AWS Architecture Blog
What to consider when modernizing APIs with GraphQL on AWS
In the next few years, companies will build over 500 million new applications, more than has been developed in the previous 40 years combined (see IDC article). API operations enable innovation. They are the “front door” to applications and microservices, and an integral layer in the application stack. In recent years, GraphQL has emerged as a modern API approach. With GraphQL, companies can improve the performance of their applications and the speed in which development teams can build applications. In this post, we will discuss how GraphQL works and how integrating it with AWS services can help you build modern applications. We will explore the options for running GraphQL on AWS.
How GraphQL works
Imagine you have an API frontend implemented with GraphQL for your ecommerce application. As shown in Figure 1, there are different services in your ecommerce system backend that are accessible via different technologies. For example, user profile data is stored in a highly scalable NoSQL table. Orders are accessed through a REST API. The current inventory stock is checked through an AWS Lambda function. And the pricing information is in an SQL database.

Figure 1. How GraphQL works
Without using GraphQL, client applications must make multiple separate calls to each one of these services. Because each service is exposed through different API endpoints, the complexity of accessing data from the client side increases significantly. In order to get the data, you have to make multiple calls. In some cases, you might over fetch data as the data source would send you an entire payload including data you might not need. In some other circumstances, you might under fetch data as a single data source would not have all your required data.
A GraphQL API combines the data from all these different services into a single payload that the client defines based on its needs. For example, a smartphone has a smaller screen than a desktop application. A smartphone application might require less data. The data is retrieved from multiple data sources automatically. The client just sees a single constructed payload. This payload might be receiving user profile data from Amazon DynamoDB, or order details from Amazon API Gateway. Or it could involve the injection of specific fields with inventory availability and price data from AWS Lambda and Amazon Aurora.
When modernizing frontend APIs with GraphQL, you can build applications faster because your frontend developers don’t need to wait for backend service teams to create new APIs for integration. GraphQL simplifies data access by interacting with data from multiple data sources using a single API. This reduces the number of API requests and network traffic, which results in improved application performance. Furthermore, GraphQL subscriptions enable two-way communication between the backend and client. It supports publishing updates to data in real time to subscribed clients. You can create engaging applications in real time with use cases such as updating sports scores, bidding statuses, and more.
Options for running GraphQL on AWS
There are two main options for running GraphQL implementation on AWS, fully managed on AWS using AWS AppSync, and self-managed GraphQL.
I. Fully managed using AWS AppSync
The most straightforward way to run GraphQL is by using AWS AppSync, a fully managed service. AWS AppSync handles the heavy lifting of securely connecting to data sources, such as Amazon DynamoDB, and to develop GraphQL APIs. You can write business logic against these data sources by choosing code templates that implement common GraphQL API patterns. Your APIs can also interact with other AWS AppSync functionality such as caching, to improve performance. Use subscriptions to support real-time updates, and client-side data stores to keep offline devices in sync. AWS AppSync will scale automatically to support varied API request loads. You can find more details from the AWS AppSync features page.

Figure 2. AWS AppSync in an ecommerce system implementation
Let’s take a closer look at this GraphQL implementation with AWS AppSync in an ecommerce system. In Figure 2, a schema is created to define types and capabilities of the desired GraphQL API. You can tie the schema to a Resolver function. The schema can either be created to mirror existing data sources, or AWS AppSync can create tables automatically based the schema definition. You can also use GraphQL features for data discovery without viewing the backend data sources.
After a schema definition is established, an AWS AppSync client can be configured with an operation request, such as a query operation. The client submits the operation request to GraphQL Proxy along with an identity context and credentials. The GraphQL Proxy passes this request to the Resolver, which maps and initiates the request payload against pre-configured AWS data services. These can be an Amazon DynamoDB table for user profile, an AWS Lambda function for inventory service, and more. The Resolver initiates calls to one or all of these services within a single API call. This minimizes CPU cycles and network bandwidth needs. The Resolver then returns the response to the client. Additionally, the client application can change data requirements in code on demand. The AWS AppSync GraphQL API will dynamically map requests for data accordingly, enabling faster prototyping and development.
II. Self-Managed GraphQL
If you want the flexibility of selecting a particular open-source project, you may choose to run your own GraphQL API layer. Apollo, graphql-ruby, Juniper, gqlgen, and Lacinia are some popular GraphQL implementations. You can leverage AWS Lambda or container services such as Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Services (EKS) to run GraphQL open-source implementations. This gives you the ability to fine-tune the operational characteristics of your API.
When running a GraphQL API layer on AWS Lambda, you can take advantage of the serverless benefits of automatic scaling, paying only for what you use, and not having to manage your servers. You can create a private GraphQL API using Amazon ECS, EKS, or AWS Lambda, which can only be accessed from your Amazon Virtual Private Cloud (VPC). With Apollo GraphQL open-source implementation, you can create a Federated GraphQL that allows you to combine GraphQL APIs from multiple microservices into a single API, illustrated in Figure 3. The Apollo GraphQL Federation with AWS AppSync post shows a concrete example of how to integrate an AWS AppSync API with an Apollo Federation gateway. It uses specification-compliant queries and directives.
