AWS Big Data Blog
How Optus improves broadband and mobile customer experience using the Network Data Analytics platform on AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
This is a guest blog post co-written by Rajagopal Mahendran, Development Manager at the Optus IT Innovation Team.
Optus is part of The Singtel group, which operates in one of the world’s fastest growing and most dynamic regions, with a presence in 21 countries. Optus provides not only core telecom services, but also an extensive range of digital solutions, including cloud, cybersecurity, and digital advertising to enterprises, as well as entertainment and mobile financial services to millions of consumers. Optus provides mobile communication services to over 10.4 million customers and broadband services to over 1.1 million homes and businesses. In addition, Optus Sport connects close to 1 million fans to Premier League, international football, and fitness content.
In this post, we look at how Optus used Amazon Kinesis to ingest and analyze network related data in a data lake on AWS and improve customer experience and the service planning process.
The challenge
A common challenge for telecommunication providers is to form an accurate, real-time view of quality of service and issues experienced by their customers. Home network and broadband connectivity quality has a significant impact on customer productivity and satisfaction, especially considering the increased reliance on home networks for work, connecting with family and friends, and entertainment during the COVID-19 pandemic.
Additionally, network operations and planning teams often don’t have access to the right data and insights to plan new rollouts and manage their current fleet of devices.
The network analytics platform provides troubleshooting and planning data and insights to Optus teams and their customers in near-real time, which helps reduce mean time to rectify and enhance the customer experience. With the right data and insights, customers have a better experience because instead of starting a support call with a lot of questions, the support staff and the customer have a current and accurate view of the services and the customer’s home network.
Service owner teams within Optus can also use the insights and trends derived from this platform to better plan for the future and provide higher-quality service to customers.
Design considerations
To address this challenge and its requirements, we embarked on a project to transform our current batch collection and processing system to a stream-based, near-real-time processing system, and introduce APIs for insights so that support systems and customer applications can show the latest snapshot of the network and service status.
We had the following functional and non-functional requirements:
- The new platform must be capable of supporting data capture from future types of customer equipment as well as new ways of ingestion (new protocols and frequency) and new formats of data.
- It should support multiple consumers (a near-real-time API for support staff and customer applications and operational and business reporting) to consume data and generate insights. The aim is for the platform to proactively detect issues and generate appropriate alerting to support staff as well as customers.
- After the data arrives, insights from the data should be ready in the form of an API in a few seconds (5 seconds maximum).
- The new platform should be resilient enough to continue processing when parts of the infrastructure fail, such as nodes or Availability Zones.
- It can support an increased number of devices and services as well as more frequent collection from the devices.
- A small cross-functional team across business and technology will build and run this platform. We need to ensure minimal infrastructure and operational overhead in the long run.
- The pipeline should be highly available and allow for new deployments with no downtime.
Solution overview
With the goal of the platform and design considerations in mind, we decided to use higher-order services and serverless services from AWS where possible, to avoid unnecessary operational overhead for our team and focus on the core business needs. This includes using the Kinesis family of services for stream ingestion and processing; AWS Lambda for processing; Amazon DynamoDB, Amazon Relational Database Service (Amazon RDS), and Amazon Simple Storage Service (Amazon S3) for data persistence; and AWS Elastic Beanstalk and Amazon API Gateway for application and API serving. The following diagram shows the overall solution.
