AWS Partner Network (APN) Blog
Migrating Data Warehouse Workloads from On-Premises Databases to Amazon Redshift with SnapLogic
By Sriram Kalyanaraman, Product Manager at SnapLogic, Inc.
By Saunak Chandra, Sr. Solutions Architect at AWS
![]() Amazon Redshift is a fast, scalable, easy-to-use data warehouse solution built on massively parallel processing (MPP) architecture and columnar storage. It’s the most suitable solution for analytical workloads, and many organizations choose Redshift for running analytics on data requiring enhanced throughput and concurrency.
Amazon Redshift is a fast, scalable, easy-to-use data warehouse solution built on massively parallel processing (MPP) architecture and columnar storage. It’s the most suitable solution for analytical workloads, and many organizations choose Redshift for running analytics on data requiring enhanced throughput and concurrency.
Business analysts and data scientists collect data from various systems, build pipeline for orchestration, and finally load the data into Redshift before doing any analysis.
SnapLogic is an easy-to-learn data integration tool that allows business analysts and integration specialists to accomplish data ingestion from various sources into Redshift. The SnapLogic Redshift Bulk Load Snap (pre-built connector) is part of the SnapLogic Intelligent Integration Platform and enables loading large volumes of data rapidly into Redshift all at once.
In this post, we’ll cover some features of SnapLogic that let you migrate schema and data using a simple and easy-to-learn visual designer. We’ll also describe the synchronization feature of SnapLogic that enables you to transfer data on an ongoing basis after the initial migration.
SnapLogic is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Data & Analytics Competency.

Background
Many organizations run transactional workloads on-premises with databases such as MySQL. When they run analytical queries involving complex joins and aggregations on the same transactional databases, they often experience poor performance due to the high throughput requirement of analytical workloads that become contentious with the transactional processing.
Organizations need better performance for their analytical workloads, which is something only a dedicated data warehouse application can provide. This is why many businesses are moving their data to Amazon Redshift, a cloud data warehouse optimized for analytics.
One of the biggest challenges when moving an on-premises MySQL database to a cloud-based one such as Redshift is performing a bulk data migration. During this bulk data migration, you have to be mindful of:
- Conversion of the table schema with the associated data types for the table columns.
- Conversion of database-native stored procedure.
- Transferring data from the source to the target and pointing your analytical workload to the target system.
The last challenge listed above is particularly important because, after turning on the new system followed by the initial extraction, there’s a need to synchronize any new transactions that come through.
Typically, migrations are done through traditional extract, transform, load (ETL) tools. Not only are the traditional approaches onerous, however, in that they force you to spend considerable time on writing code and debugging software, but they also require specialized skills. What’s more, the risk of schema errors is higher in these settings. Such approaches to bulk data migrations are expensive and time-intensive.
You can automate the migration process with an Integration Platform as a Service (iPaaS) solution like SnapLogic. This reduces the cost and effort of moving large volumes of data while closing the skills gap.
SnapLogic Designer
The screenshot in Figure 1 shows the SnapLogic Designer where you build the pipeline by dragging various widgets specific to Amazon Redshift. Users follow this sequence of steps to build an integration pipeline in SnapLogic:
- Log into SnapLogic Designer.
- Search for the Snap you are looking for.
- Drag-and-drop Snaps onto the canvas to build the integration pipeline.
Along the way, you can easily configure various options for Snaps, and the configuration for the Redshift Bulk Load Snap is shown later in this post.
Alternately, if a pre-built pattern pipeline is available, you can simply re-use it to complete the integration.
