AWS Partner Network (APN) Blog
Monitoring End Users’ Application Experience on AWS with Cisco ThousandEyes
By Ivo Pinto, Sr. Cloud Infrastructure Architect – AWS
By Asier Arlegui Lacunza, Principal Architect – Cisco
 |
| Cisco |
 |
End users’ digital experiences with applications hosted on Amazon Web Services (AWS) are often critical for the success of a business, and many times it’s representative of an organization’s brand.
This criticality incentivizes IT teams to measure and monitor different users’ experiences while interacting with their applications at all times.
The deployment of applications has evolved into highly distributed architectures. AWS Well-Architected applications, for example, can be deployed across different AWS Availability Zones (AZs) or even regions, depending on availability requirements.
Application access patterns have also changed—users can now access applications from multiple places such as corporate offices or even from the comfort of their homes. The use of the internet as the main transport to connect users and applications has become more popular, and nowadays almost every communication crosses paths through the internet that include multiple networks.
In such distributed environments, measuring simple characteristics such as IP reachability or latency from client to application is not sufficient, because these metrics are not representative of end users’ experiences.
Cisco ThousandEyes monitors network infrastructure, troubleshoots application delivery, and maps internet performance, all from a SaaS-based platform. ThousandEyes provides a collectively powered view of the internet, enabling you to see, understand, and improve digital experiences for consumers of your applications, wherever they are.
Whether you’re an AWS customer with user experience-dependent applications, or you’re looking to migrate applications to AWS and want to benchmark user experience, ThousandEyes can help you make data-driven decisions.
Connecting Users to Applications in AWS
Users can connect from anywhere to applications hosted on AWS. These can be internal users such as employees or external users like end customers, and the type of user typically depends on the type of application.
Monitoring users’ experiences is important regardless of the type of user. However, some applications are deemed more critical than others by the business. For example, a human resources application—such as a payroll history portal that is only accessed by internal users—is often considered less critical than an end user-facing shopping cart application that’s responsible for payments on an ecommerce website.
The connectivity models from users to applications is diverse and can include different networking solutions. Connectivity models can be divided into two categories: public and private.
By public connectivity, we mean all of the different solutions that use the internet as a transport medium, such as direct internet access or AWS Site-to-Site VPN. On the contrary, private connectivity refers to solutions that use a private backbone, such as AWS Direct Connect.
Focusing on the public category, these connectivity models rely on the internet, which is an extensive and unpredictable network composed of thousands of independently managed service providers. Unpredictable network outages can occur and often do, which disrupts the connectivity from users to AWS-hosted applications. The root cause of an outage is difficult to identify and resolve without in-depth visibility.
In Figure 1 below, several users are accessing a cloud-hosted application. A network link in one of the network paths is deteriorated and causing traffic drops, highlighted in thick-orange. The users using that network path suffer application experience degradation as a result of packet drops and TCP retransmissions.
While you may not have control of the end-to-end path from your users to your AWS-hosted applications, you are still responsible to provide a good user experience.
