AWS News Blog
New – Amazon FSx for OpenZFS

|
Last month, my colleague Bill Vass said that we are “slowly adding additional file systems” to Amazon FSx. I’d question Bill’s definition of slow, given that his team has launched Amazon FSx for Lustre, Amazon FSx for Windows File Server, and Amazon FSx for NetApp ONTAP in less than three years.
Amazon FSx for OpenZFS
Today I am happy to announce Amazon FSx for OpenZFS, the newest addition to the Amazon FSx family. Just like the other members of the family, this new addition lets you use a popular file system without having to deal with hardware provisioning, software configuration, patching, backups, and the like. You can create a file system in minutes and begin to enjoy the benefits of OpenZFS right away: transparent compression, continuous integrity verification, snapshots, and copy-on-write. Even better, you get all of these benefits without having to develop the specialized expertise that has traditionally been needed to set up and administer OpenZFS.
FSx for OpenZFS is powered by the AWS Graviton family processors and AWS SRD (Scalable Reliable Datagram) Networking, and can deliver up to 1 million IOPS with latencies of 100-200 microseconds, along with up to 4 GB/second of uncompressed throughput, up to 12 GB/second of compressed throughput, and up to 12.5 GB/second throughput to cached data. FSx for OpenZFS supports the OpenZFS Adaptive Replacement Cache (ARC) and uses memory in the file server to provide faster performance. It also supports advanced NFS performance features such as session trunking and NFS delegation, allowing you to get very high throughput and IOPS from a single client, while still safely caching frequently accessed data on the client side.
FSx for OpenZFS volumes can be accessed from cloud or on-premises Linux, MacOS, and Windows clients via industry-standard NFS protocols (v3, v4, v4.1, and v4.2). Cloud clients can be Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Kubernetes Service (Amazon EKS) clusters, Amazon WorkSpaces virtual desktops, and VMware Cloud on AWS. Your data is stored in encrypted form and replicated within an AWS Availability Zone, with components replaced automatically and transparently as necessary.
You can use FSx for OpenZFS to address your highly demanding machine learning, EDA (Electronic Design Automation), media processing, financial analytics, code repository, DevOps, and web content management workloads. With performance that is close to local storage, FSx for OpenZFS is great for these and other latency-sensitive workloads that manipulate and sequentially access many small files. Finally, because you can create, mount, use, and delete file systems as needed, you can now use OpenZFS in a dynamic, agile fashion.
Using Amazon FSx for OpenZFS
I can create an OpenZFS file system using the AWS Management Console, CLI, APIs, or AWS CloudFormation. From the FSx Console I click Create file system and choose Amazon FSx for OpenZFS:
I can choose Quick create (and use recommended best-practice configurations), or Standard create (and set all of the configuration options myself). I’ll take the easy route and use the recommended best practices to get started. I enter a name (Jeff-OpenZFS) select the amount of SSD storage that I need, choose a VPC & subnet, and click Next:
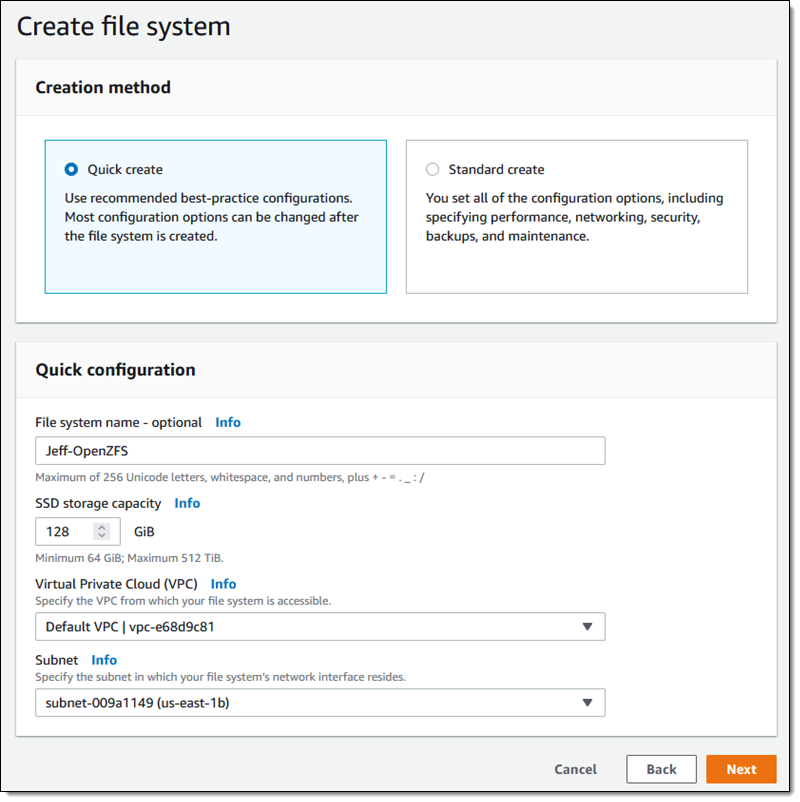
The console shows me that I can edit many of the attributes of my file system later if necessary. I review the settings and click Create file system:

