AWS Partner Network (APN) Blog
How WANdisco LiveData Migrator Can Migrate Apache Hive Metastore to AWS Glue Data Catalog
By Paul Scott-Murphy, Chief Technology Officer – WANdisco
By Roy Hasson, Principal Product Manager – AWS Glue / AWS Lake Formation
 |
WANdisco is the LiveData company and an AWS ISV Partner with the Migration Competency that provides technology and software products that are used to simplify and automate the migration of big data to the cloud.
In this post, we’ll explain the challenges of migrating large, complex, actively-used structured datasets to Amazon Web Service (AWS), and how the combination of WANdisco LiveData Migrator, Amazon Simple Storage Service (Amazon S3), and AWS Glue Data Catalog overcome those challenges.
Big datasets have traditionally been locked on-premises because of data gravity, making it difficult to leverage cloud-native, serverless, and cutting-edge technologies provided by AWS and its community of partners.
The increasing capabilities of AWS, along with cost reductions and greater operational capacity, mean the commoditization of large-scale cloud services for storage and analytics is driving an inevitable migration of these workloads to the cloud.
There are unique challenges faced when planning the migration of large-scale datasets and analytics workloads, including:
- Impact to business operations that depend on any on-premises analytics environments. As data sizes and volumes increase, the time it takes to migrate increases operational risk to the business.
- Uncertainty of scope, complexity, and cost of migration. By definition, every new migration is being planned for the first time and can introduce unforeseen challenges and risks.
- New and different capabilities of the target environment. These present an opportunity to modernize, but also increase the learning curve as code and processes are refactored to work in the new environment.
Why Metadata is So Important
One of the critical capabilities of any analytics platform is how it manages technical and business metadata, which is the information that describes the data against which analytics operates.
Legacy platforms like Apache Hadoop use Apache Hive to store and manage technical metadata, describing data in terms of databases, tables, partitions, and more.
The metadata stored in Apache Hive is valuable information for any organization that wants to democratize access to data. Without the ability to discover, prepare, and combine datasets with an understanding of their structure, analytics at scale is an impossible task, and datasets that cannot be used have no value.
An important requirement when modernizing legacy analytics workloads for the cloud is to keep business operating as normal by taking advantage of the metadata stored on-premises.
Moving data to the cloud, perhaps by migrating HDFS data to Amazon S3 using WANdisco LiveData Migrator, is only the first step. You must also migrate metadata so users can discover, understand, and query the data.
The Power of AWS Glue Data Catalog
The AWS Glue Data Catalog is a persistent, Apache Hive-compatible metadata store that can be used for storing information about different types of data assets, regardless of where they are physically stored.
The AWS Glue Data Catalog holds table definitions, schemas, partitions, properties, and more. It automatically registers and updates partitions to make queries run efficiently. It also maintains a comprehensive schema version history that provides a record for schema evolution.
A cloud-native, managed metadata catalog that’s flexible and reliable, AWS Glue Data Catalog is usable from a broad range of AWS native analytics services, third parties, and open-source engines. AWS maintains and manages the service so you don’t need to spend time scaling as demands grow, responding to outages, ensuring data resilience, or updating infrastructure.
Migration Challenges and Strategies
As with any migration, having a plan will guide the effort and ensure success. There are fundamentally two migration strategies: a one-off “Big Bang” migration, or an incremental migration that can take place over time.
A Big Bang migration strategy establishes a clear delineation, or gate, between the original “before” and target “after” states, and requires that all components are in the same state to properly function as a system. The overall system is not fully functional unless all resources are in the “before” state, or all resources are in the “after” state.
The downsides of a Big Bang migration strategy include:
- Extremely high risk of failure. By definition, Big Bang migrations include a point of no return, where the choice to move workloads that create or change data or metadata to the target environment prevents rolling back to the original environment without the potential for data loss.
