AWS Compute Blog
Building scalable serverless applications with Amazon S3 and AWS Lambda
Well-designed serverless applications are typically a combination of managed services connected by custom business logic. One of the most powerful combinations for enterprise application development is Amazon S3 and AWS Lambda. S3 is a highly durable, highly available object store that scales to meet your storage needs. Lambda runs custom code in response to events, automatically scaling with the size of the workload. When you use the two services together, they can provide a scalable core for serverless solutions.
This blog post shows how to design and deploy serverless applications designed around S3 events. The solutions presented use AWS services to create scalable serverless architectures, using minimal custom code. This is the conclusion of a series showing how the S3-to-Lambda pattern can implement the following business solutions:
- Translating documents at scale, by using Amazon Translate in response to S3 events.
- Automating data imports to DynamoDB tables using objects stored in an S3 bucket.
- Creating a searchable enterprise document repository, using S3 and Amazon ML services.
- Automating scalable business workflows, integrating S3 and AWS Step Functions.
- Converting call center recordings into useful data for analytics, using S3 with Amazon Transcribe.
Bringing the compute layer to the data
Much traditional software operates by bringing data to the compute layer. This means that processes run on batches of data in files, databases, and other sources. This is inherently harder to scale as data volumes grow, often needing a fleet of servers to scale out at peak times. For the developer, this creates operational overhead to ensure that the compute capacity is keeping pace with the data volume.
The S3-to-Lambda serverless pattern instead brings the compute layer to the data. As data arrives, the compute process scales up and down automatically to meet the demand. This allows developers to focus on building business logic for a single item of data, and the execution at scale is handled by the Lambda service.
The image optimization application is a good example for comparing the traditional and serverless approaches. For a busy media site, capturing hundreds of images per minute in an S3 bucket, the operations overhead becomes clearer. A script running on a server must scale up across multiple instances to keep pace with this level of traffic. Compare this to the Lambda-based approach, which scales on-demand. The code itself does not change, whether it is used for a single image or thousands.
Receiving and processing events from S3 in custom code
S3 raises events when objects are put, copied, or deleted in a bucket. It also raises a broad number of other notifications, such as when lifecycle events occur. You can configure S3 to invoke Lambda from these events by using the S3 console, Lambda console, AWS CLI, or AWS Serverless Application Model (SAM) templates.
S3 passes details of the event, not the object itself, to the Lambda function in a JSON object. This object contains an array of records, so it’s possible to receive more than one S3 event per invocation:

As the Lambda handler may receive more than one record, it should iterate through the records collection. It’s best practice to keep the handler small and generic, calling out to the business logic in a separate function or file:
const processEvent = require('my-custom-logic’)
// A Node.js Lambda handler
exports.handler = async (event) => {
// Capture event – can be used to create mock events
console.log (JSON.stringify(event, null, 2))
// Handle each incoming S3 object in the event
await Promise.all(
event.Records.map(async (event) => {
try {
// Pass each event to the business logic handler
await processEvent(event)
} catch (err) {
console.error('Handler error: ', err)
}
})
)
}
This code example takes advantage of concurrent asynchronous executions available in Node.js but similar constructs are available in many other languages. This means that multiple objects are processed in parallel to minimize the overall function execution time.
Instead of handling and logging any errors within the function’s code, it’s also possible to use destinations for asynchronous invocations. You use an On failure condition to route the error to various potential targets, including another Lambda function or other AWS services. For complex applications or those handling large volumes, this provides greater control for managing events that fail processing.
During the development process, you can debug and test the S3-to-Lambda integration locally. First, capture a sample event during development to create a mock event for local testing. The sample applications in this series each use a test harness so the developer can test the handler on a local machine. The test harness invokes the handler locally, providing mock environment variables:
// Mock event
const event = require('./localTestEvent')
// Mock environment variables
process.env.AWS_REGION = 'us-east-1'
process.env.localTest = true
process.env.language = 'en'
// Lambda handler
const { handler } = require('./app')
const main = async () => {
console.time('localTest')
await handler(event)
console.timeEnd('localTest')
}
main().catch(error => console.error(error))
Scaling up when more data arrives
The Lambda service scales up if S3 sends multiple events simultaneously. How this works depends on several factors. If the target Lambda function has sufficient concurrency available, and if any active instances of the function are already processing events, the Lambda service scales up.

The function does not scale up if the reserved concurrency is set to 1 or the scaling capacity is fully consumed for a Region in your account. In this case, the events from S3 are queued internally until a Lambda instance is available for processing. You can request to increase the regional concurrency limit by submitting a request in the Support Center console. You may also intend to perform one-at-a-time processing by setting the reserved concurrency to 1.

