AWS Big Data Blog
How Volkswagen streamlined access to data across multiple data lakes using Amazon DataZone – Part 1
Over the years, organizations have invested in creating purpose-built, cloud-based data lakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple data lakes, each built on different technology stacks. A data mesh addresses these issues with four principles: domain-oriented decentralized data ownership and architecture, treating data as a product, providing self-serve data infrastructure as a platform, and implementing federated governance. Data mesh enables organizations to organize around data domains with a focus on delivering data as a product.
In 2019, Volkswagen AG (VW) and Amazon Web Services (AWS) formed a strategic partnership to co-develop the Digital Production Platform (DPP), aiming to enhance production and logistics efficiency by 30 percent while reducing production costs by the same margin. The DPP was developed to streamline access to data from shop-floor devices and manufacturing systems by handling integrations and providing standardized interfaces. However, as applications evolved on the platform, a significant challenge emerged: sharing data across applications stored in multiple isolated data lakes in Amazon Simple Storage Service (Amazon S3) buckets in individual AWS accounts without having to consolidate data into a central data lake. Another challenge is discovering available data stored across multiple data lakes and facilitating a workflow to request data access across business domains within each plant. The current method is largely manual, relying on emails and general communication, which not only increases overhead but also varies from one use case to another in terms of data governance. This blog post introduces Amazon DataZone and explores how VW used it to build their data mesh to enable streamlined data access across multiple data lakes. It focuses on the key aspect of the solution, which was enabling data providers to automatically publish data assets to Amazon DataZone, which served as the central data mesh for enhanced data discoverability. Additionally, the post provides code to guide you through the implementation.
Introduction to Amazon DataZone
Amazon DataZone is a data management service that makes it faster and easier for customers to catalog, discover, share, and govern data stored across AWS, on premises, and third-party sources. Key features of Amazon DataZone include a business data catalog that allows users to search for published data, request access, and start working on data in days instead of weeks. Amazon DataZone projects enable collaboration with teams through data assets and the ability to manage and monitor data assets across projects. It also includes the Amazon DataZone portal, which offers a personalized analytics experience for data assets through a web-based application or API. Lastly, Amazon DataZone governed data sharing ensures that the right data is accessed by the right user for the right purpose with a governed workflow.
Architecture for Data Management with Amazon DataZone
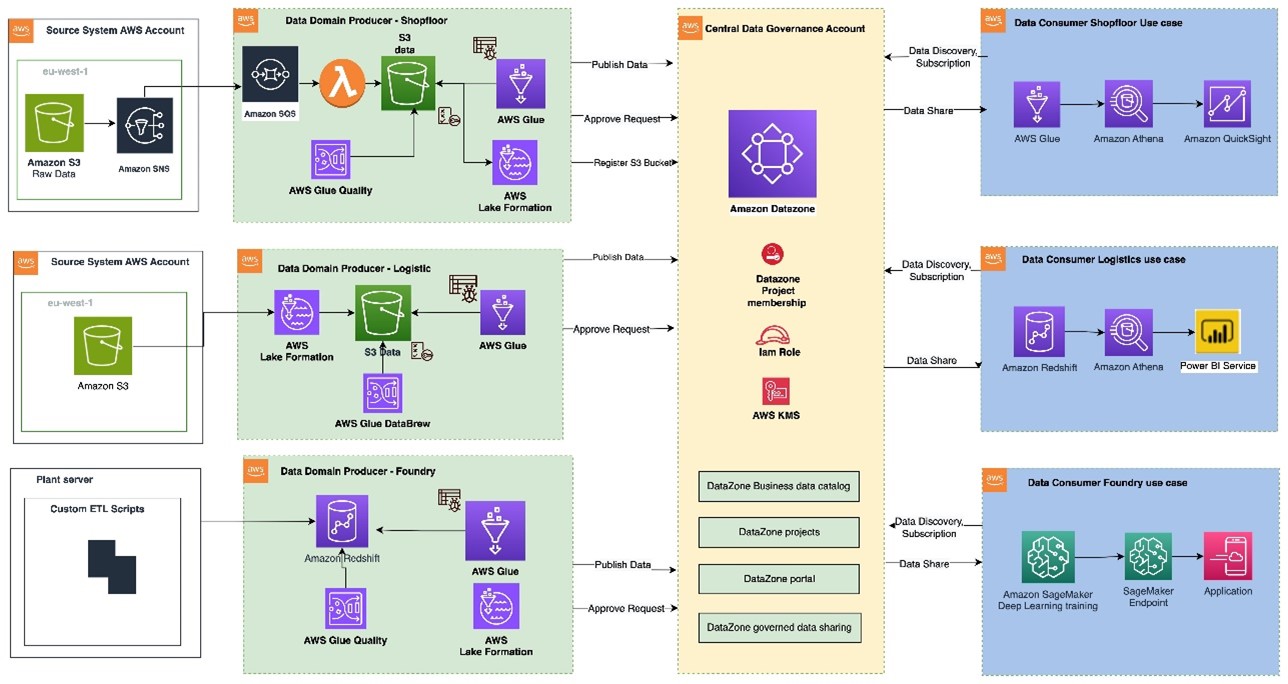
Figure 1: Data mesh pattern implementation on AWS using Amazon DataZone
