AWS Big Data Blog

Schedule email reports and configure threshold based-email alerts using Amazon QuickSight
Amazon QuickSight is a cloud-scale business intelligence (BI) service that you can use to deliver easy-to-understand insights to the people you work with, wherever they are. You can build dashboards using combinations of data in the cloud, on premises, in other software as a service (SaaS) apps, and in flat files. Although users can always […]
Accelerate your data warehouse migration to Amazon Redshift – Part 6
This is the sixth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially simplify your migrations from legacy data warehouses to Amazon Redshift. Check out all the previous posts in this series: […]

Scale Amazon QuickSight embedded analytics with new API-based domain allow listing
Amazon QuickSight is a fully-managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards, and share these with tens of thousands of users, either within QuickSight itself or embedded in apps and portals. QuickSight Enterprise Edition recently introduced the ability to dynamically allow list the domains where […]

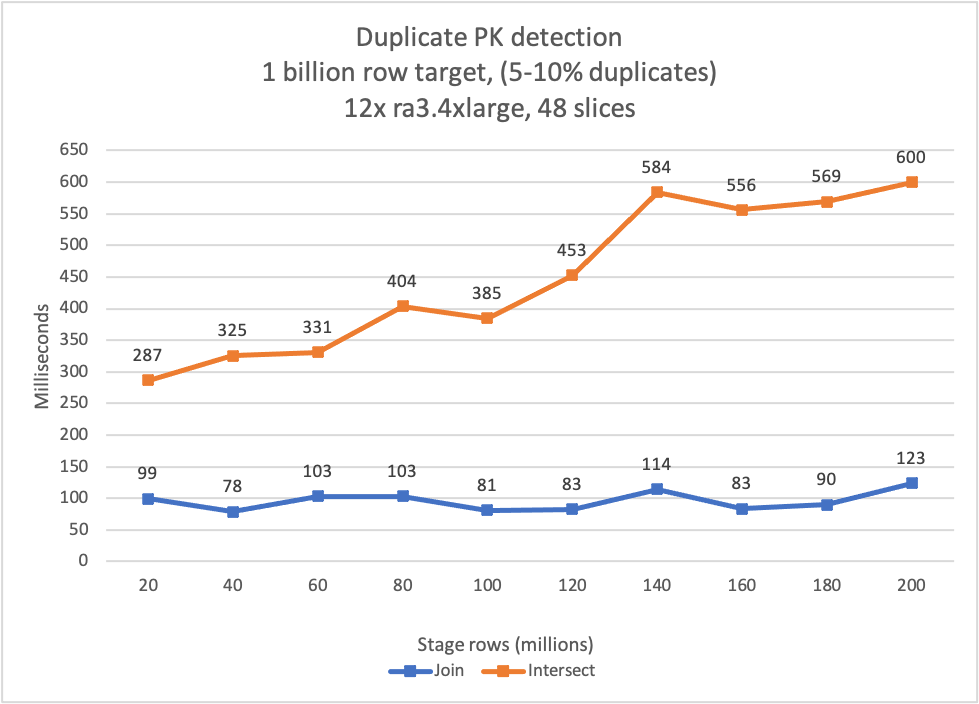
Create a most-recent view of your data lake using Amazon Redshift Serverless
Building a robust data lake is very beneficial because it enables organizations have a holistic view of their business and empowers data-driven decisions. The curated layer of a data lake is able to hydrate multiple homogeneous data products, unlocking limitless capabilities to address current and future requirements. However, some concepts of how data lakes work […]

How SumUp built a low-latency feature store using Amazon EMR and Amazon Keyspaces
This post was co-authored by Vadym Dolin, Data Architect at SumUp. In their own words, SumUp is a leading financial technology company, operating across 35 markets on three continents. SumUp helps small businesses be successful by enabling them to accept card payments in-store, in-app, and online, in a simple, secure, and cost-effective way. Today, SumUp […]

Process Apache Hudi, Delta Lake, Apache Iceberg dataset at scale, part 2: Using AWS Glue Studio Visual Editor
June 2023: This post was reviewed and updated for accuracy. AWS Glue supports native integration with Apache Hudi, Delta Lake, and Apache Iceberg. Refer to Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 2: AWS Glue Studio Visual Editor to learn more. Transactional data lake […]

Simplify analytics on Amazon Redshift using PIVOT and UNPIVOT
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Many customers look to build their data warehouse on Amazon Redshift, and they have many requirements where they want to convert data from row […]

Stream Amazon EMR on EKS logs to third-party providers like Splunk, Amazon OpenSearch Service, or other log aggregators
Spark jobs running on Amazon EMR on EKS generate logs that are very useful in identifying issues with Spark processes and also as a way to see Spark outputs. You can access these logs from a variety of sources. On the Amazon EMR virtual cluster console, you can access logs from the Spark History UI. […]

Integrate Amazon Redshift row-level security with Amazon Redshift native IdP authentication
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. As enterprise customers look to build their data […]

Enable federated governance using Trino and Apache Ranger on Amazon EMR
Managing data through a central data platform simplifies staffing and training challenges and reduces the costs. However, it can create scaling, ownership, and accountability challenges, because central teams may not understand the specific needs of a data domain, whether it’s because of data types and storage, security, data catalog requirements, or specific technologies needed for […]