Generally, multiple instances of a function are invoked simultaneously when S3 receives multiple objects, to process the events as quickly as possible. It’s this rapid scaling and parallelization in both S3 and Lambda that make this pattern such a powerful core architecture for many applications.
Amazon SNS and Amazon SQS integrations
The native S3 to Lambda integration provides a reliable way to invoke one function per prefix or suffix-pattern per bucket. For example, invoking a function when object keys end in .pdf in a single bucket. This works well for the vast majority of use-cases but you may want to invoke multiple Lambda functions per S3 event.
In this case, S3 can publish notifications to SNS, where events are delivered to a range of targets. These include Lambda functions, SQS queues, HTTP endpoints, email, text messages and push notifications. SNS provides fan-out capability, enabling one event to be delivered to multiple destinations, such as Lambda functions or web hooks, for example.
In busy applications, the volume of S3 events may be too large for a downstream system, such as a non-serverless service. In this case, you can also use an SQS queue as a notification target. After events are published to a queue, they can be consumed by Lambda functions and other services. The queue acts as a buffer and can help smooth out traffic for systems consuming these events. See the DynamoDB importer repository for an example.
Uploading data to S3 in upstream applications
You may have upstream services in your architecture that generate the data stored in S3. Some upstream workloads have spiky usage patterns and large numbers of users, like web or mobile applications. You may increase the performance and throughput of these workloads by uploading directly to S3. This avoids proxying binary data through an API Gateway endpoint or web server.
For example, for a mobile application uploading user photos, S3 and Lambda can handle the upload process for large of numbers of users:
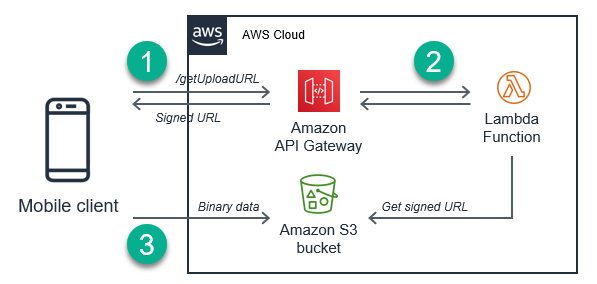
- The upstream process, in this case a mobile client, requests a presigned URL from an API Gateway endpoint.
- This invokes a Lambda function that requests a presigned URL for the S3 bucket, and returns this back via the API call.
- The mobile client sends the data directly to the presigned S3 URL using HTTPS POST. The upload is managed directly by S3.
This simple pattern can be a scalable and cost-effective way to upload large binary data into your applications. After the object successfully uploads, the S3 put event can then asynchronously invoke downstream workflows.
Visit this repository to see an example of a serverless S3 uploader application. You can also see a walkthrough of this process in this YouTube video.
Developing larger applications
As you develop larger serverless applications, it often becomes more practical to split applications into multiple services and repositories for separate teams. Often, individual services must integrate with existing S3 buckets, not create these in the application templates. You may also have to integrate a single service with multiple S3 buckets.
In decoupling larger applications with Amazon EventBridge, I show how you can decouple services within an application using an event bus. This pattern helps separate the producers and consumers of events in your workload. This can make each service become more independent and more resilient to changes with the overall application.
This example demonstrates how the document repository solution can be refactored into several smaller applications that communicate using events. This uses Amazon EventBridge as the event router coordinating the flow. Each application contains a SAM template that defines the EventBridge rule to filter for events, and publishes data back to the event bus after processing is complete.
One of the major benefits to using an event-based architecture is that development teams retain flexibility even as the application grows. It allows developers to separate AWS resources like S3 buckets and DynamoDB tables, from the compute resources, like Lambda functions. This decoupling can simplify the deployment process, help avoid building monoliths, and reduce the cognitive load of developing in large applications.
Conclusion
S3 and Lambda are two highly scalable AWS services that can be powerful when combined in serverless applications. In this post, I summarize many of the patterns shown across this series. I explain the integration pattern and the scaling behavior, and how you can use mock events for local testing and development. You can also use SNS and SQS in some applications for fan-out and buffering of events.
Upstream applications can upload data directly to S3 to achieve greater scalability by avoiding proxies. For larger applications, I show how using an event-based architecture modeled around EventBridge can help decouple application services. This can promote service independence, and help maintain flexibility as applications grow.
To learn more about the S3-to-Lambda architecture pattern, watch the YouTube video series, or explore the articles listed at top of this post.