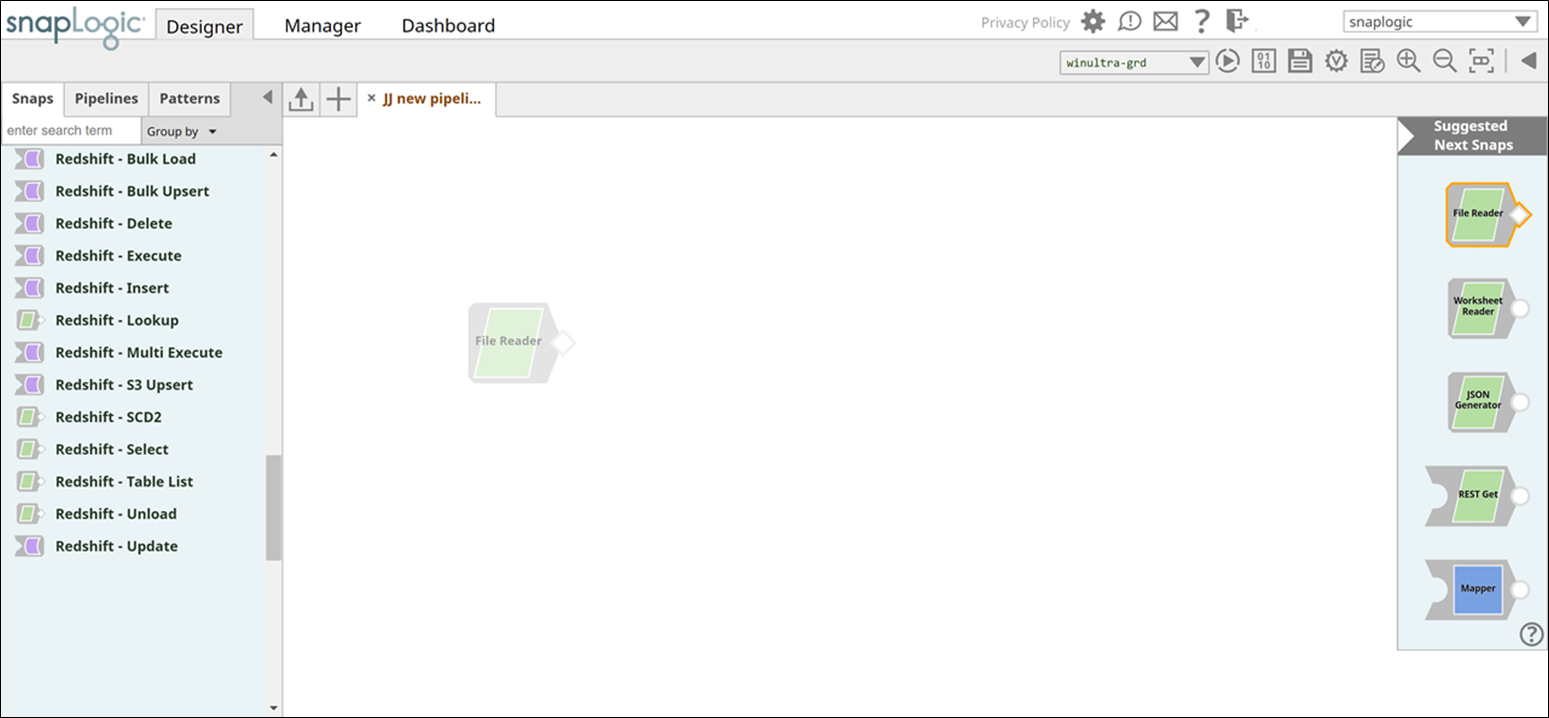
Figure 1 – SnapLogic Pipeline Designer.
Systems Architecture
The diagram in Figure 2 shows the SnapLogic integration runtime, Groundplex, installed on Amazon Web Services (AWS) in the customer’s private subnet. The Redshift cluster is also up and running in the same subnet.

Figure 2 – Architecture for data migration to Amazon Redshift.
Redshift Bulk Load Snap: Under the Hood
SnapLogic provides a comprehensive platform to meet integration requirements of enterprises thanks to a high degree of flexibility and ease-of-use while migrating databases.
You can leverage SnapLogic’s unified platform for data integration, data migration, application integration, API management, and data engineering, among other capabilities, all catered to meet enterprise standards and requirements.
Whether you’re loading data from a MySQL database, Salesforce, or any other software-as-a-service (SaaS) or on-premises-based application, you can effectively load data into Redshift using the low code, no code paradigm of the SnapLogic platform.
The Redshift Bulk Load Snap consumes data from an upstream source and writes it to a staging file on Amazon Simple Storage Service (Amazon S3). It does so by automatically representing data in a JSON format while it streams through the SnapLogic platform, without the user having to manually intervene. It also takes care of the schema compatibility checks of the source and the target systems.