- Significant impacts to business operations. Without the ability to migrate data and metadata over time, a once-off migration requires several planned system outage windows. This is particularly challenging for big data workloads, because of the time it takes to move hundreds of terabytes and petabytes of data.
- High costs. Big Bang migrations need significant up-front planning that must anticipate and address all known and potentially unforeseen issues in advance.
An incremental strategy provides a gradual migration of system components over time in a way that allows them to be used throughout the process, potentially with some in their original state, and some in their target state, without degrading overall system availability and functionality. Those components don’t all need to move to the target state at the same time for the system as a whole to be functional.
Incremental migration is not without its set of challenges, too. The primary challenge being the need for a technical solution to continuously migrate changing data and metadata without disrupting business systems and users’ work. Without this, an incremental migration will require outage windows and prolonged disruption to business operations.
Modernizing Analytics Through Migration
An ideal migration solution should:
- Implement an incremental strategy.
- Not disrupt source analytics and business systems.
- Not impose significant extra load on source systems during migration. Rather, it should reduce potential impact to business operations.
- Include both data and metadata.
WANdisco provides the LiveData Cloud Services platform to migrate changing (“live”) data and metadata from Apache Hadoop, Hive, and Spark environments to the public cloud.
From its inception, LiveData Migrator has supported migrating data stored on-premises to Amazon S3. Learn how to get started quickly in the AWS Prescriptive Guidance using WANdisco LiveData Migrator, and learn how it enabled a multi-petabyte migration for GoDaddy.
An incremental migration strategy from an Apache Hive metastore residing on-premises to AWS Glue Data Catalog is now possible with a few simple steps.
LiveData Migrator eliminates complex and error-prone workarounds that require one-off scripts and configuration in the Hive metastore. It integrates with a wide range of databases used by the Hive metastore, making migration simple and painless.
This means the same strategy that has proved successful for organizations like GoDaddy when migrating hundreds of terabytes of business-critical data, can now be applied to metadata as well. This simplifies big data migrations, greatly reduces business disruption during migration, and accelerates time to insight.
