated with (3) data collection, (4) data ingestion, (5) data transformation, and (6) data storage and consumption as part of a loosely coupled architecture.
Data is registered, cataloged, and validated during data collection, and schema is referenced throughout the entire lifecycle of the data. Data is protected during collection, and data protection is maintained through the data lifecycle. An API-driven decoupled architecture supports a plug-and-play paradigm.
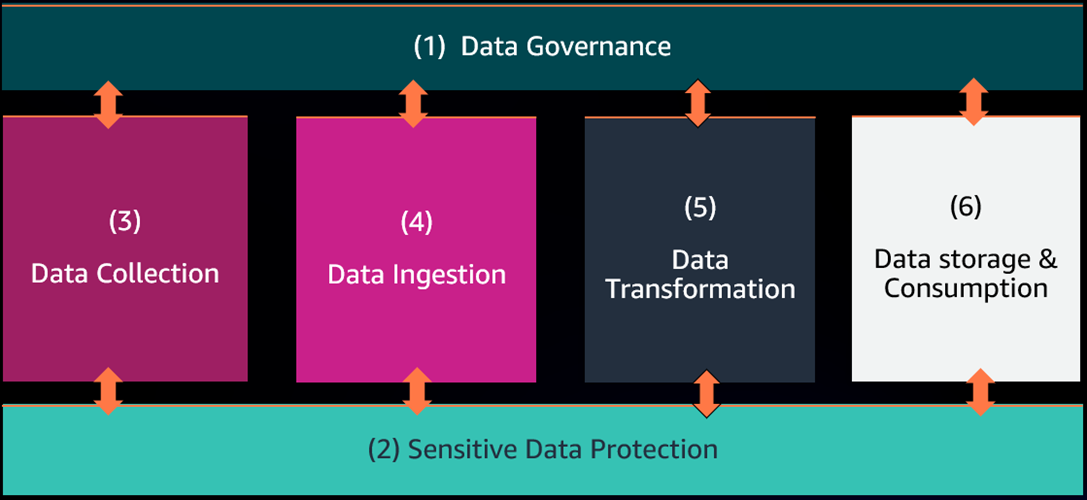
Figure 2 – IDM framework components.
Let’s deep dive into each component:
Data Governance
The IDM framework we’re showcasing here has utilized Collibra’s Data Intelligence Cloud, which is a scalable solution that tackles the complex needs to provide a seamless customer experience: data governance, data quality, privacy by design.
Deployed on the AWS Cloud or AWS GovCloud (US), Collibra deploys edge components in the customers’ tenant for profiling, classification, and lineage detection in a secure and scalable way.
Collibra’s Data Intelligence Cloud includes products such as:
- Data Governance helps enterprises understand and find meaning in their data.
- Data Catalogs empower business users to drive value by quickly discovering and understanding their data.
- Data Lineage provides complete transparency into data by mapping relationships to show how data flows from system to system, and how data sets are built, aggregated, sourced, and used.
The below diagram is an example of the flow of data from ingestion through to visualization by consumers.
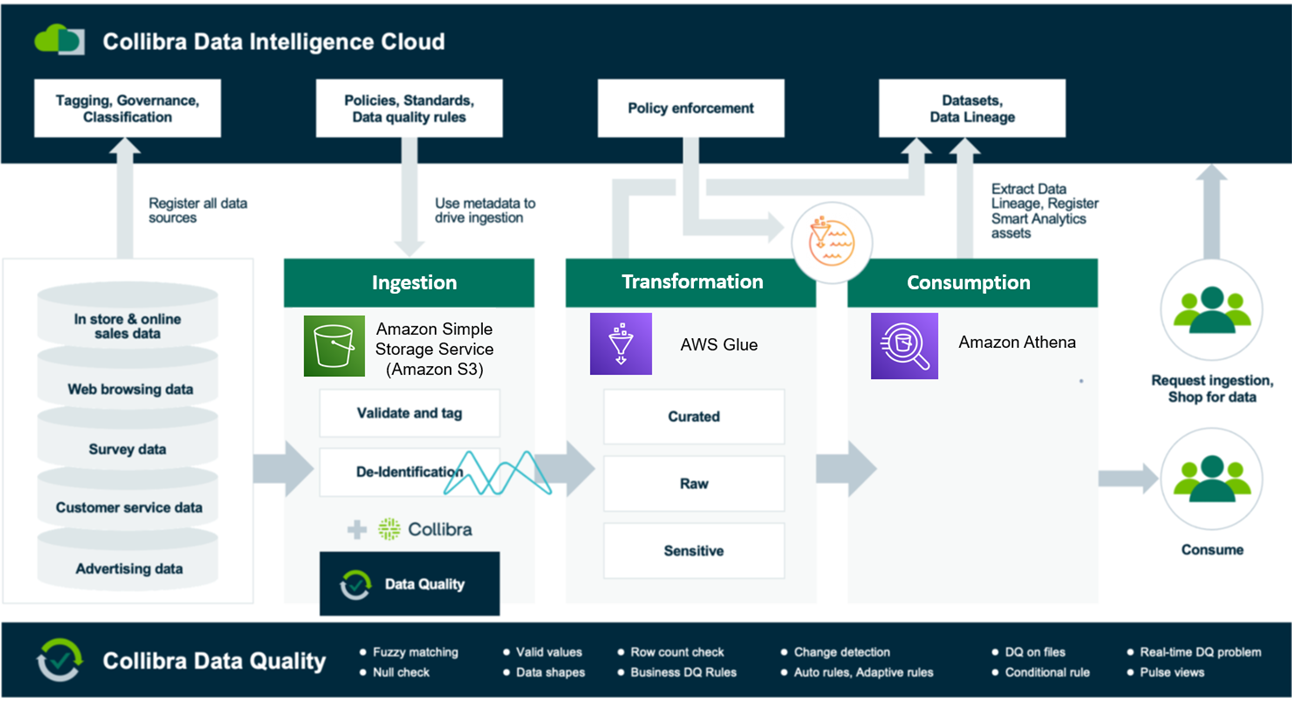
Figure 3 – Collibra’s data intelligence workflow.
Data Catalog and Data Governance
Collibra first builds a data source catalog that organizes all available data sources by domain. With each data source, rich information around the data, domain context, and roles get added. From this data source catalog, data consumers can choose what data they want to use. This means that rather than a “lift and shift” to the cloud, we’ll have data consumers request data to be ingested by use case.