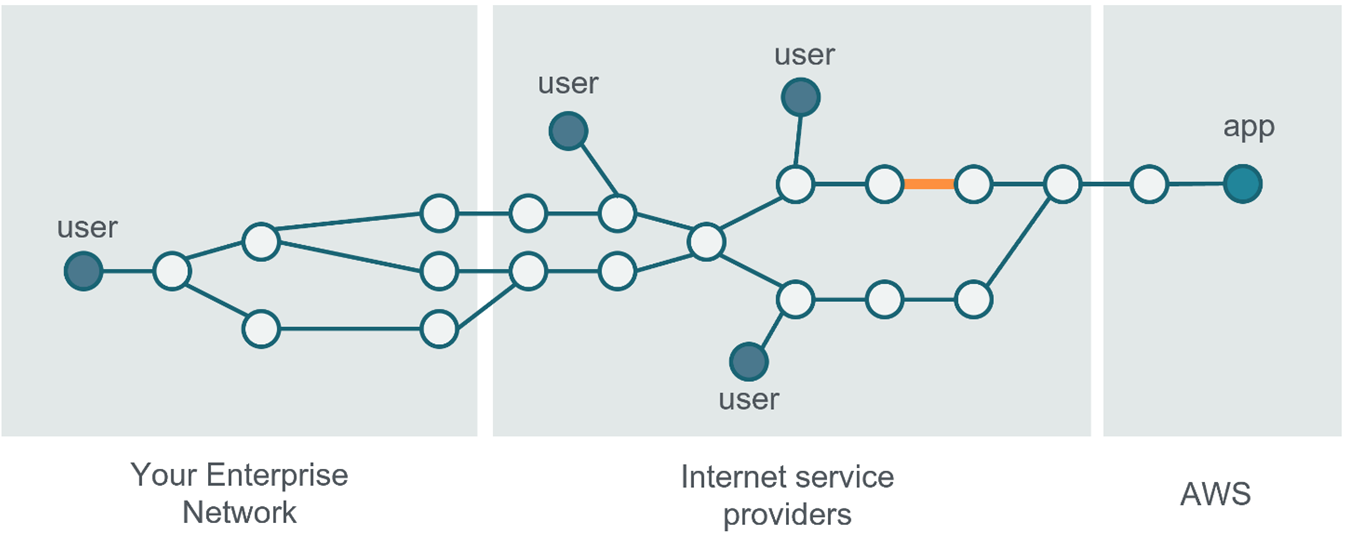
Figure 1 – Visual representation of a network connectivity diagram with a link outage.
How can you identify in near real time where the network outage occurred, and who is responsible to act accordingly?
End-to-End Path Visibility
With ThousandEyes, you get end-to-end path visibility, both real time and on-demand, from clients to applications residing on AWS. This can improve the mean time to identify (MTTI) and mid time to resolve (MTTR) connectivity incidents, as well as your operational efficiency.
ThousandEyes gives you visibility into the digital experience. It seamlessly discovers the underlay and overlay path and monitors user experience based on metrics such as transaction scripting and page load times, in correlation to the underlying network connectivity (Wireless LAN, WAN, internet connectivity, VPN connection).
It also provides information on the dependency from DNS to CDN, DDoS security providers, and Border Gateway Protocol (BGP) routing. This enables you to identify issues that could be impacting performance, such as a lossy node within an otherwise obscured underlay network.
ThousandEyes gathers network and application data (layers 3 through 7), correlates, and presents it in a cohesive view of the end-to-end digital experience via web or API.
You deploy Enterprise agents, which are lightweight software-based agents that can be installed on your own network, in data centers, branch offices, or in the cloud. They provide insights about your organization network paths, come in different form factors, and can be installed in many platform types and operating systems.
You can deploy Enterprise agents along with your applications on Amazon Elastic Compute Cloud (Amazon EC2). Detailed system requirements are described in the documentation.
In the network scenario described in Figure 1, you could have an agent deployed in your enterprise network, and another in the same EC2 instance as your application.
By defining agent-to-agent tests, ThousandEyes will continuously monitor and test the network path between the agents and collect several bidirectional metrics:
- Packet loss
- Latency
- Jitter
- Throughput
- Path visualization and path MTU
For more information, visit the agent-to-agent test overview on the ThousandEyes website.
In Figure 2 below, the path visualization diagram illustrates the network nodes the communication between agents’ traverses. In the case there was a link outage in a path, you would see it highlighted along with the detailed network metrics associated per hop.
This type of dashboard allows you to quickly identify what is affecting your users’ experience.