The architecture diagram (Figure 1) represents a high-level design based on the data mesh pattern. It separates source systems, data domain producers (data publishers), data domain consumers (data subscribers), and central governance to highlight key aspects. This cross-account data mesh architecture aims to create a scalable foundation for data platforms, supporting producers and consumers with consistent governance.
- A data domain producer resides in an AWS account and uses Amazon S3 buckets to store raw and transformed data. Producers ingest data into their S3 buckets through pipelines they manage, own, and operate. They are responsible for the full lifecycle of the data, from raw capture to a form suitable for external consumption.
- A data domain producer maintains its own ETL stack using AWS Glue, AWS Lambda to process, AWS Glue Databrew to profile the data and prepare the data asset (data product) before cataloguing it into AWS Glue Data Catalog in their account.
- A second pattern could be that a data domain producer prepares and stores the data asset as table within Amazon Redshift using AWS S3 Copy.
- Data domain producers publish data assets using datasource run to Amazon DataZone in the Central Governance account. This populates the technical metadata in the business data catalog for each data asset. The business metadata, can be added by business users to provide business context, tags, and data classification for the datasets. Producers control what to share, for how long, and how consumers interact with it.
- Producers can register and create catalog entries with AWS Glue from all their S3 buckets. The central governance account securely shares datasets between producers and consumers via metadata linking, with no data (except logs) existing in this account. Data ownership remains with the producer.
- With Amazon DataZone, once data is cataloged and published into the DataZone domain, it can be shared with multiple consumer accounts.
- The Amazon DataZone Data portal provides a personalized view for users to discover/search and submit requests for subscription of data assets using a web-based application. The data domain producer receives the notification of subscription requests in the Data portal and can approve/reject the requests.
- Once approved, the consumer account can read and further process data assets to implement various use cases with AWS Lambda, AWS Glue, Amazon Athena, Amazon Redshift query editor v2, Amazon QuickSight (Analytics use cases) and with Amazon Sagemaker (Machine learning use cases).
Manual process to publish data assets to Amazon DataZone
To publish a data asset from the producer account, each asset must be registered in Amazon DataZone as a data source for consumer subscription. The Amazon DataZone User Guide provides detailed steps to achieve this. In the absence of an automated registration process, all required tasks must be completed manually for each data asset.
How to automate publishing data assets from AWS Glue Data Catalog from the producer account to Amazon DataZone
Using the automated registration workflow, the manual steps can be automated for any new data asset that needs to be published in an Amazon DataZone domain or when there’s a schema change in an already published data asset.
The automated solution reduces the repetitive manual steps to publish the data sources (AWS Glue tables) into an Amazon DataZone domain.