From here, the context gets stored with the data usage: project code, how the data should be delivered, where the data will end up, business process requesting the data, and so on.
Establishing a common data language with a business glossary, and making the information easily accessible to every user, enables faster adoption. The Collibra suite also includes a stewardship and policy manager, so users can create, review, and update data policies across your organization.
Sensitive Data Protection
In the IDM framework, data access is secured with AWS Lake Formation and protected using Protegrity, whose data protection platform allows organizations to work with protected data across enterprise on-premises and cloud environments. This is a critical requirement for regulated organizations dealing with PCI and PHI data, and to address privacy-preserving regulations such as GDPR and CCPA.
Pseudo-anonymization using data tokenization is a popular technique for protecting data privacy. Data is de-identified, and clear text values that directly or indirectly identify an individual are replaced with tokens. These tokens can be exchanged by an authorized user to reveal the actual value. If tokenized data falls into the hands of an unauthorized user or released because of data breach or ransomware, the sensitive data is fundamentally protected.
Data is typically protected in the source, which enables protected data to securely move to downstream analytics systems or the IDM framework. Data authorization policies are centrally managed within the organization, and access policies are enforced using Protegrity’s software integration with services such as Amazon Athena, Amazon S3, and Amazon Redshift.
This allows authorized users to unprotect data on-demand based on their access privileges. The IDM framework integrates Collibra and Protegrity so approval workflows can automate creation of the appropriate user access policies.
The following table shows an example of working with protected data. The first and second column show sensitive data in the clear and the equivalent of the data in protected form. Columns three and four illustrate what different users can access based on their role, including no data access, masked data, or data in the clear.
