AWS Big Data Blog
Category: Analytics

How AWS Data Lab helped BMW Financial Services design and build a multi-account modern data architecture
This post is co-written by Martin Zoellner, Thomas Ehrlich and Veronika Bogusch from BMW Group. BMW Group and AWS announced a comprehensive strategic collaboration in 2020. The goal of the collaboration is to further accelerate BMW Group’s pace of innovation by placing data and analytics at the center of its decision-making. A key element of […]
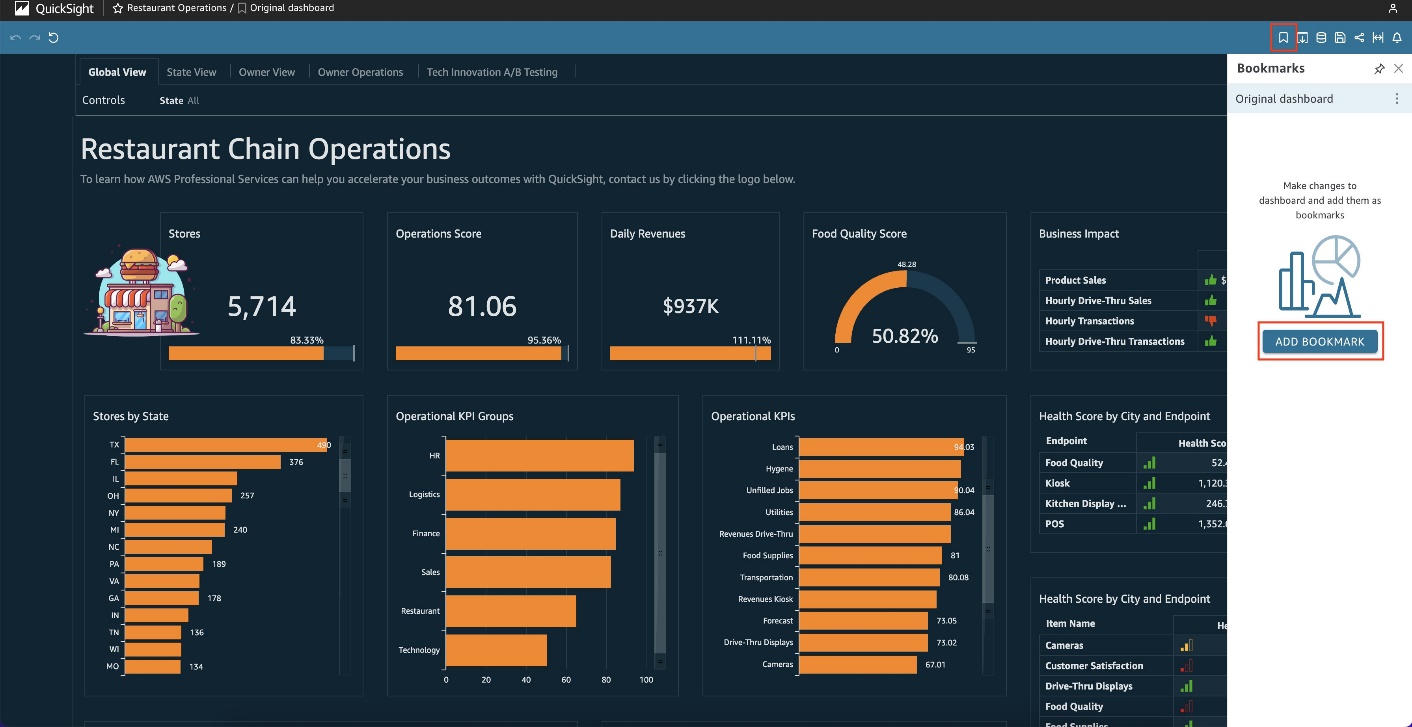
Customize Amazon QuickSight dashboards with the new bookmarks functionality
Amazon QuickSight users now can add bookmarks in dashboards to save customized dashboard preferences into a list of bookmarks for easy one-click access to specific views of the dashboard without having to manually make multiple filter and parameter changes every time. Combined with the “Share this view” functionality, you can also now share your bookmark […]

Get a quick start with Apache Hudi, Apache Iceberg, and Delta Lake with Amazon EMR on EKS
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can keep your data as is in your object store or file-based storage without having to first structure the data. Additionally, you can run different types of analytics against your loosely formatted data […]

Automate ETL jobs between Amazon RDS for SQL Server and Azure Managed SQL using AWS Glue Studio
Nowadays many customers are following a multi-cloud strategy. They might choose to use various cloud-managed services, such as Amazon Relational Database Service (Amazon RDS) for SQL Server and Azure SQL Managed Instances, to perform data analytics tasks, but still use traditional extract, transform, and load (ETL) tools to integrate and process the data. However, traditional ETL tools may […]

Run a data processing job on Amazon EMR Serverless with AWS Step Functions
Update Feb 2023: AWS Step Functions adds direct integration for 35 services including Amazon EMR Serverless. In the current version of this blog, we are able to submit an EMR Serverless job by invoking the APIs directly from a Step Functions workflow. We are using the Lambda only for polling the status of the job […]

Upgrade Amazon EMR Hive Metastore from 5.X to 6.X
If you are currently running Amazon EMR 5.X clusters, consider moving to Amazon EMR 6.X as it includes new features that helps you improve performance and optimize on cost. For instance, Apache Hive is two times faster with LLAP on Amazon EMR 6.X, and Spark 3 reduces costs by 40%. Additionally, Amazon EMR 6.x releases […]

Enable self-service visual data integration and analysis for fund performance using AWS Glue Studio and Amazon QuickSight
June 2023: This post was reviewed and updated for accuracy. IMM (Institutional Money Market) is a mutual fund that invests in highly liquid instruments, cash, and cash equivalents. IMM funds are large financial intermediaries that are crucial to financial stability in the US. Due to its criticality, IMM funds are highly regulated under the security […]

Talk to your data: Query your data lake with Amazon QuickSight Q
Amazon QuickSight Q uses machine learning (ML) and natural language technology to empower you to ask business questions about your data and get answers instantly. You can simply enter your questions (for example, “What is the year-over-year sales trend?”) and get the answer in seconds in the form of a QuickSight visual. Some business questions […]

Design considerations for Amazon EMR on EKS in a multi-tenant Amazon EKS environment
Many AWS customers use Amazon Elastic Kubernetes Service (Amazon EKS) in order to take advantage of Kubernetes without the burden of managing the Kubernetes control plane. With Kubernetes, you can centrally manage your workloads and offer administrators a multi-tenant environment where they can create, update, scale, and secure workloads using a single API. Kubernetes also […]

Detect and process sensitive data using AWS Glue Studio
Data lakes offer the possibility of sharing diverse types of data with different teams and roles to cover numerous use cases. This is very important in order to implement a data democratization strategy and incentivize the collaboration between lines of business. When a data lake is being designed, one of the most important aspects to […]