Architecture for automated data asset publish
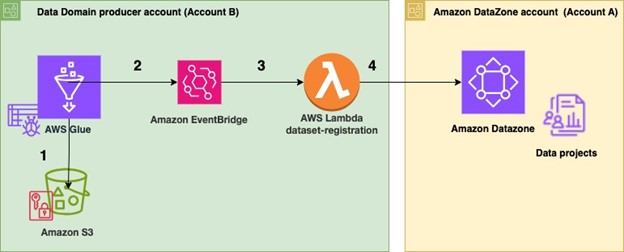
Figure 2 Architecture for automated data publish to Amazon DataZone
To automate publishing data assets:
- In the producer account (Account B), the data to be shared resides in an Amazon S3 bucket (Figure 2). An AWS Glue crawler is configured for the dataset to automatically create the schema using AWS Cloud Development Kit (AWS CDK).
- Once configured, the AWS Glue crawler crawls the Amazon S3 bucket and updates the metadata in the AWS Glue Data Catalog. The successful completion of the AWS Glue crawler generates an event in the default event bus of Amazon EventBridge.
- An EventBridge rule is configured to detect this event and invoke a dataset-registration AWS Lambda function.
- The AWS Lambda function performs all the steps to automatically register and publish the dataset in Amazon Datazone.
Steps performed in the dataset-registration AWS Lambda function
-
- The AWS Lambda function retrieves the AWS Glue database and Amazon S3 information for the dataset from the Amazon Eventbridge event triggered by the successful run of the AWS Glue crawler.
- It obtains the Amazon DataZone Datalake blueprint ID from the producer account and the Amazon DataZone domain ID and project ID by assuming an IAM role in the central governance account where the Amazon Datazone domain exists.
- It enables the Amazon DataZone Datalake blueprint in the producer account.
- It checks if the Amazon Datazone environment already exists within the Amazon DataZone project. If it does not, then it initiates the environment creation process. If the environment exists, it proceeds to the next step.
- It registers the Amazon S3 location of the dataset in Lake Formation in the producer account.
- The function creates a data source within the Amazon DataZone project and monitors the completion of the data source creation.
- Finally, it checks whether the data source sync job in Amazon DataZone needs to be started. If new AWS Glue tables or metadata is created or updated, then it starts the data source sync job.
Prerequisites
As part of this solution, you will publish data assets from an existing AWS Glue database in a producer account into an Amazon DataZone domain for which the following prerequisites need to be performed.
- You need two AWS accounts to deploy the solution.
- One AWS account will act as the data domain producer account (Account B) which will contain the AWS Glue dataset to be shared.
- The second AWS account is the central governance account (Account A), which will have the Amazon DataZone domain and project deployed. This is the Amazon DataZone account.
- Ensure that both the AWS accounts belong to the same AWS Organization
- Remove the IAMAllowedPrincipals permissions from the AWS Lake Formation tables for which Amazon DataZone handles permissions.
- Make sure in both AWS accounts that you have cleared the checkbox for Default permissions for newly created databases and tables under the Data Catalog settings in Lake Formation (Figure 3).

Figure 3: Clear default permissions in AWS Lake Formation
- Sign in to Account A (central governance account) and make sure you have created an Amazon DataZone domain and a project within the domain.
- If your Amazon DataZone domain is encrypted with an AWS Key Management Service (AWS KMS) key, add Account B (producer account) to the key policy with the following actions:
- Ensure you have created an AWS Identity and Access Management (IAM) role that Account B (producer account) can assume and this IAM role is added as a member (as contributor) of your Amazon DataZone project. The role should have the following permissions:
- This IAM role is called
dz-assumable-env-dataset-registration-rolein this example. Adding this role will enable you to successfully run thedataset-registrationLambda function. Replace theaccount-region,account id, andDataZonekmsKeyin the following policy with your information. These values correspond to where your Amazon DataZone domain is created and the AWS KMS key Amazon Resource Name (ARN) used to encrypt the Amazon DataZone domain. - Add the AWS account in the trust relationship of this role with the following trust relationship. Replace
ProducerAccountIdwith the AWS account ID of Account B (data domain producer account).