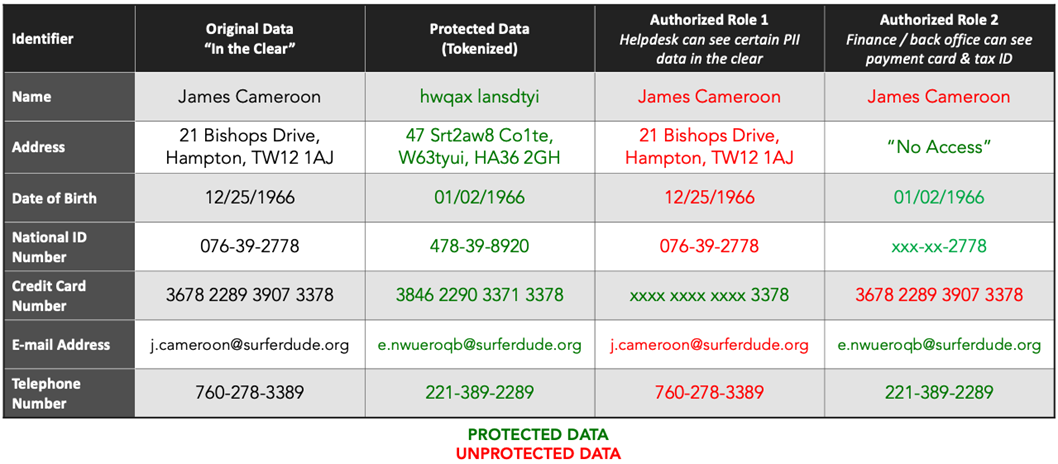
Figure 4 – Protegrity data protection example.
Protegrity’s data tokenization is length, type, and format-preserving, which makes it easy to substitute tokens without violating field constraints. Protegrity software runs inside or alongside software applications, databases, and cloud-native deployments, providing the ability to protect or unprotect data based on a user’s access and authorization.
Protegrity provides high-performance integrations with Amazon Redshift and Amazon Athena. This allows authorized users to unprotect data directly from any tool that can issue SQL queries.
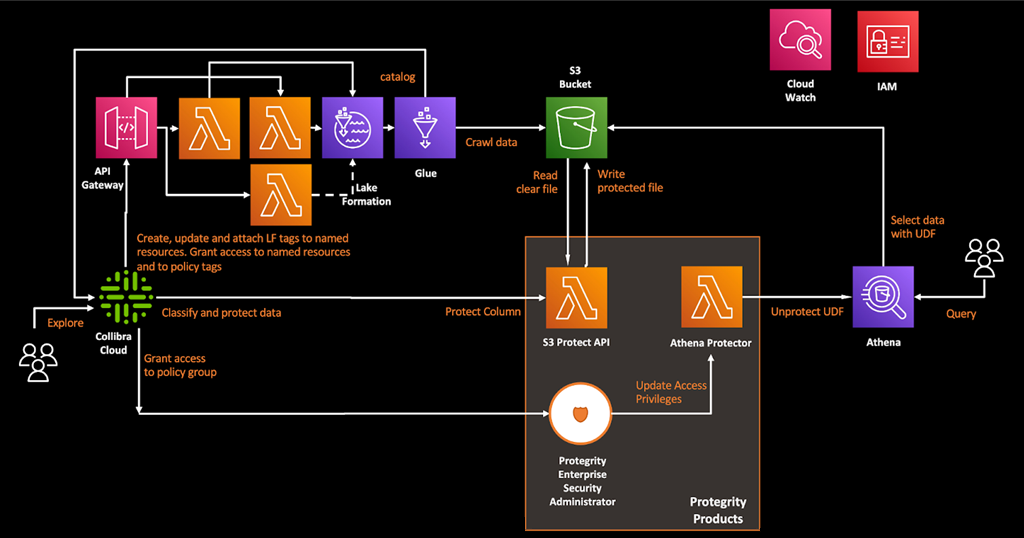
Figure 5 – Schematic overview of Collibra calling AWS Lake Formation and Protegrity APIs.
Data Collection
The IDM framework enables real-time, near real-time, and batch mode data collection from diverse sources. For real-time data collection, IDM utilizes Amazon Kinesis.
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so users can get timely insights and react quickly to new information. It enables users to process and analyze data as it arrives and respond instantly, instead of having to wait until all data is collected before the processing can begin.
Amazon Kinesis is fully managed and runs streaming applications without requiring end users to manage any infrastructure.
Data Ingestion
The IDM framework’s data ingestion module supports new schema registration, schema validation, data contract validation, and data classification, which is utilized to identify sensitive data and protect during data ingestion.
The data ingestion module is implemented with AWS Lambda functions, and AWS Partner solutions can be integrated with IDM framework as well.
Lambda is a serverless, event-driven compute service that allows users to run code for virtually any type of application or backend service without provisioning or managing servers. It can be triggered from over 200 AWS services and software-as-a-service (SaaS) applications.
Data Transformation
The purpose of the data transformation module is to transform, clean, and enrich data for easy consumption. It can provision data structuring, aggregation, normalize/de-normalize, data cleansing/filtering, and data integration/hydration. The IDM framework utilizes AWS Glue for data transformation.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. It provides all of the capabilities needed for data integration so users can start analyzing data and putting it to use in minutes instead of months.