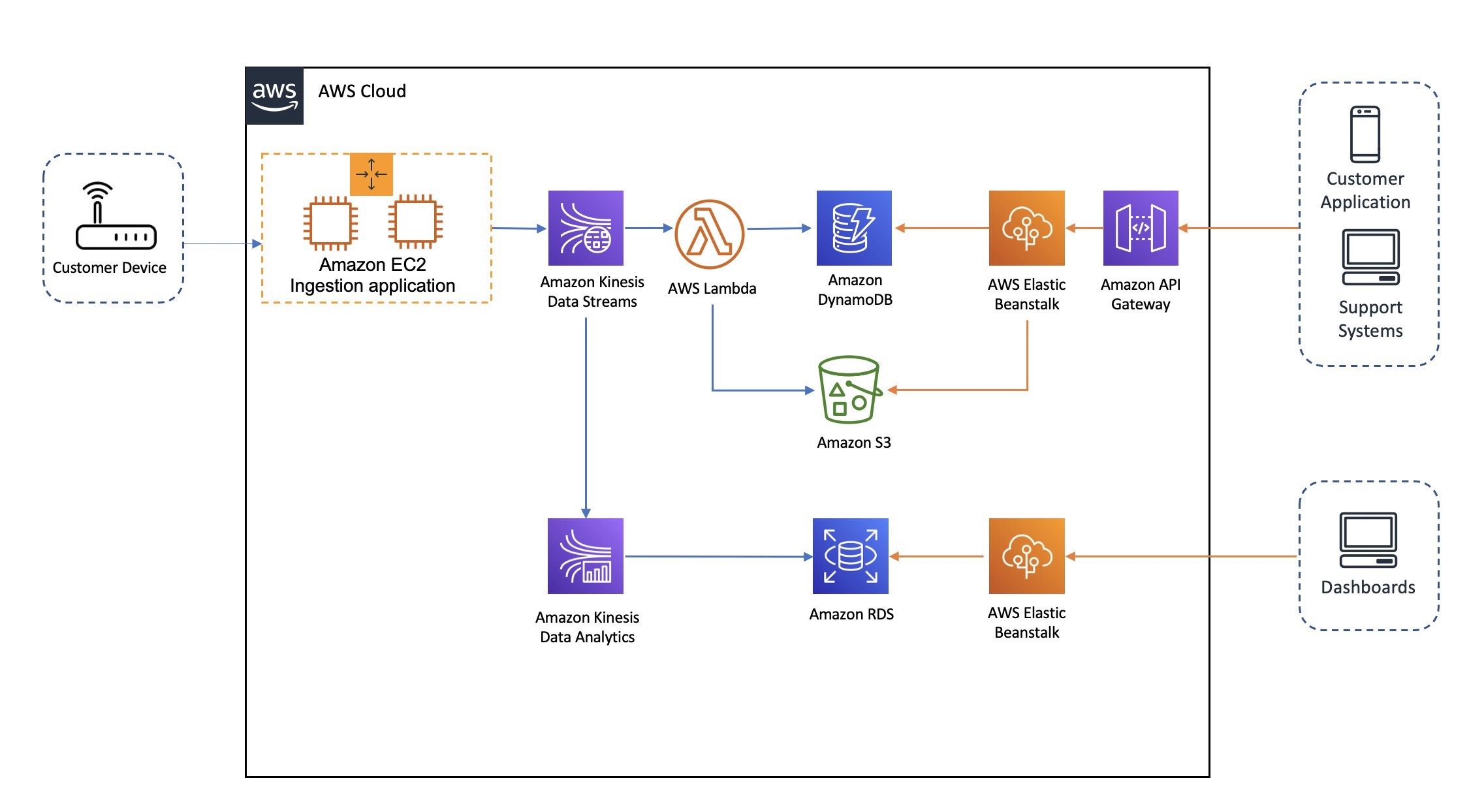
The solution ingests log files from thousands of customer network equipment (home routers) in predefined periods. The customer equipment is only capable of sending simple HTTP PUT and POST requests to transfer log files. To receive these files, we use a Java application running in an Auto Scaling group of Amazon Elastic Compute Cloud (Amazon EC2) instances. After some initial checks, the receiver application performs cleansing and formatting, then it streams the log files to Amazon Kinesis Data Streams.
We intentionally use a custom receiver application in the ingestion layer to provide flexibility in supporting different devices and file formats.
To understand the rest of the architecture, let’s take a look at the expected insights. The platform produces two types of insights:
- Individual insights – Questions answered in this category include:
- How many errors has a particular customer device experienced in the last 15 minutes?
- What was the last error?
- How many devices are currently connected at a particular customer home?
- What’s the transfer/receive rate as captured by a particular customer device?
- Base insights – Pertaining to a group or the whole user base, questions in this category include:
- How many customer devices reported service disruption in the past 24 hours?
- Which device types (models) have experienced the highest number of errors in the past 6 months?
- After last night’s patch update on a group of devices, have they reported any errors? Was the maintenance successful?
The top lane in the architecture shows the pipeline that generates the individual insights.