- This IAM role is called
- The following tools are needed to deploy the solution using AWS CDK:
- Either Bash or ZSH terminal
- Node and NPM using Node Version Manager
- Install Node Version Manager (NVM)
- Install Node version 18.12.0 using following command
-
-
- The node and npm binaries should now be available
- Python
- AWS Command Line Interface (AWS CLI)
- AWS SDK for Python
- AWS CDK
-
Deployment Steps
After completing the pre-requisites, use the AWS CDK stack provided on GitHub to deploy the solution for automatic registration of data assets into DataZone domain
- Clone the repository from GitHub to your preferred IDE using the following commands.
- At the base of the repository folder, run the following commands to build and deploy resources to AWS.
- Sign in to the AWS account B (the data domain producer account) using AWS Command Line Interface (AWS CLI) with your profile name.
- Ensure you have configured the AWS Region in your credential’s configuration file.
- Bootstrap the CDK environment with the following commands at the base of the repository folder. Replace
<PROFILE_NAME>with the profile name of your deployment account (Account B). Bootstrapping is a one-time activity and is not needed if your AWS account is already bootstrapped. - Replace the placeholder parameters (marked with the suffix
_PLACEHOLDER) in the fileconfig/DataZoneConfig.ts(Figure 4).
-
- Amazon DataZone domain and project name of your Amazon DataZone instance. Make sure all names are in lowercase.
- The AWS account ID and Region.
- The assumable IAM role from the prerequisites.
- The deployment role starting with
cfn-xxxxxx-cdk-exec-role-.
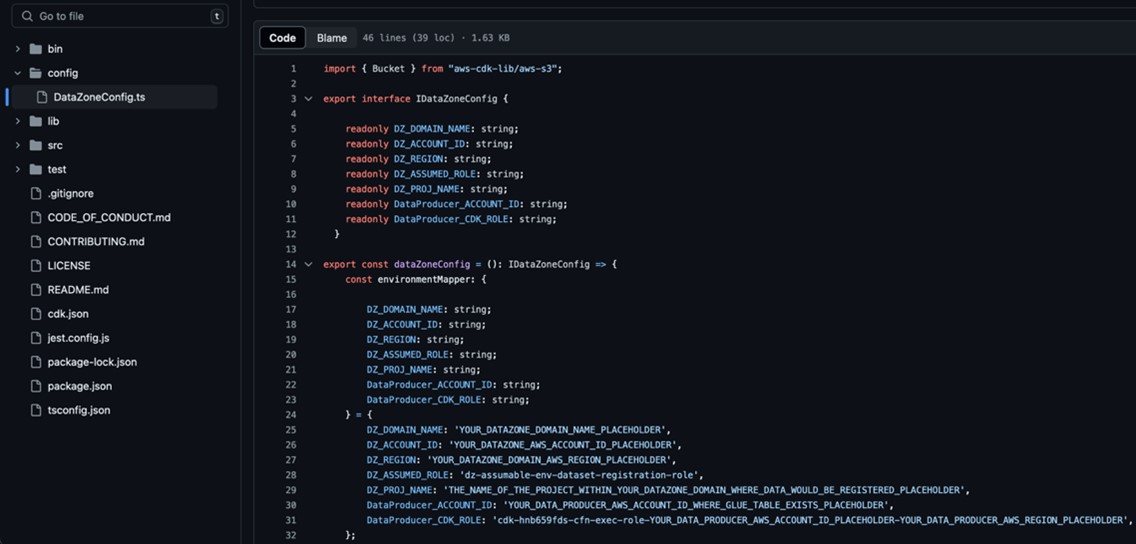
Figure 4: Edit the DataZoneConfig file
- In the AWS Management Console for Lake Formation, select Administrative roles and tasks from the navigation pane (Figure 5) and make sure the IAM role for AWS CDK deployment that starts with
cfn-xxxxxx-cdk-exec-role-is selected as an administrator in Data lake administrators. This IAM role needs permissions in Lake Formation to create resources, such as an AWS Glue database. Without these permissions, the AWS CDK stack deployment will fail.