Subsequently, the Snap automatically runs the COPY command to insert data into a target Redshift table.

Figure 3 – COPY command initiated by the Redshift Bulk Load Snap.
If the target table does not exist when the Snap initiates the bulk load operation, the Snap automatically creates a table in the target schema with the necessary columns and datatypes to hold the first incoming document.
The Snap also provides an option to specify the target table’s metadata before creating the actual table. This ability provides even more flexibility for users that intend to migrate their data from a relational database management system (RDBMS) to Redshift, without having to first create a table in Redshift.
Effectively, the Snap allows you to replicate a table from one database to another. The Redshift Bulk Load Snap also allows you to control what data goes into the Redshift instance by configuring the Snap properties.
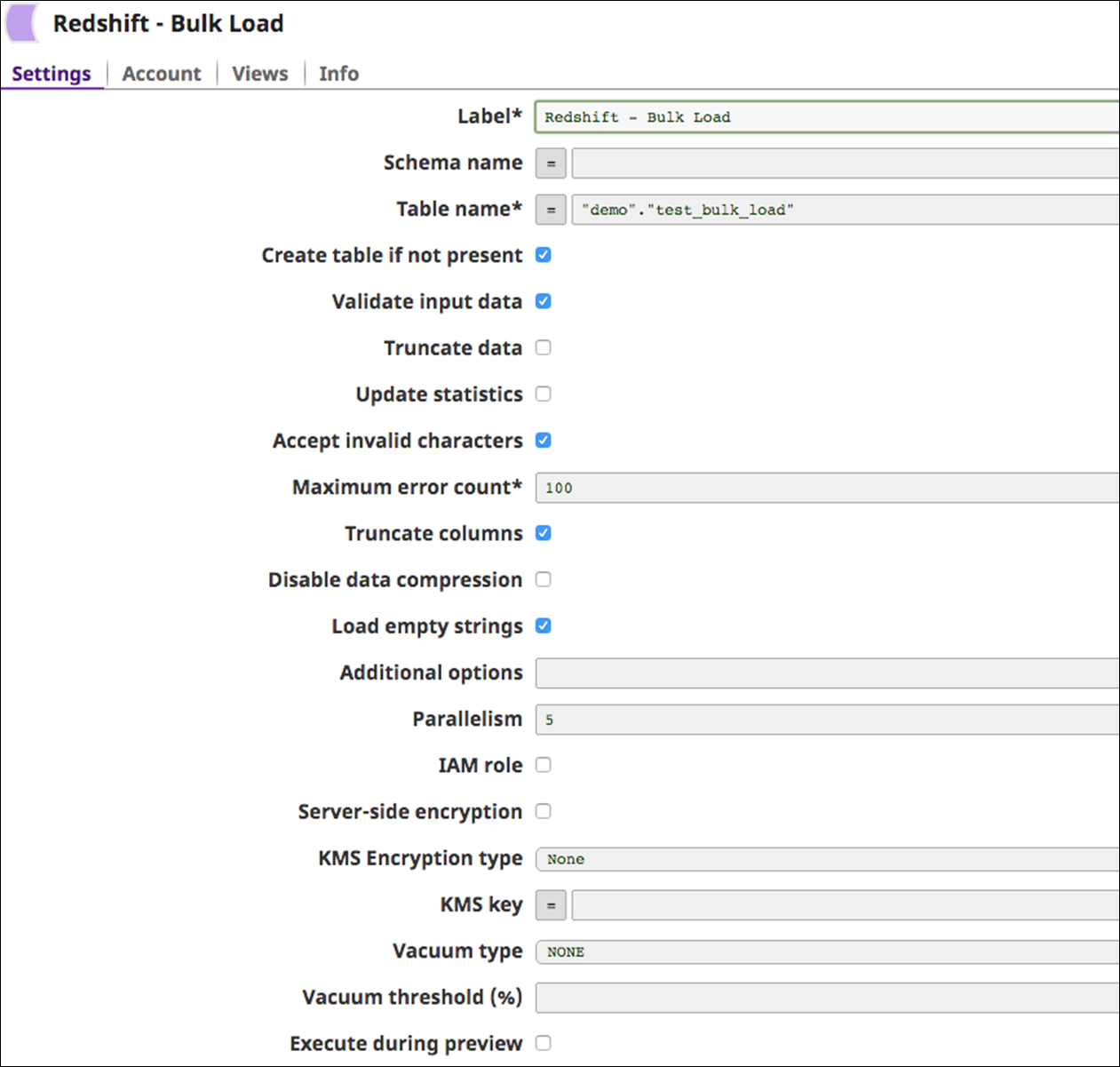
Figure 4 – Configuration for SnapLogic Redshift Bulk Load Snap.