Getting Started
Migrate from an Apache Hive metastore to AWS Glue Data Catalog in two simple steps:
- Define your target S3 bucket used for table content and your AWS Glue Data Catalog for metadata.

Figure 1 – Define an AWS Glue Data Catalog target.
- Select the source databases and tables you want to migrate and start the migration.

Figure 2 – Select metadata to migrate.
Once the initial migration completes, LiveData Migrator will continue to replicate as new metadata is created or updated at the source.
Once both data and metadata are on AWS, the AWS Lake Formation service can be used to define and enforce fine-grained access controls.
Also, integrated analytics services such as Amazon EMR running Apache Hive, Spark, and Presto, Amazon Redshift, and Amazon Athena can query the data with no additional configuration.
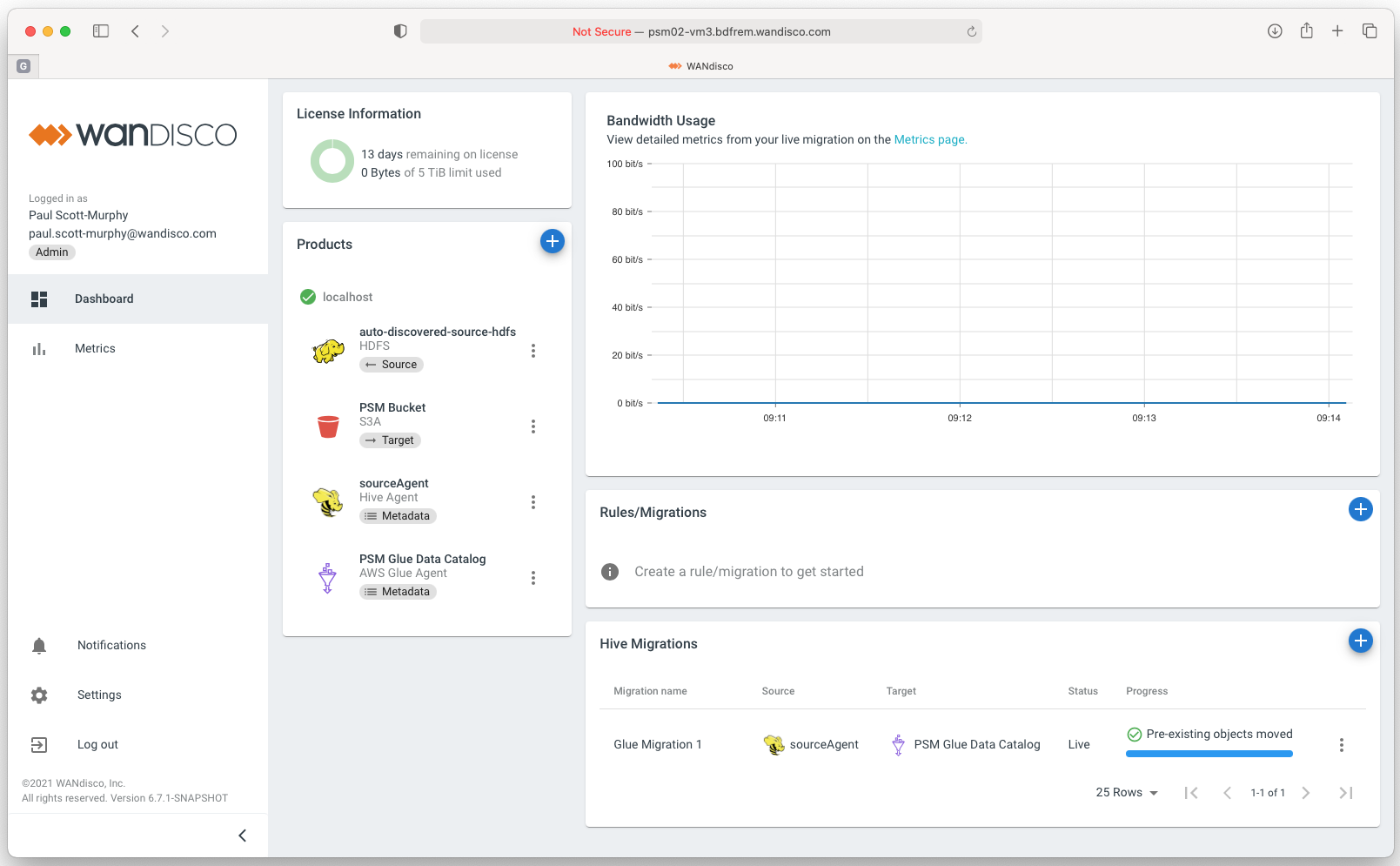
Figure 3 – Monitor live migrations.
Summary
Modernizing an on-premises analytics platform takes time, effort, and careful planning. Using WANdisco LiveData Migrator companies can easily and quickly migrate the two most important aspects of the platform: data and metadata.
Continuous replication of data and metadata allows companies to maintain normal business operations on-premises while taking advantage of AWS-native analytics and machine learning services. This enables bursting time sensitive workloads to the cloud, supporting new use cases, and building new products that improve customer experience and increase top-line revenues.
AWS Glue Data Catalog provides a unified view into datasets available both on-premises and on AWS, enabling data analysts, data engineers, and data scientists to quickly discover and use data.
You can get started with WANdisco LiveData Migrator on AWS Marketplace, and use it for selectively migrating data and metadata at scale, without business disruption, even while those datasets continue to change.
Related Resources
- LiveData Migrator documentation
- WANdisco support community
- WANdisco LiveData Migrator demonstration (video)
.

.
WANdisco – AWS Partner Spotlight
WANdisco is an AWS Migration Competency Partner that is shaping the future of data infrastructure with its LiveData cloud services, making data always available, always accurate, and always protected.
Contact WANdisco | Partner Overview | AWS Marketplace
*Already worked with WANdisco? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.