AWS Big Data Blog
Category: Analytics

Understanding the JVMMemoryPressure metric changes in Amazon OpenSearch Service
This blog post was last reviewed and updated September 2022 with OldGenJVMMemoryPressure, MasterOldGenJVMMemoryPressure and WarmOldGenJVMMemoryPressure metrics to trace usage of old gen. Amazon OpenSearch Service is a managed service that makes it easy to secure, deploy, and operate OpenSearch and legacy Elasticsearch clusters at scale. In the latest service software release of Amazon OpenSearch Service, […]
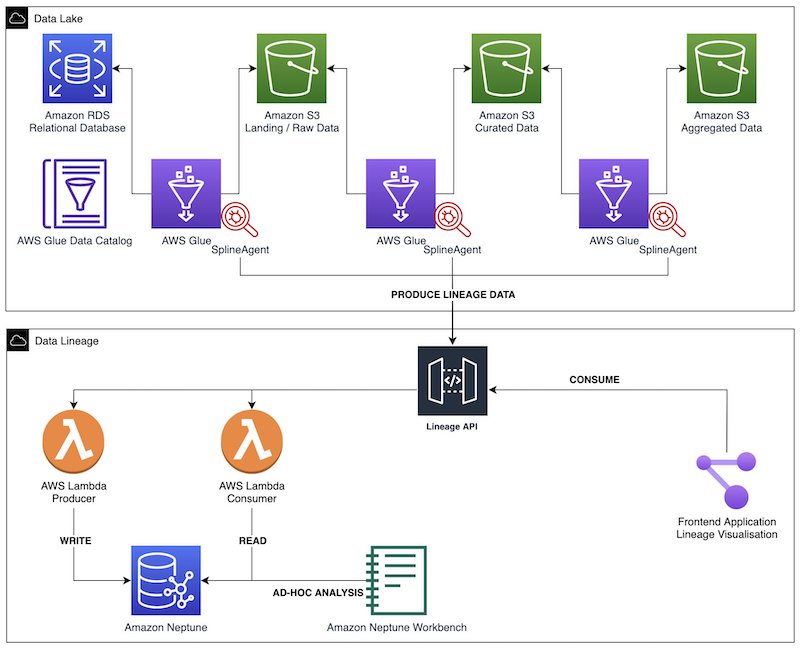
Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Spline
Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by […]

Use Amazon CodeGuru Profiler to monitor and optimize performance in Amazon Kinesis Data Analytics applications for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon Kinesis Data Analytics makes it easy to transform and analyze streaming data and gain actionable insights in real time with Apache Flink. Apache Flink is an […]
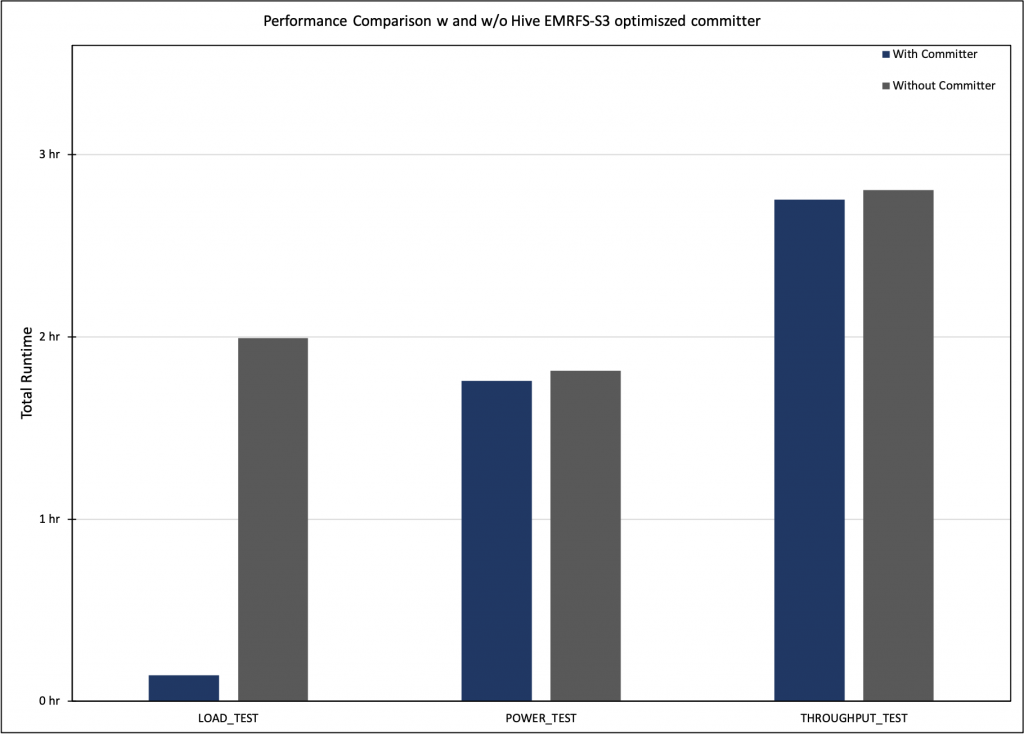
Up to 15 times improvement in Hive write performance with the Amazon EMR Hive zero-rename feature
Our customers use Apache Hive on Amazon EMR for large-scale data analytics and extract, transform, and load (ETL) jobs. Amazon EMR Hive uses Apache Tez as the default job execution engine, which creates Directed Acyclic Graphs (DAGs) to process data. Each DAG can contain multiple vertices from which tasks are created to run the application […]