Overall, this is a feature-rich Snap that has multiple options to handle nearly every use case.
Here are a few key highlights:
- As part of ensuring the validity of upstream data, the Snap provides users the option to validate input data to handle non-flat map data in a graceful manner.
- The Truncate data option on the Snap allows users to truncate the existing target table’s data before initiating the bulk load operation.
- To improve the efficiency of the bulk load operation, you can adjust Parallelism as necessary based on the capacity of the Redshift cluster. A value greater than “1” (say, N) will make the Snap consume upstream data and create “N” staging files on Amazon S3 followed by concurrent executions of the COPY command, thereby improving execution time for the bulk load operation.
- It’s important to clean up tables after a bulk delete, bulk load, or a series of updates. The Vacuum command can be run against the entire database or individual tables.
The Snap supports multiple options for Vacuum type such as FULL, SORT ONLY, DELETE ONLY, and REINDEX.
In addition, certain Snaps such as Redshift Bulk Load, Redshift Unload, Redshift Bulk Upsert, and Redshift S3 Upsert support AWS Key Management Service (KMS) encryption.
If “Server-Side” KMS encryption is selected, output files written out to Amazon S3 are encrypted using the SSE-S3.
Inside SnapLogic
In this example, we’ll migrate data from MySQL to Amazon Redshift. This integration pipeline leverages the Redshift Bulk Load Snap to load the source data into a target table.
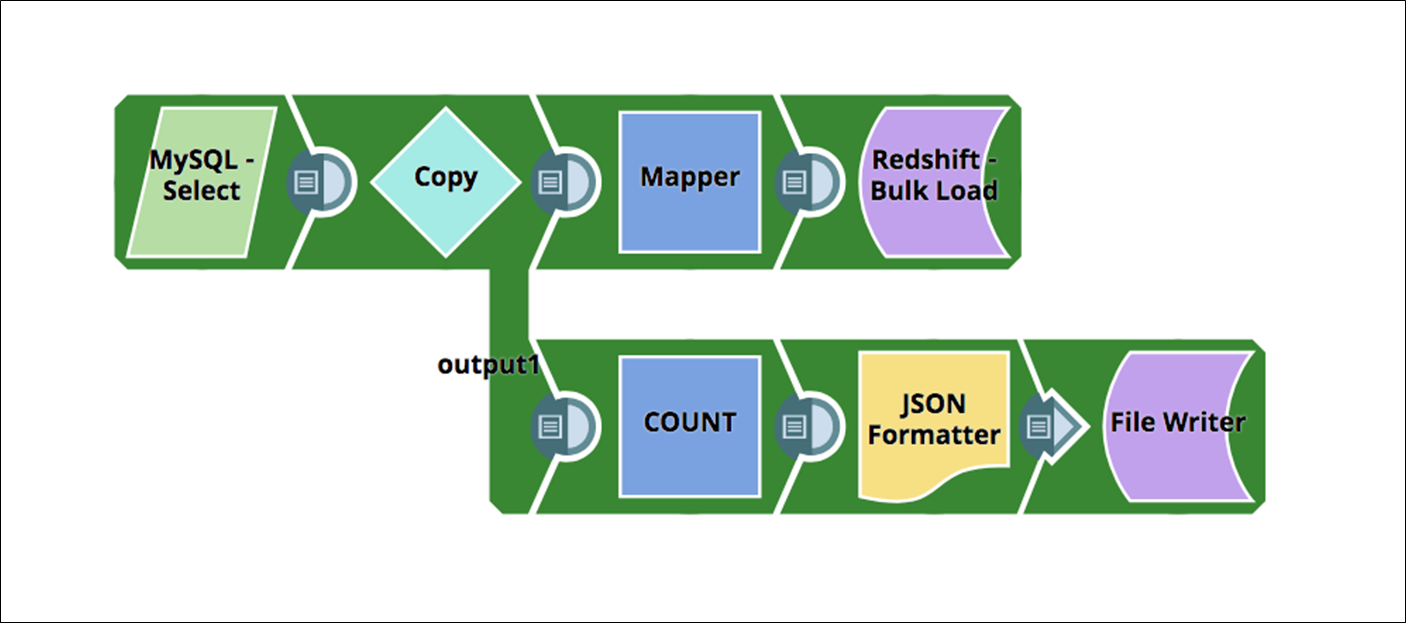
Figure 5 – Integration pipeline that migrates data from MySQL database to Redshift.