My file system is ready within a minute or two, and I click Attach to get the proper commands to mount it to my client:
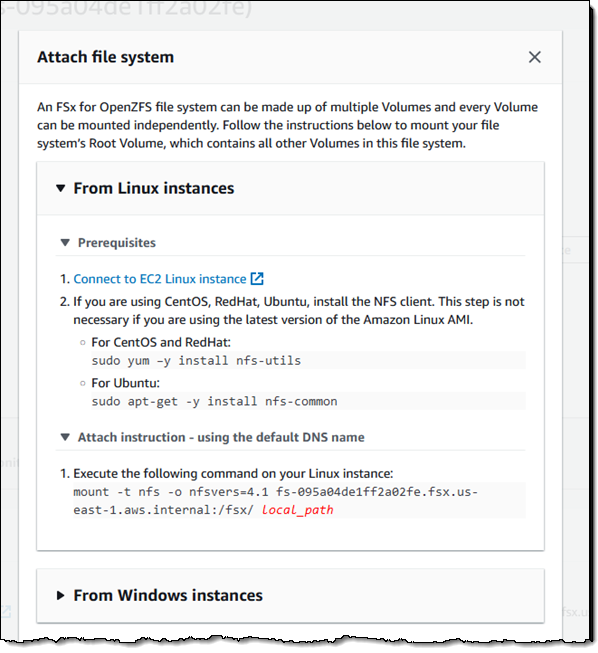
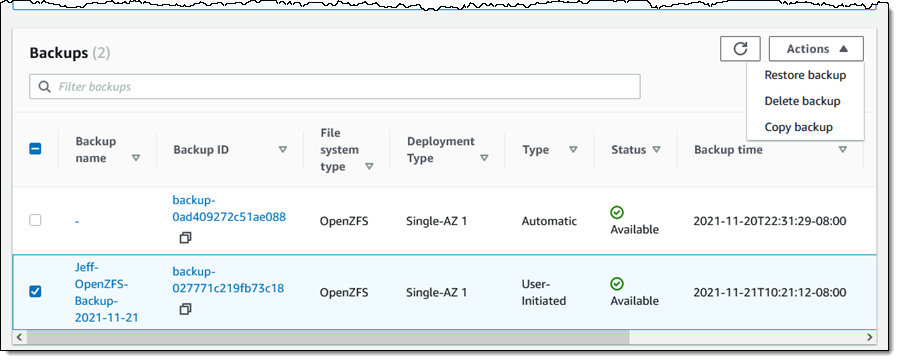
To be more precise, I am mounting the root volume (/fsx) of my file system. Once it is mounted, I can use it as I would any other file system. After I add some files to it, I can use the Action menu in the console to create a backup:
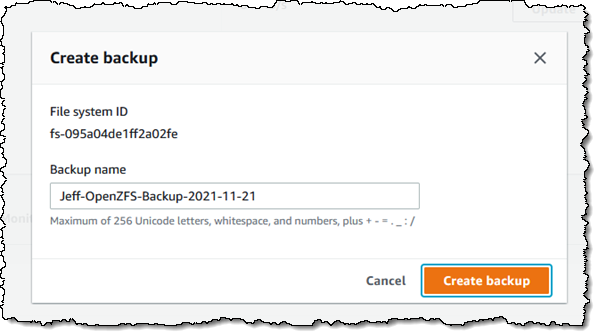
I can restore the backup to a new file system:
As I noted earlier, each file system can deliver up to 4 gigabytes per second of throughput for uncompressed data. I can look at total throughput and other metrics in the console:

I can set throughput capacity of each volume when I create it, and then change it later if necessary:

Changes take effect within minutes. The file system remains active and mounted while the change is put into effect, but some operations may pause momentarily:

A single OpenZFS file system can contain multiple volumes, each with separate quotas (overall volume storage, per-user storage, and per-group storage) and compression settings. When I use the quick create option a root volume named fsx is created for me; I can click Create volume to create more volumes at any time:
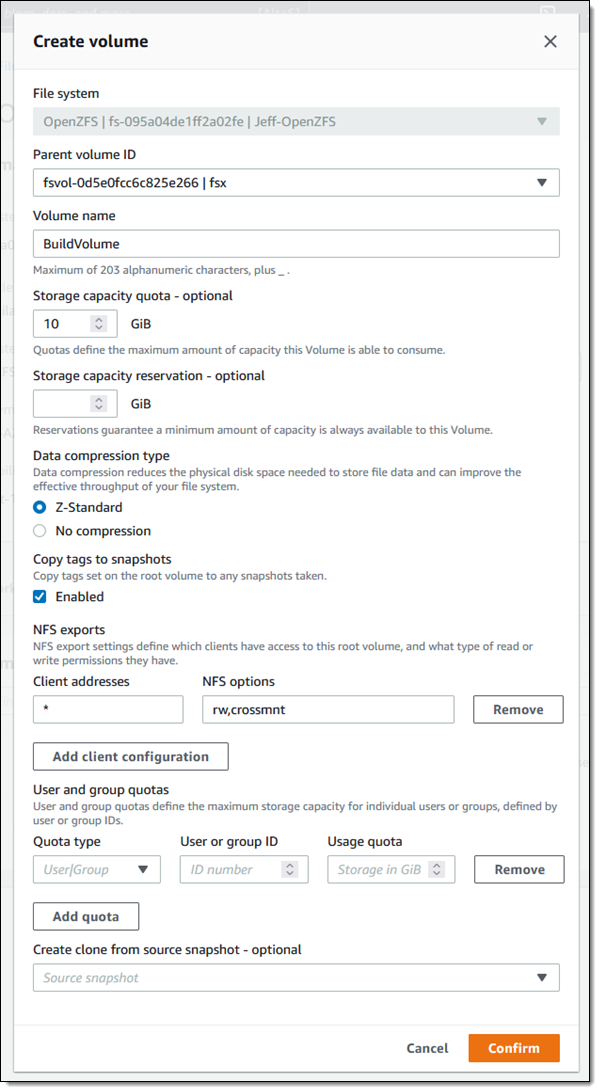
The new volume exists within the namespace hierarchy of the parent, and can be mounted separately or accessed from the parent.

Things to Know
Here are a couple of quick facts and to wrap up this post:
Pricing – Pricing is based on the provisioned storage capacity, throughput, and IOPS.
Regions – Amazon FSx for OpenZFS is available in the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), Canada (Central), Asia Pacific (Tokyo), and Europe (Frankfurt) Regions.
In the Works – We are working on additional features including storage scaling, IOPS scaling, a high availability option and another storage class.
Now Available
Amazon FSx for OpenZFS is available now and you can start using it today!
— Jeff;