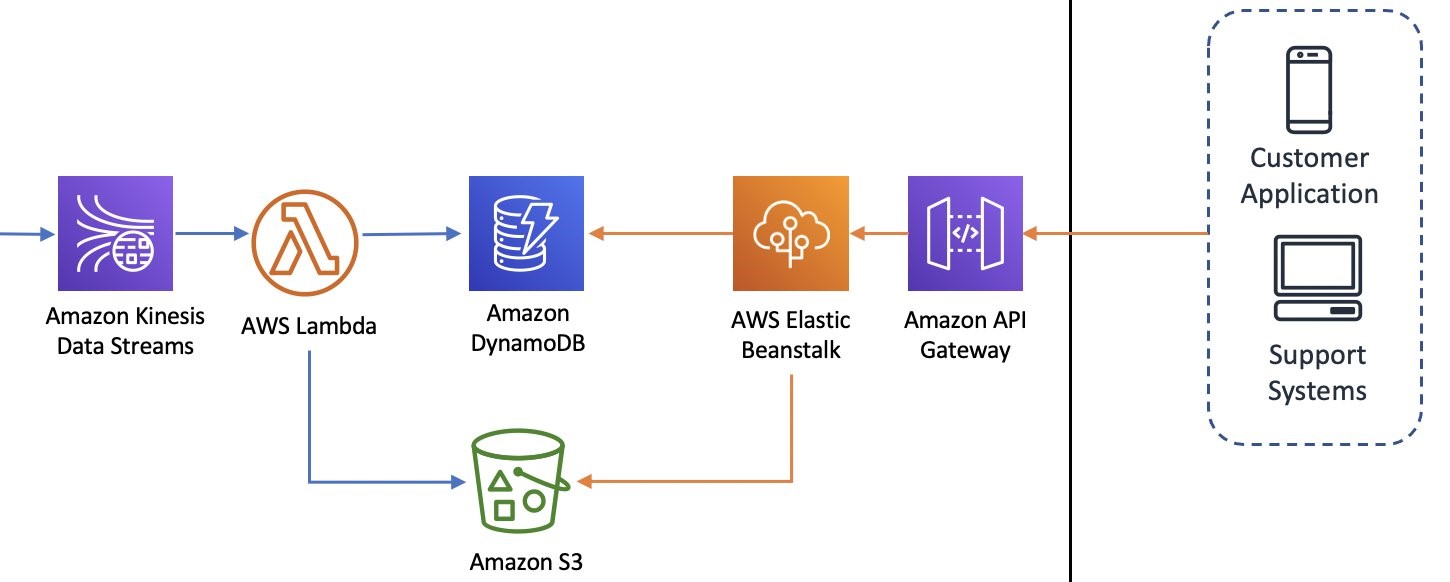
The event source mapping of the Lambda function is configured to consume records from the Kinesis data stream. This function reads the records, formats, and prepares them based on the insights required. Finally, it stores the results in the Amazon S3 location and also updates a DynamoDB table that maintains a summary and the metadata of the actual data stored in Amazon S3.
To optimize performance, we configured two metrics in the Lambda event source mapping:
- Batch size – Shows the number of records to send to the function in each batch, which helps achieve higher throughput
- Concurrent batches per shard – Processes multiple batches from the same shard concurrently, which helps with faster processing
Finally, the API is provided via API Gateway and runs on a Spring Boot application that is hosted on Elastic Beanstalk. In the future, we may need to keep state between API calls, which is why we use Elastic Beanstalk instead of a serverless application.
The bottom lane in the architecture is the pipeline that generates base reports.
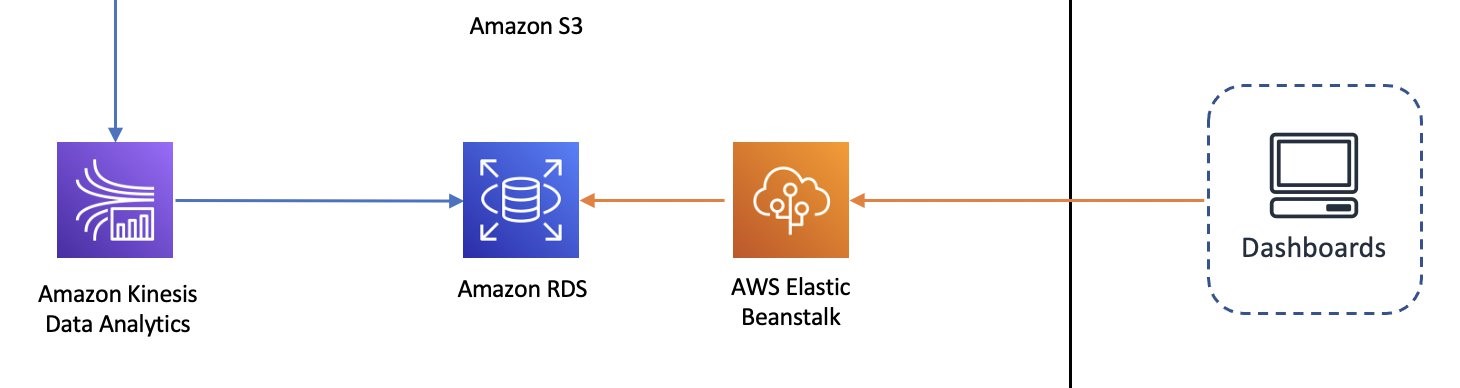
We use Amazon Kinesis Data Analytics, running stateful computation on streaming data, to summarize certain metrics like transfer rates or error rates in given time windows. These summaries are then pushed to an Amazon Aurora database with a data model that’s suitable for dashboarding and reporting purposes.