To ensure convenience, SnapLogic allows users to review the following pipeline execution statistics for every Snap in the pipeline, all through a single interface:
- Pipeline execution duration.
- CPU and memory consumption.
- Total documents processed.
- Rate at which the documents were processed.

Figure 6 – Pipeline execution statistics for the MySQL to Redshift pipeline.
For use cases involving a massive data migration, such as an initial migration from another database, the Redshift Bulk Load Snap is efficient because it abstracts behind-the-scenes complexities.
The main purpose of the Redshift Bulk Load Snap is to fetch massive volumes of data in chunks or batches from the source system and write it to Redshift, the target system.
In this example, the Bulk Load Snap was 30 times faster than a query-based insert operation into Redshift, but the performance may vary based on other factors, such as:
- Volume of data to be loaded.
- Hardware availability on the SnapLogic Snaplex (execution) node.
Synchronization and Fail-safe Execution
After the initial bulk load, customers can keep the source system and have it synchronized with Redshift. This is done by scheduling a batch workload for your SnapLogic pipelines.
You control the frequency of the batch execution to meet business requirements. For example, you can schedule to have this pipeline run every hour or at the end of a business day to upload incremental changes to Redshift seamlessly.
The pipeline shown in Figure 7 can help you determine changes made to a record using the Redshift SCD2 (Slowly Changing Dimensions) Snap, and upsert new or updated records.
Also, for both batch and real-time integration use cases involving migrating data from a source system to Redshift, SnapLogic enables creation of APIs that could be consumed by API consumers, within or outside the enterprise, to automate the business logic.
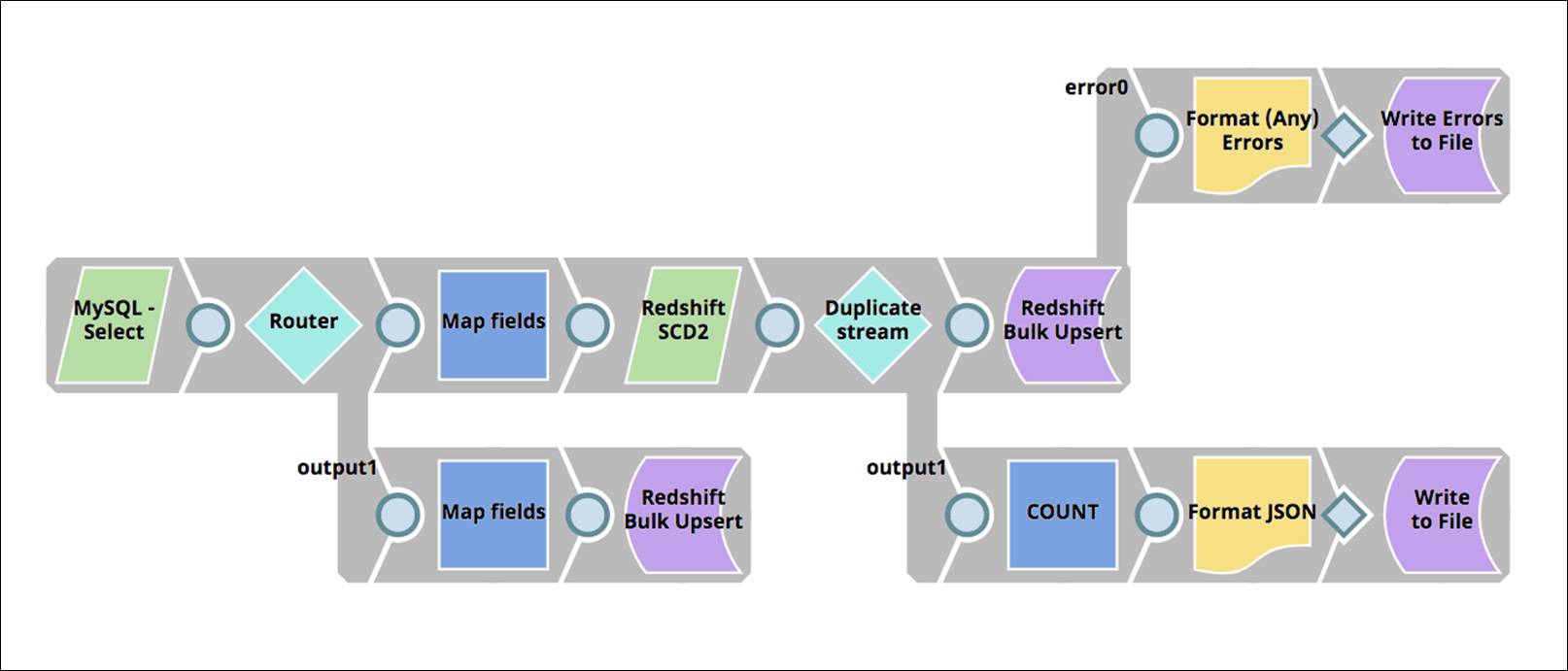
Figure 7 – Pipeline to synchronize data with Redshift after initial upload.
SnapLogic provides a number of features to recover from errors. The platform makes it easy to identify and resolve pipeline errors with error outputs for all the Snaps.
In case of network failures, SnapLogic automatically retries the scheduled pipelines that were unable to execute. Additionally, the platform provides resumable pipelines that help recover from source or target endpoint failures to provide exactly-once guaranteed data delivery.