Data Storage and Consumption
The IDM framework utilizes Amazon S3 for storage and Amazon Athena for data consumption.
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases: data lakes, websites, cloud-native applications, backups, archive, machine learning, and analytics.
Amazon S3 is designed for 99.999999999% (11 9’s) of durability and stores data for millions of customers all around the world.
Amazon Athena is ideal for quick, ad-hoc querying but it can also handle complex analysis, including large joins, window functions, and arrays. Amazon Athena is highly available and executes queries using compute resources across multiple facilities and multiple devices in each facility.
Amazon Athena uses S3 as its underlying data store, making data highly available and durable. It automatically executes queries in parallel, so most results come back within seconds. Protegrity provides high-performance integrations with Amazon Redshift and Athena, allowing authorized users to unprotect data directly from any tool that can issue SQL queries.
IDM Reference Architecture
In the IDM reference architecture shown below, data is collected in real-time utilizing Amazon Kinesis and AWS Lambda functions are utilized as part of data consumption layer. All metadata are centrally managed in Collibra, while AWS Lake Formation and Protegrity metadata are updated utilizing API calls for sensitive data protection functionality.
Amazon S3, AWS Glue, and Amazon Athena are utilized for data storage, transformation, and consumption.
IDM provides the flexibility to integrate customers’ preferred tools with the framework; for example, AWS Step Functions can be replaced with an orchestration service such as Apache Airflow.
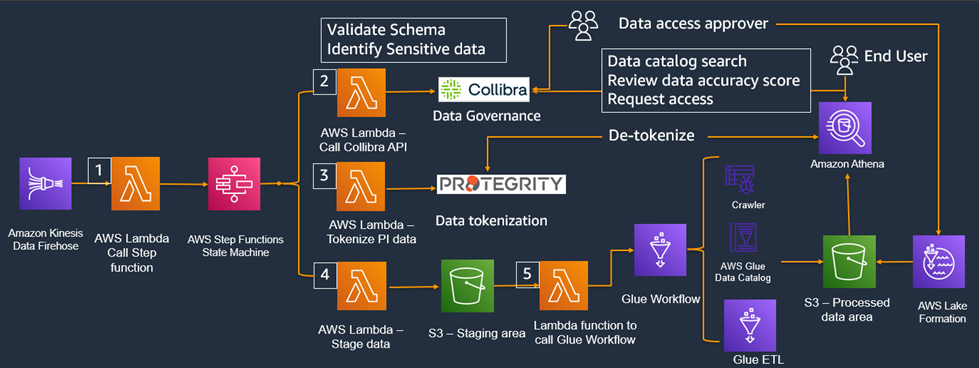
Figure 6 – IDM reference architecture.
The data persistence workflow is as follows:
- The first AWS Lambda function intakes data from Amazon Kinesis and calls an AWS Step Function to invoke subsequent Lambda functions.
- The second Lambda function calls Collibra API to perform three functions:
- Validate the schema
- Create a new schema if it doesn’t exist
- Identify sensitive data based on data classification code
- The third Lambda function makes API calls to Protergity to tokenize data during data ingestion.
- The fourth Lambda function writes data to staging area in an Amazon S3 bucket.
- The fifth Lambda function picks up files created in the S3 staging area and calls AWS Glue workflow for data transformation, and then stores curated data in the S3 data lake.
The data access workflow works like this:
- End users, in the top right corner of the reference architecture, start by searching the data catalog, then reviews the data quality score, and (based on findings) adds the data sets to the basket and checks out with FROM – TO date and justification for data access.
- User access request is routed to the data access approver, and the approval process is automated or supervised based on the sensitive nature of data access request. Collibra makes the API call to AWS Lake Formation and Protegrity data catalog to update the fine-grained access control and role-based access control to provide sensitive and non-sensitive data access
Users are able to access the data from Amazon Athena within seconds of approval. All access requests and approval are stored for audit purposes.
Conclusion
Data is the most valuable asset for data-driven organizations, and the Internal Data Marketplace (IDM) framework we have outlined in this post is designed to unleash the data potential.
IDM empowers users to consume data easily with Collibra’s data shopping experience, securely with Protegrity’s integrated data protection platform, and seamlessly with Amazon Athena’s federated query service.
To learn more, check out the Collibra and Protegrity websites, and read this TDWI report: The Role of Modern Data Governance in an IDM Framework.