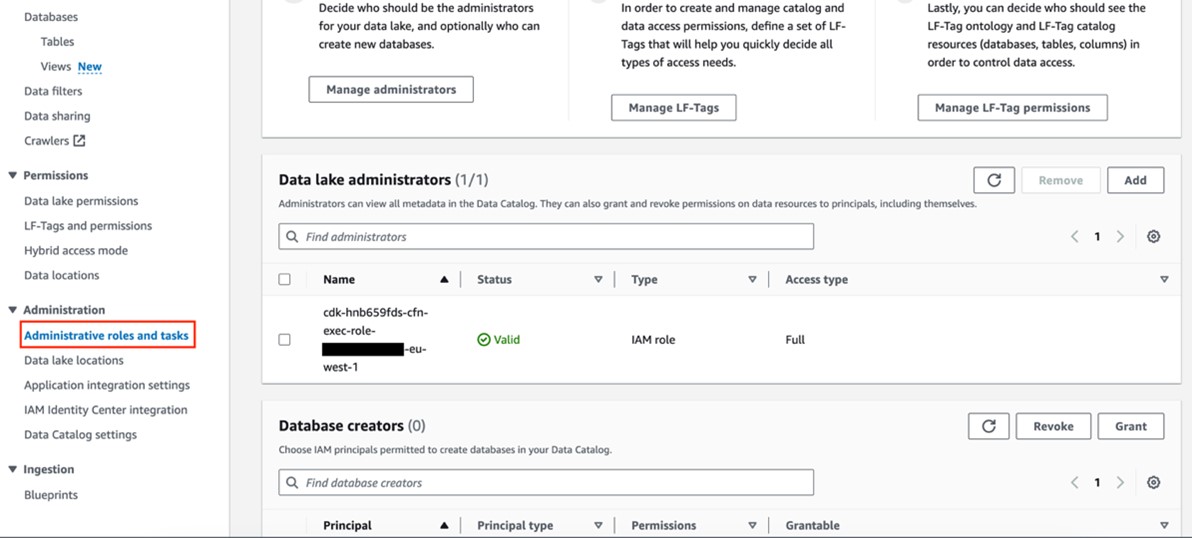
Figure 5: Add cfn-xxxxxx-cdk-exec-role- as a Data Lake administrator
- Use the following command in the base folder to deploy the AWS CDK solution
During deployment, enter y if you want to deploy the changes for some stacks when you see the prompt Do you wish to deploy these changes (y/n)?
- After the deployment is complete, sign in to your AWS account B (producer account) and navigate to the AWS CloudFormation console to verify that the infrastructure deployed. You should see a list of the deployed CloudFormation stacks as shown in Figure 6.
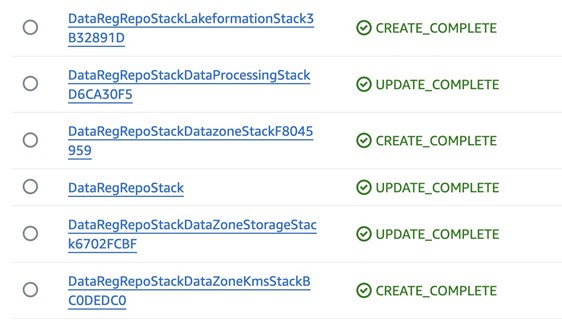
Figure 6: Deployed CloudFormation stacks
Test automatic data registration to Amazon DataZone
To test, we use the Online Retail Transactions dataset from Kaggle as a sample dataset to demonstrate the automatic data registration.
- Download the Online Retail.csv file from Kaggle dataset.
- Login to AWS Account B (producer account) and navigate to the Amazon S3 console, find the
DataZone-test-datasourceS3 bucket, and upload the csv file there (Figure 7).