The insights are then presented in dashboards using a web application running on Elastic Beanstalk.
Lessons learned
Using serverless patterns and higher-order services, in particular Lambda, Kinesis Data Streams, Kinesis Data Analytics, and DynamoDB, provided a lot of flexibility in our architecture and helped us move more towards microservices rather than big monolith batch jobs.
This shift also helped us dramatically decrease our operational and service management overhead. For example, over the last several months since the launch, customers of this platform didn’t experience any service disruption.
This solution also enabled us to adopt more DevOps and agile ways of working, in the sense that a single small team develops and runs the system. This in turn enabled the organization to be more agile and innovative in this domain.
We also discovered some technical tips through the course of development and production that are worth sharing:
- Monitor your streaming pipeline end to end for potential throttling.
- Do capacity planning properly on your target data store to avoid back-pressure. We did so by switching to on-demand mode instead of manually provisioning capacity on our DynamoDB tables.
- As mentioned in the architecture section, we configured Lambda event source mapping to ensure the best throughput and speed in our pipeline. For more information about stream processing with Lambda, see Best practices for consuming Amazon Kinesis Data Streams using AWS Lambda.
Outcomes and benefits
We now have near-real-time visibility of our fixed and mobile networks performance as experienced by our customers. In the past, we only had data that came in batch mode with a delay and also only from our own network probes and equipment.
With the near-real-time view of the network when changes occur, our operational teams can also carry out upgrades and maintenance across the fleet of customer devices with higher confidence and frequency.
Lastly, our planning teams use these insights to form an accurate, up-to-date performance view of various equipment and services. This leads to higher-quality service for our customers at better prices because our service planning teams are enabled to optimize cost, better negotiate with vendors and service providers, and plan for the future.
Looking ahead
With the network analytics platform in production for several months and stable now, there is demand for more insights and new use cases. For example, we’re looking into a mobile use case to better manage capacity at large-scale events (such as sporting events). The aim is for our teams to be data driven and able to react in near-real time to capacity needs in these events.
Another area of demand is around predictive maintenance: we are looking to introduce machine learning into these pipelines to help drive insights faster and more accurately by using the AWS Machine Learning portfolio of services.
About the authors
 Rajagopal Mahendran is a Development Manager at the Optus IT Innovation Team. Mahendran has over 14 years of experience in various organizations delivering enterprise applications from medium-scale to very large-scale using proven to cutting-edge technologies in big data, streaming data applications, mobile, and cloud native applications. His passion is to power innovative ideas using technology for better living. In his spare time, he loves bush walking and swimming.
Rajagopal Mahendran is a Development Manager at the Optus IT Innovation Team. Mahendran has over 14 years of experience in various organizations delivering enterprise applications from medium-scale to very large-scale using proven to cutting-edge technologies in big data, streaming data applications, mobile, and cloud native applications. His passion is to power innovative ideas using technology for better living. In his spare time, he loves bush walking and swimming.
 Mostafa Safipour is a Solutions Architect at AWS based out of Sydney. He works with customers to realize business outcomes using technology and AWS. Over the past decade he has helped many large organizations in the ANZ region build their data, digital, and enterprise workloads on AWS.
Mostafa Safipour is a Solutions Architect at AWS based out of Sydney. He works with customers to realize business outcomes using technology and AWS. Over the past decade he has helped many large organizations in the ANZ region build their data, digital, and enterprise workloads on AWS.
 Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.
Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.