What to consider when migrating data warehouse to Amazon Redshift
Customers are migrating data warehouses to Amazon Redshift because it’s fast, scalable, and cost-effective. However, data warehouse migration projects can be complex and challenging. In this post, I help you understand the common drivers of data warehouse migration, migration strategies, and what tools and services are available to assist with your migration project. Let’s first […]

Improve reusability and security using Amazon Athena parameterized queries
Amazon Athena is a serverless interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL, and you only pay for the amount of data scanned by your queries. If you use SQL to analyze your business on a daily basis, you may find yourself repeatedly […]

Federated access to Amazon Redshift clusters in AWS China Regions with Active Directory Federation Services
Many customers already manage user identities through identity providers (IdPs) for single sign-on access. With an IdP such as Active Directory Federation Services (AD FS), you can set up federated access to Amazon Redshift clusters as a mechanism to control permissions for the database objects by business groups. This provides a seamless user experience, and centralizes the governance […]
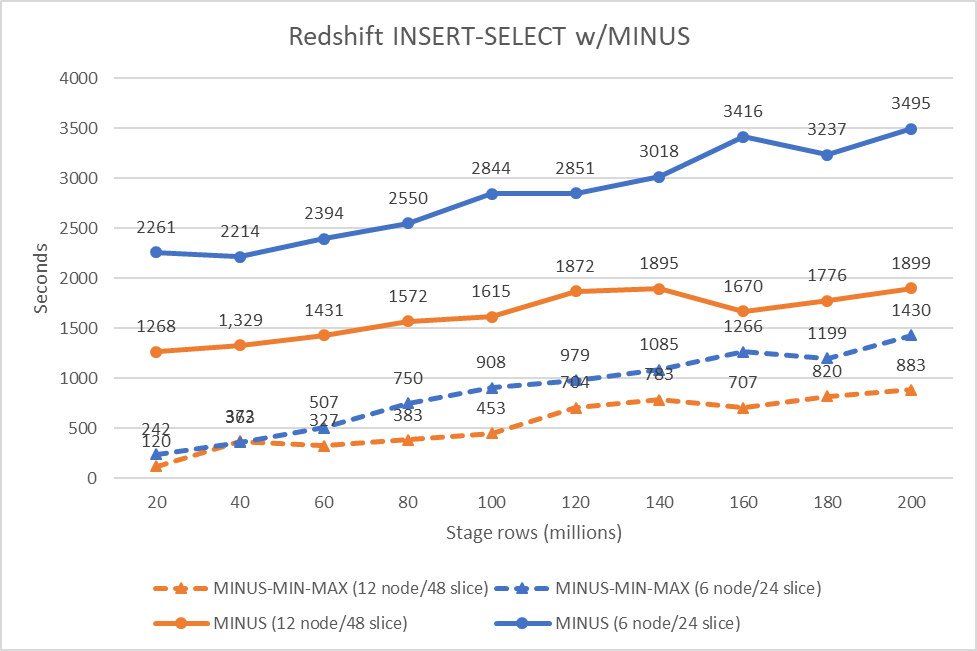
Accelerate your data warehouse migration to Amazon Redshift – Part 5
This is the fifth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift. Check out the all the posts in this series: […]

Back up and restore Kafka topic data using Amazon MSK Connect
This blog is only meant to be used as a reference for backing up and restoring data for an Amazon MSK cluster. AWS does not offer any support for it. You can use Apache Kafka to run your streaming workloads. Kafka provides resiliency to failures and protects your data out of the box by replicating […]

Migrate your Amazon Redshift cluster to another AWS Region
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS designed hardware and machine […]