Customer Success: Kaplan, Inc.
As a cloud-based education company, Kaplan, Inc. leverages the AWS platform to drive their big data initiative. Before SnapLogic, Kaplan forged integrations using a data virtualization technology along with a couple of off-the-shelf products, all of which required an exorbitant amount of time to derive the insights needed.
At the same time, they were undergoing an expansion of their big data strategy and were digitally transforming their company. To help in this effort, they sought a partner with an iPaaS that was flexible, scalable, had a shallow learning curve, and required minimal maintenance.
Kaplan also sought a solution that complied with their security standards and policies. The organization found these capabilities with SnapLogic, and today Kaplan has successfully created their own data lake within Amazon Redshift and ingests data from multiple sources, including ones that are part of the AWS ecosystem.
Kaplan has integrated more than 50 applications in less than a year, and plans to integrate 40 more applications over the next year. The platform ingests 20-30 million new records per day, while columnar compression has helped keep storage demands to under three terabytes.
Summary
In this post, we covered why you need Amazon Redshift, a cloud-based data warehouse, and some of the challenges faced when migrating data from on-premises database such as MySQL.
We also covered how SnapLogic can help you migrate and subsequently synchronize on-premises based databases with Redshift, and how SnapLogic’s connector for Redshift operates under the hood. Finally, we outlined how Kaplan has leveraged AWS services and the SnapLogic platform to drive their big data initiative.
If your organization is interested in learning more about how SnapLogic works with Amazon Redshift and other AWS services, please sign up for a free trial. The trial allows you to test every aspect of the Redshift Snap Pack and explore other aspects of the SnapLogic Intelligent Integration Platform.
.
 |
SnapLogic – APN Partner Spotlight
SnapLogic is an AWS Competency Partner. Through its visual, automated approach to integration, SnapLogic uniquely empowers business and IT users to accelerate integration needs for applications, data warehouse, big data, and analytics initiatives.
Contact SnapLogic | Solution Overview
*Already worked with SnapLogic? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.