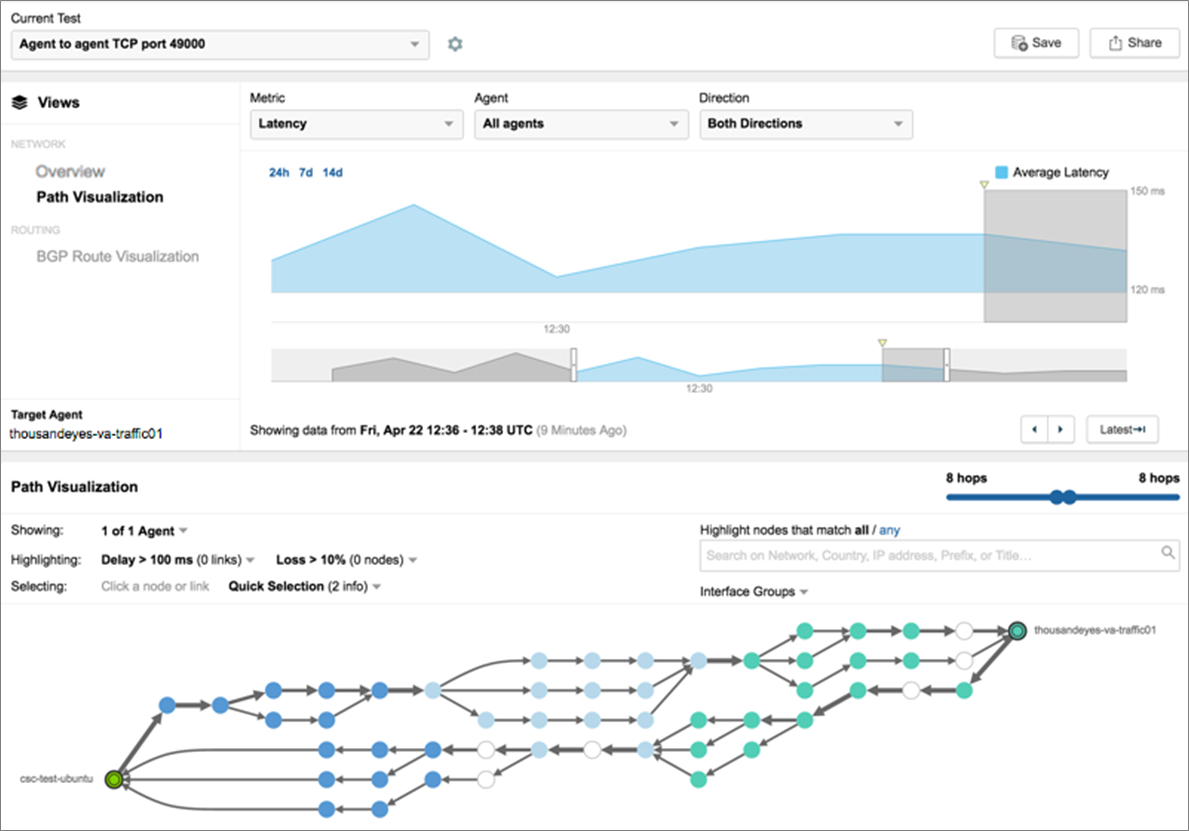
Figure 2 – Agent-to-agent time-based path visualization.
In addition to Enterprise agents, there are other two agent types: Endpoint and Cloud agents. Learn more about Endpoint agents, Cloud agents, and how to configure them in the documentation.
Agents also collect unidirectional metrics by defining agent to server tests. In these, the target is a host or a service instead of another ThousandEyes agent process. These tests allow you to measure network metrics for any application reachable via IP.
Because you don’t need to deploy an agent in the same instance as the application, this test type extends coverage to a wide range of AWS services, including Amazon API Gateway, Amazon Simple Storage Service (Amazon S3), or Elastic Load Balancing.
All three types of agents feed data into the ThousandEyes big data analytics platform in real time, creating a massive dataset on when and where traffic flows are disrupted in your network to application paths.
Predictive User Experience
Resolving outages in a quick manner is good, but there are also use cases that don’t require you to have downtime. ThousandEyes can help you confidently expand your business on AWS.
