AWS Big Data Blog
Category: Amazon Athena

Query, visualize, and forecast TruFactor web session intelligence with AWS Data Exchange
This post showcases TruFactor Intelligence-as-a-Service data on AWS Data Exchange. TruFactor’s anonymization platform and proprietary AI ingests, filters, and transforms more than 85 billion high-quality raw signals daily from wireless carriers, OEMs, and mobile apps into a unified phygital consumer graph across physical and digital dimensions. TruFactor intelligence is application-ready for use within any AWS analytics or ML service to power your models and applications running on AWS, with no additional processing required.

Build a cloud-native network performance analytics solution on AWS for wireless service providers
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post demonstrates a serverless, cloud-based approach to building a network performance analytics solution using AWS services that can provide flexibility and performance while keeping costs under control with pay-per-use AWS services. […]

A public data lake for analysis of COVID-19 data
April 2024: This post was reviewed for accuracy. As the COVID-19 pandemic continues to threaten and take lives around the world, we must work together across organizations and scientific disciplines to fight this disease. Innumerable healthcare workers, medical researchers, scientists, and public health officials are already on the front lines caring for patients, searching for […]

How Siemens built a fully managed scheduling mechanism for updates on Amazon S3 data lakes
Siemens is a global technology leader with more than 370,000 employees and 170 years of experience. To protect Siemens from cybercrime, the Siemens Cyber Defense Center (CDC) continuously monitors Siemens’ networks and assets. To handle the resulting enormous data load, the CDC built a next-generation threat detection and analysis platform called ARGOS. ARGOS is a […]

Cross-account AWS Glue Data Catalog access with Amazon Athena
June 2021 Update – Amazon Athena has launched built-in support for AWS Glue Data Catalogs sharing. The below solution is no longer relevant and you should make use of the built-in feature. Many AWS customers use a multi-account strategy. A centralized AWS Glue Data Catalog is important to minimize the amount of administration related to […]
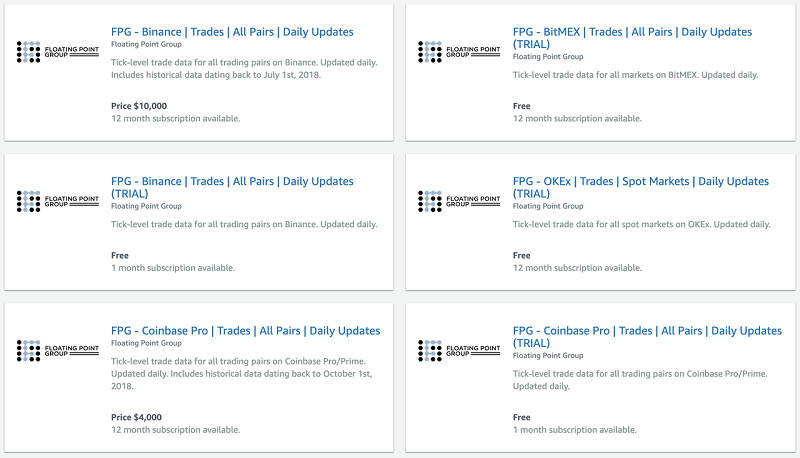
Collect and distribute high-resolution crypto market data with ECS, S3, Athena, Lambda, and AWS Data Exchange
This is a guest post by Floating Point Group. In their own words, “Floating Point Group is on a mission to bring institutional-grade trading services to the world of cryptocurrency.” The need and demand for financial infrastructure designed specifically for trading digital assets may not be obvious. There’s a rather pervasive narrative that these coins […]

Extract, Transform and Load data into S3 data lake using CTAS and INSERT INTO statements in Amazon Athena
April 2024: This post was reviewed for accuracy. Amazon Athena is an interactive query service that makes it easy to analyze the data stored in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. You can reduce your per-query […]

Connect Amazon Athena to your Apache Hive Metastore and use user-defined functions
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. This post details the two new preview features that you can start using today: connecting […]
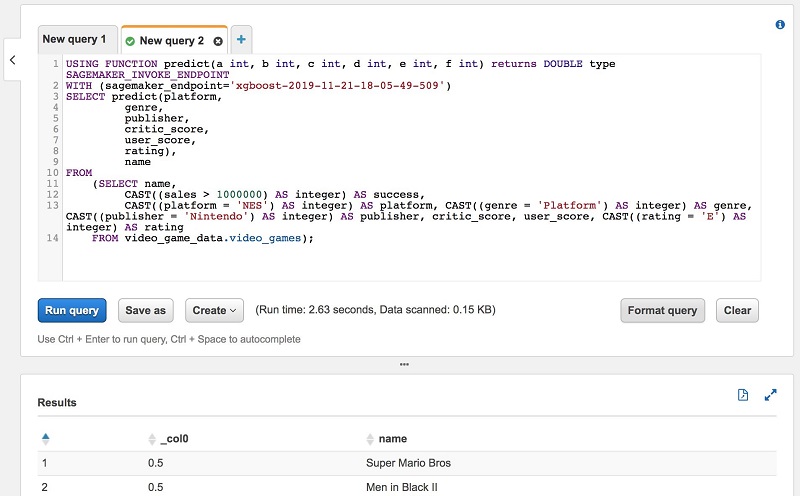
Prepare data for model-training and invoke machine learning models with Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Amazon Athena has announced a public preview of a new feature that provides an easy […]

Query any data source with Amazon Athena’s new federated query
April 2024: This post was reviewed for accuracy. Organizations today use data stores that are the best fit for the applications they build. For example, for an organization building a social network, a graph database such as Amazon Neptune is likely the best fit when compared to a relational database. Similarly, for workloads that require […]