AWS Big Data Blog
Category: AWS Glue

Identify source schema changes using AWS Glue
In today’s world, organizations are collecting an unprecedented amount of data from all kinds of different data sources, such as transactional data stores, clickstreams, log data, IoT data, and more. This data is often in different formats, such as structured data or unstructured data, and is usually referred to as the three Vs of big […]

Create single output files for recipe jobs using AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. AWS Glue DataBrew offers over 350 pre-built transformations to automate data preparation tasks (such as filtering anomalies, standardizing formats, and correcting invalid values) that would otherwise require days or weeks writing hand-coded transformations. You can now choose single or multiple output files instead of autogenerated files for […]

Crawl Delta Lake tables using AWS Glue crawlers
June 2023: This post was reviewed and updated for accuracy. In recent evolution in data lake technologies, it became popular to bring ACID (atomicity, consistency, isolation, and durability) transactions on Amazon Simple Storage Service (Amazon S3). You can achieve that by introducing open-source data lake formats such as Apache Hudi, Apache Iceberg, and Delta Lake. […]

Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks
Enterprise customers are modernizing their data warehouses and data lakes to provide real-time insights, because having the right insights at the right time is crucial for good business outcomes. To enable near-real-time decision-making, data pipelines need to process real-time or near-real-time data. This data is sourced from IoT devices, change data capture (CDC) services like […]

Set up and monitor AWS Glue crawlers using the enhanced AWS Glue UI and crawler history
A data lake is a centralized, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. Setting up and managing data lakes today involves a lot of manual, complicated, and time-consuming tasks. AWS Glue and AWS Lake Formation make it easy to build, secure, and manage data […]

Set up federated access to Amazon Athena for Microsoft AD FS users using AWS Lake Formation and a JDBC client
Tens of thousands of AWS customers choose Amazon Simple Storage Service (Amazon S3) as their data lake to run big data analytics, interactive queries, high-performance computing, and artificial intelligence (AI) and machine learning (ML) applications to gain business insights from their data. On top of these data lakes, you can use AWS Lake Formation to […]

Introducing AWS Glue interactive sessions for Jupyter
Interactive Sessions for Jupyter is a new notebook interface in the AWS Glue serverless Spark environment. Starting in seconds and automatically stopping compute when idle, interactive sessions provide an on-demand, highly-scalable, serverless Spark backend to Jupyter notebooks and Jupyter-based IDEs such as Jupyter Lab, Microsoft Visual Studio Code, JetBrains PyCharm, and more. Interactive sessions replace […]

AWS Glue Python shell now supports Python 3.9 with a flexible pre-loaded environment and support to install additional libraries
AWS Glue is the central service of an AWS modern data architecture. It is a serverless data integration service that allows you to discover, prepare, and combine data for analytics and machine learning. AWS Glue offers you a comprehensive range of tools to perform ETL (extract, transform, and load) at the right scale. AWS Glue […]
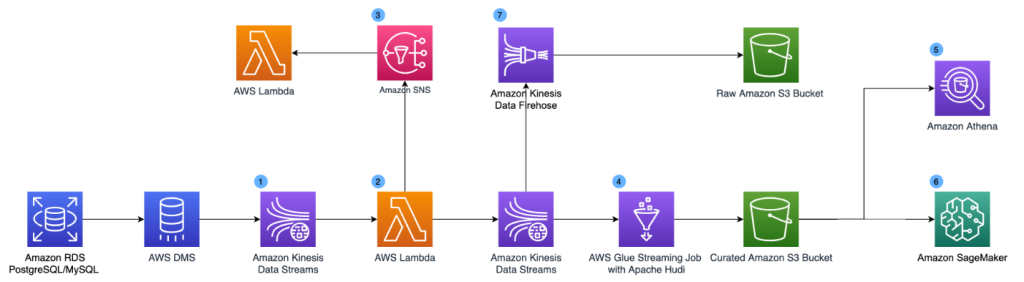
How NerdWallet uses AWS and Apache Hudi to build a serverless, real-time analytics platform
This is a guest post by Kevin Chun, Staff Software Engineer in Core Engineering at NerdWallet. NerdWallet’s mission is to provide clarity for all of life’s financial decisions. This covers a diverse set of topics: from choosing the right credit card, to managing your spending, to finding the best personal loan, to refinancing your mortgage. […]

Introducing AWS Glue Flex jobs: Cost savings on ETL workloads
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores. Typically, these […]