Organizations grow and tend to expand over time, and a possible type of expansion is geographical. Some organizations start local and are successful after they become global.
AWS helps your organization expand thanks to its global infrastructure. However, some customers want to know what the performance looks like from a specific country to a specific AWS region, or from a new corporate location to their existing AWS-hosted applications.
These are scenarios where ThousandEyes can help you.
If you have all of your applications deployed in Amazon Virtual Private Clouds (VPCs) among different Availability Zones in the Paris region but have recently opened a branch office in Virginia, you may ask yourself:
- What will be the experience of my employees accessing my internal App A?
- Will the experience of my workforce change throughout the day?
- Some sensors on the newly-opened branch sometimes become unreachable; is it because of the service provider transport medium or my local area network physical installation?
With ThousandEyes, by deploying agents on the new branch and on instances in the same VPC, and defining agent-to-agent tests, you are able to collect network data and verify if it meets your expectations, so that you can take data-driven decisions.
For example, you may decide to deploy new instances of certain applications in AWS N. Virginia region to improve the users’ experiences in the new branch office.
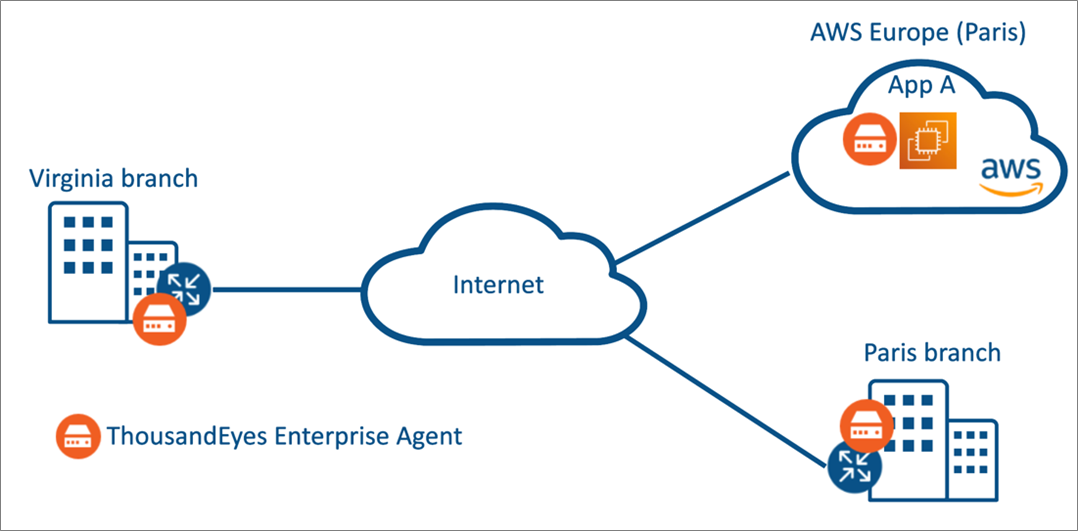
Figure 3 – ThousandEyes Enterprise agents in branch sites and in EC2 instances.
Summary
Leveraging Cisco ThousandEyes on AWS allows you to have in-depth visibility into your users’ experience.
Independently of the network connectivity model of your application, networks can suffer outages. Quickly identifying and resolving outages is key to deliver the best user experience.
Simple reachability metrics are no longer enough in a complex distributed environment. Rather, path visualization diagrams and comprehensive metrics are a more effective way to minimize the effects of outages.
With a simple and easy-to-follow installation, you can deploy ThousandEyes agents and start monitoring your network paths gaining visibility into your users’ experience independently of where they’re connecting from.
Start today your 15-day trial on the ThousandEyes website.
.

.
Cisco Systems – AWS Partner Spotlight
Cisco is an AWS Partner providing a range of products for transporting data, voice, and video within buildings, across campuses, and around the world.
Contact Cisco | Partner Overview | AWS Marketplace
*Already worked with Cisco? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.