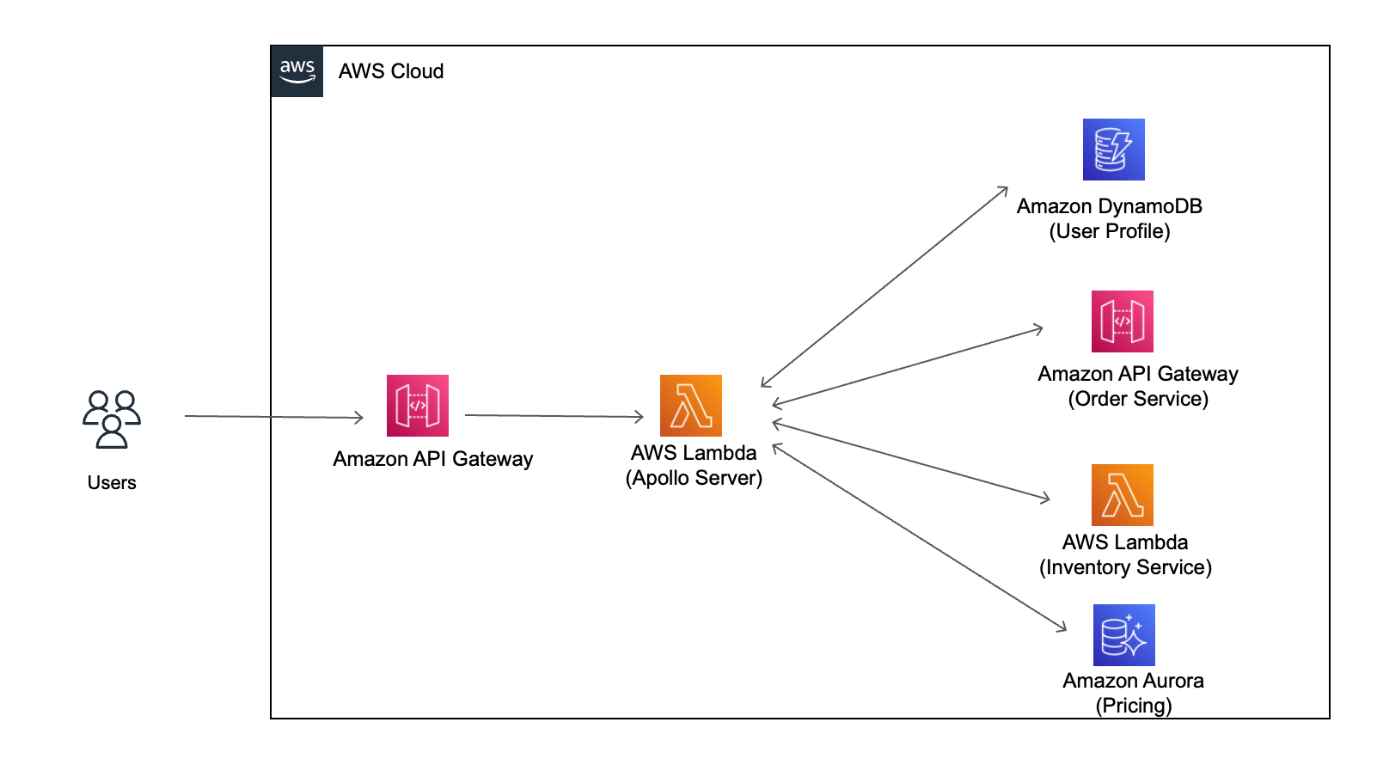
Figure 3. Apollo GraphQL implementation on AWS Lambda
When choosing self-managed GraphQL implementation, you have to spend time writing non-business logic code to connect data sources. You must implement authorization, authentication, and integrate other common functionalities. This can be caches to improve performance, subscriptions to support real-time updates, and client-side data stores to keep offline devices in sync. Because of these responsibilities, you have less time to focus on the business logic of application.
Similarly, backend development teams and API operators of an open-source GraphQL implementation must provision and maintain their own GraphQL servers. Remember that even with a serverless model, API developers and operators are still responsible for monitoring, performance tuning, and troubleshooting the API platform service.
Conclusion
Modernizing APIs with GraphQL gives your frontend application the ability to fetch just the data that’s needed from multiple data sources with an API call. You can build modern mobile and web applications faster, because GraphQL simplifies API management. You have flexibility to run an open-source GraphQL implementation most closely aligned with your needs on AWS Lambda, Amazon ECS, and Amazon EKS. With AWS AppSync, you can set up GraphQL quickly and increase your development velocity by reducing the amount of non-business API logic code.
Further reading: