AWS Partner Network (APN) Blog
How WP Engine Delivers Increased Uptime When Scaling Websites with AWS
By Ethan Kennedy, Product Manager at WP Engine
 |
One of the key value propositions WP Engine makes to customers is high availability of websites (uptime), regardless of the stress those sites may encounter.
Delivering a performant, reliable, digital experience, even under heavy load, is key to customers’ success. We are constantly evaluating the latest cloud technologies to continuously improve this experience.
WP Engine is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Digital Customer Experience Competency. Our WordPress Digital Experience Platform gives enterprises and agencies the agility, performance, intelligence, and integrations they need to prepare for and handle heavy traffic loads.
A common cause of website failures is spikey traffic. More specifically, this applies to websites that are unprepared for spikey traffic.
An unexpected spike in traffic can occur for a variety of reasons, but when it does and a site isn’t prepared for it, this can cause downtime, slow performance, and a negative experience for site visitors and/or customers.
In this post, I will explore our learnings at WP Engine while leveraging Amazon Web Services (AWS) technologies to address the not-so-new issue with spikey web traffic.
In doing so, our team was able to develop a new product called Dynamic Web Scaling (DWS) that WP Engine customers use to quickly add web resources when their site is experiencing a planned or unplanned increase in expected traffic.
The requirements we had for the DWS product were:
- Scale quickly: We didn’t want customers to feel stuck while waiting for resources to become available when they needed to scale.
- Speed and reliability: Dropping traffic to customers’ sites or sacrificing performance during a scale-up event were unacceptable options.
- Cost consistency: We wanted to ensure billing for customers remained consistent, with no surprise charges or unexpected fees.
Weighing the Options
There were a few options we considered before deciding on one that would be flexible enough to deliver the scaling we wanted and technically feasible enough to go to market quickly.
The options we worked through included leveraging a single container implementation, using distributed architecture, or something else that was container-based.
A single server implementation was the core implementation for our hosting product, but unfortunately this implementation also presented challenges with scaling while serving traffic. Changing an instance type requires spinning down the instance, which would violate our requirement of a reliable, performant platform during scaling operations.
Containers, depending on the implementation, would add some amount of flexibility, but still didn’t meet all the requirements we needed.
Maintaining all the functionality of our stateful application (WordPress) without sacrificing performance on the backend was a large challenge, and not one we had chosen to tackle as part of this initiative.
The other option, something like LXD, would allow for seamless scaling but also limit the resources to the instance it was living on. This would have made our implementation cost-prohibitive, and it would have limited the ability to scale our instances.
The last option, and the one we ended up going with, was a distributed architecture approach. This allowed us to offer scaling of single layers without breaking up our model approach.
We already had a distributed architecture implementation of our product, in order to offer cross-AWS Availability Zone redundancy to our customers, so iterating on that platform made the most sense in addition to the reasons listed above.
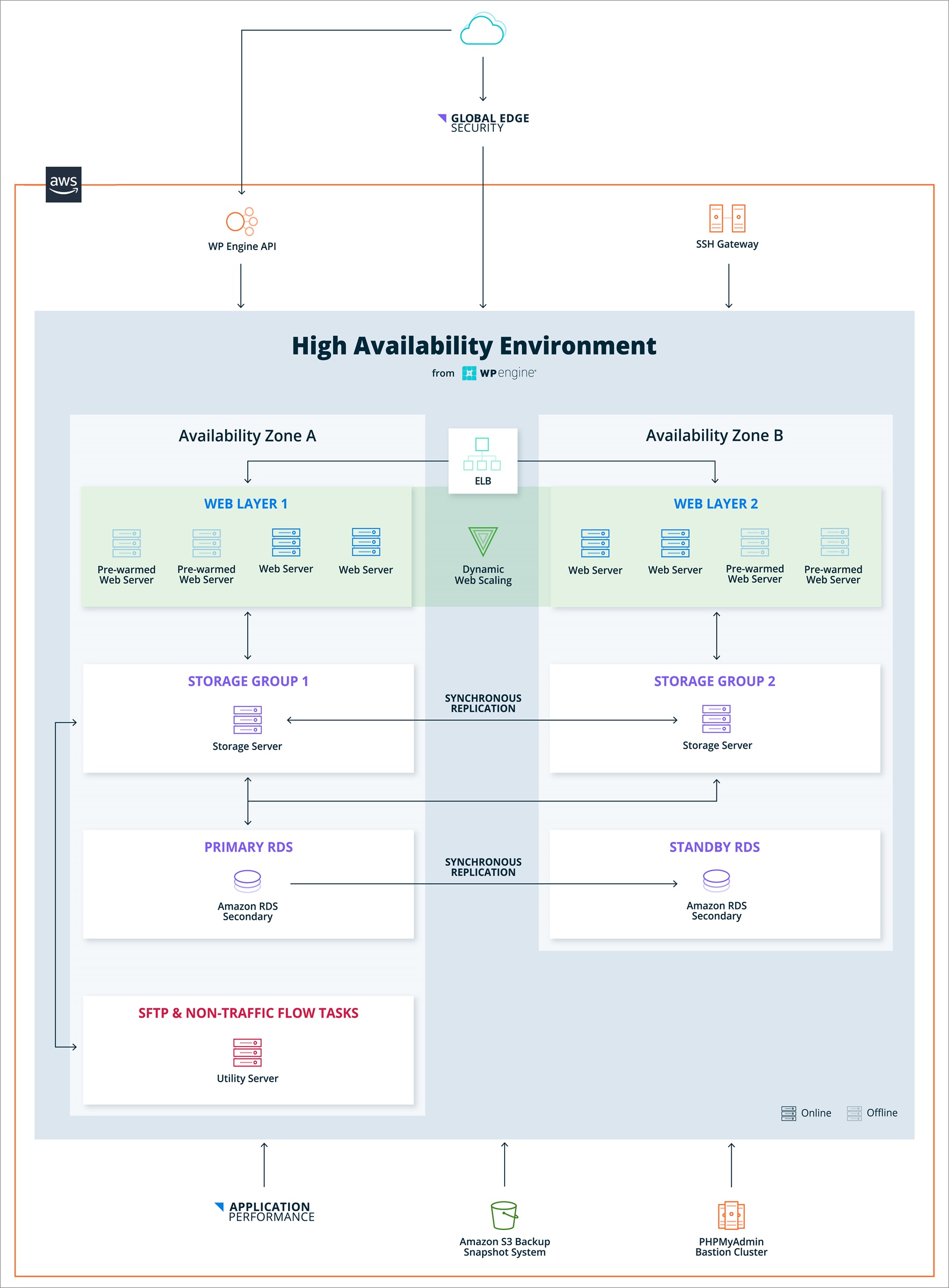
Figure 1 – Technical breakdown of high availability distributed architecture solution.
Successful Scaling for Customer Uptime
Our distributed architecture is split into three layers:
- Web layer powered by Amazon Elastic Compute Cloud (Amazon EC2).
- Storage layer also powered by Amazon EC2.
- Database layer, which leverages Amazon Relational Database Service (Amazon RDS) instances, and AWS’s active passive failover to accomplish cross-region replication.
In our experience hosting enterprise-grade WordPress sites, the web layer—that is, the servers that actually render PHP code and serve dynamic requests—is what often ends up being the bottleneck when traffic increases.
In some cases, the other layers need to be scaled as well, but more often than not we hit a bottleneck in the web layer well before the database or file system becomes an issue.
After some consideration, the implementation we decided on was to have multiple Amazon EC2 instances available, but disabled. This implementation allowed us to have those instances ready to go quickly without having to worry about the challenges of a cold start with our robust platform configuration.
The implementation was also managed by a series of AWS Lambda functions and a core state machine that allowed us to make decisions based on the current state of scale for the cluster.
The state machine made it possible to ensure customers were in a state where scaling needed to take place, and were not scaling up or down during momentary traffic spikes in either direction. This was possible through Lambda, but it was also cost-prohibitive based on the delays built into the system, where state machines are billed per action rather than on time spent running. The state machine is core to preventing things like flapping that would otherwise incur a potentially negative customer experience.
Depending on metrics, we initiated during a scale up, there could be a point where the fluctuation was large enough to straddle the scale up/scale down line, and introduce more risk for customers to be in a non-ideal state.
With the state machine in place, we were able to ensure that traffic was behaving as expected without worrying about the cost of a long running Lambda script.
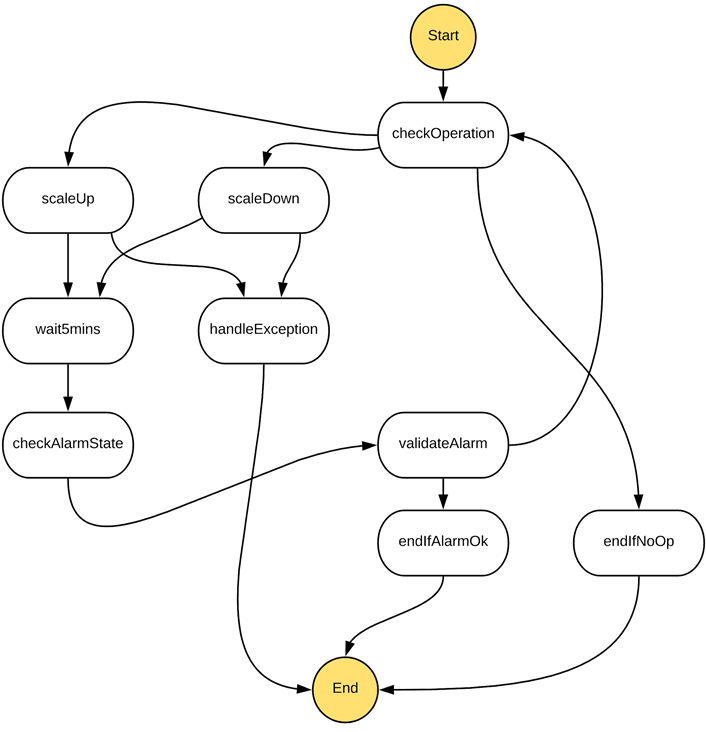
Figure 2 – State machine powering the core operations of Dynamic Web Scaling.
The core of our scaling operation began with validation of the information being passed in. This allowed us to add alarms for any metrics we wanted, and allowed us flexibility in triggering scaling based on any event we deemed necessary.
Currently, we’re working with CPU alarms from Amazon CloudWatch that trigger when our CPU is above or below a certain metric. To learn more, see the documentation on Using Amazon CloudWatch Alarms.
The next step was to actually initiate the scaling up or down based on the output of the previous step. The ‘scaleUp’ or ‘scaleDown’ triggers execute a Lambda that removes or adds two web nodes to the Auto Scaling Group for that cluster.
This operation always functions in two in order to maintain cross-Availability Zone functionality for our customers. The scale-up thresholds are 200 percent of the nodes the offering has by default. We were able to scale down to 50 percent or the lowest number of nodes that allowed us redundancy but that was not below 50 percent.
Next, we allowed time to pass before revalidating if we were in an alarm state. Adding resources on small spikes could incur costs if that happened too often, so we wanted to make a decision to ensure customers were indeed in need of the resources available. Our scaling thresholds are conservative enough to allow a customer’s site to continually be served under normal traffic conditions.
After we allowed extra time to pass, we then validated the alarm was either still active or in a reasonable state. If we were out of the scale up or down threshold, we left the customer’s cluster as-is until another scaling threshold was met. Otherwise, we restarted the whole process again to add or remove resources from the customer’s environment until they were within the thresholds for normal performant site operation.
All of this action is transparent to the end user thanks to the Elastic Load Balancing (ELB) that everything runs behind. Customers are able to scale up or down based on the demand of their application, without interaction from anyone on our side. In the past, this would have required manual intervention by at least three people.
The ability to keep customers online during any traffic spikes they might incur, and doing it all for them in the background, is the true value of what we were able to deliver thanks in large part to our partnership with AWS.
Video: WP Engine is an AWS Competency Partner (1:47)
Hear from Lisa Box, VP Strategic Alliances and Business Development, as she shares her insights on how the AWS Digital Customer Experience Competency helps WP Engine meet the needs of its customers.
Summary
The AWS platform allows WP Engine to automate common tasks that would otherwise require manual intervention, and an overall bad customer experience.
With AWS, we’ve been able to make intelligent decisions to offer customers the best experience while maintaining a cost-effective solution.
Our Dynamic Web Scaling (DWS) solution ensures end users that when their site is hit with a wave of spikey traffic, they can take advantage of it rather than worry about whether their site will stay up.
Learn more about how WP Engine uses AWS to help customers manage web traffic at scale.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.

.
WP Engine – APN Partner Spotlight
WP Engine is an AWS Digital Customer Experience Competency Partner. Its WordPress Digital Experience Platform gives enterprises and agencies the agility, performance, intelligence, and integrations they need to drive their business forward faster.
Contact WP Engine | Solution Overview
*Already worked with WP Engine? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.