Figure 7: Upload the dataset CSV file
- The AWS Glue crawler is scheduled to run at a specific time each day. However for testing, you can manually run the crawler by going to the AWS Glue console and selecting Crawlers from the navigation pane. Run the on-demand crawler starting with
DataZone-. After the crawler has run, verify that a new table has been created. - Go to the Amazon DataZone console in AWS account A (central governance account) where you deployed the resources. Select Domains in the navigation pane (Figure 8), then Select and open your domain.

Figure 8: Amazon DataZone domains
- After you open the Datazone Domain, you can find the Amazon Datazone data portal URL in the Summary section (Figure 9). Select and open data portal.

Figure 9: Amazon DataZone data portal URL
- In the data portal find your project (Figure 10). Then select the Data tab at the top of the window.

Figure 10: Amazon DataZone Project overview
- Select the section Data Sources (Figure 11) and find the newly created data source DataZone-testdata-db.

Figure 11: Select Data sources in the Amazon Datazone Domain Data portal
- Verify that the data source has been successfully published (Figure 12).

Figure 12: The data sources are visible in the Published data section
- After the data sources are published, users can discover the published data and can submit a subscription request. The data producer can approve or reject requests. Upon approval, users can consume the data by querying data in Amazon Athena. Figure 13 illustrates data discovery in the Amazon DataZone data portal.

Figure 13: Example data discovery in the Amazon DataZone portal
Clean up
Use the following steps to clean up the resources deployed through the CDK.
- Empty the two S3 buckets that were created as part of this deployment.
- Go to the Amazon DataZone domain portal and delete the published data assets that were created in the Amazon DataZone project by the
dataset-registrationLambda function. - Delete the remaining resources created using the following command in the base folder:
Conclusion
By using AWS Glue and Amazon DataZone, organizations can make their data management easier and allow teams to share and collaborate on data smoothly. Automatically sending AWS Glue data to Amazon DataZone not only makes the process simple but also keeps the data consistent, secure, and well-governed. Simplify and standardize publishing data assets to Amazon DataZone and streamline data management with Amazon DataZone. For guidance on establishing your organization’s data mesh with Amazon DataZone, contact your AWS team today.
About the Authors
 Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud.
Bandana Das is a Senior Data Architect at Amazon Web Services and specializes in data and analytics. She builds event-driven data architectures to support customers in data management and data-driven decision-making. She is also passionate about enabling customers on their data management journey to the cloud.
 Anirban Saha is a DevOps Architect at AWS, specializing in architecting and implementation of solutions for customer challenges in the automotive domain. He is passionate about well-architected infrastructures, automation, data-driven solutions and helping make the customer’s cloud journey as seamless as possible. Personally, he likes to keep himself engaged with reading, painting, language learning and traveling.
Anirban Saha is a DevOps Architect at AWS, specializing in architecting and implementation of solutions for customer challenges in the automotive domain. He is passionate about well-architected infrastructures, automation, data-driven solutions and helping make the customer’s cloud journey as seamless as possible. Personally, he likes to keep himself engaged with reading, painting, language learning and traveling.
 Chandana Keswarkar is a Senior Solutions Architect at AWS, who specializes in guiding automotive customers through their digital transformation journeys by using cloud technology. She helps organizations develop and refine their platform and product architectures and make well-informed design decisions. In her free time, she enjoys traveling, reading, and practicing yoga.
Chandana Keswarkar is a Senior Solutions Architect at AWS, who specializes in guiding automotive customers through their digital transformation journeys by using cloud technology. She helps organizations develop and refine their platform and product architectures and make well-informed design decisions. In her free time, she enjoys traveling, reading, and practicing yoga.
 Sindi Cali is a ProServe Associate Consultant with AWS Professional Services. She supports customers in building data driven applications in AWS.
Sindi Cali is a ProServe Associate Consultant with AWS Professional Services. She supports customers in building data driven applications in AWS.