AWS Compute Blog
Reserving EC2 Capacity across Availability Zones by utilizing On Demand Capacity Reservations (ODCRs)
This post is written by Johan Hedlund, Senior Solutions Architect, Enterprise PUMA.
Many customers have successfully migrated business critical legacy workloads to AWS, utilizing services such as Amazon Elastic Compute Cloud (Amazon EC2), Auto Scaling Groups (ASGs), as well as the use of Multiple Availability Zones (AZs), Regions for Business Continuity, and High Availability.
These critical applications require increased levels of availability to meet strict business Service Level Agreements (SLAs), even in extreme scenarios such as when EC2 functionality is impaired (see Advanced Multi-AZ Resilience Patterns for examples). Following AWS best practices such as architecting for flexibility will help here, but for some more rigid designs there can still be challenges around EC2 instance availability.
In this post, I detail an approach for Reserving Capacity for this type of scenario to mitigate the risk of the instance type(s) that your application needs being unavailable, including code for building it and ways of testing it.
Baseline: Multi-AZ application with restrictive instance needs
To focus on the problem of Capacity Reservation, our reference architecture is a simple horizontally scalable monolith. This consists of a single executable running across multiple instances as a cluster in an Auto Scaling group across three AZs for High Availability.

The application in this example is both business critical and memory intensive. It needs six r6i.4xlarge instances to meet the required specifications. R6i has been chosen to meet the required memory to vCPU requirements.
The third-party application we need to run, has a significant license cost, so we want to optimize our workload to make sure we run only the minimally required number of instances for the shortest amount of time.
The application should be resilient to issues in a single AZ. In the case of multi-AZ impact, it should failover to Disaster Recovery (DR) in an alternate Region, where service level objectives are instituted to return operations to defined parameters. But this is outside the scope for this post.
The problem: capacity during AZ failover
In this solution, the Auto Scaling Group automatically balances its instances across the selected AZs, providing a layer of resilience in the event of a disruption in a single AZ. However, this hinges on those instances being available for use in the Amazon EC2 capacity pools. The criticality of our application comes with SLAs which dictate that even the very low likelihood of instance types being unavailable in AWS must be mitigated.
The solution: Reserving Capacity
There are 2 main ways of Reserving Capacity for this scenario: (a) Running extra capacity 24/7, (b) On Demand Capacity Reservations (ODCRs).
In the past, another recommendation would have been to utilize Zonal Reserved Instances (Non Zonal will not Reserve Capacity). But although Zonal Reserved Instances do provide similar functionality as On Demand Capacity Reservations combined with Savings Plans, they do so in a less flexible way. Therefore, the recommendation from AWS is now to instead use On Demand Capacity Reservations in combination with Savings Plans for scenarios where Capacity Reservation is required.
The TCO impact of the licensing situation rules out the first of the two valid options. Merely keeping the spare capacity up and running all the time also doesn’t cover the scenario in which an instance needs to be stopped and started, for example for maintenance or patching. Without Capacity Reservation, there is a theoretical possibility that that instance type would not be available to start up again.
This leads us to the second option: On Demand Capacity Reservations.
How much capacity to reserve?
Our failure scenario is when functionality in one AZ is impaired and the Auto Scaling Group must shift its instances to the remaining AZs while maintaining the total number of instances. With a minimum requirement of six instances, this means that we need 6/2 = 3 instances worth of Reserved Capacity in each AZ (as we can’t know in advance which one will be affected).

Spinning up the solution
If you want to get hands-on experience with On Demand Capacity Reservations, refer to this CloudFormation template and its accompanying README file for details on how to spin up the solution that we’re using. The README also contains more information about the Stack architecture. Upon successful creation, you have the following architecture running in your account.

Note that the default instance type for the AWS CloudFormation stack has been downgraded to t2.micro to keep our experiment within the AWS Free Tier.
Testing the solution
Now we have a fully functioning solution with Reserved Capacity dedicated to this specific Auto Scaling Group. However, we haven’t tested it yet.
The tests utilize the AWS Command Line Interface (AWS CLI), which we execute using AWS CloudShell.
To interact with the resources created by CloudFormation, we need some names and IDs that have been collected in the “Outputs” section of the stack. These can be accessed from the console in a tab under the Stack that you have created.

We set these as variables for easy access later (replace the values with the values from your stack):
export AUTOSCALING_GROUP_NAME=ASGWithODCRs-CapacityBackedASG-13IZJWXF9QV8E export SUBNET_FOR_MANUALLY_ADDED_INSTANCE=subnet-03045a72a6328ef72 export SUBNETS_TO_KEEP=subnet-03045a72a6328ef72,subnet-0fd00353b8a42f251
How does the solution react to scaling out the Auto Scaling Group beyond the Capacity Reservation?
First, let’s look at what happens if the Auto Scaling Group wants to Scale Out. Our requirements state that we should have a minimum of six instances running at any one time. But the solution should still adapt to increased load. Before knowing anything about how this works in AWS, imagine two scenarios:
- The Auto Scaling Group can scale out to a total of nine instances, as that’s how many On Demand Capacity Reservations we have. But it can’t go beyond that even if there is On Demand capacity available.
- The Auto Scaling Group can scale just as much as it could when On Demand Capacity Reservations weren’t used, and it continues to launch unreserved instances when the On Demand Capacity Reservations run out (assuming that capacity is in fact available, which is why we have the On Demand Capacity Reservations in the first place).
The instances section of the Amazon EC2 Management Console can be used to show our existing Capacity Reservations, as created by the CloudFormation stack.
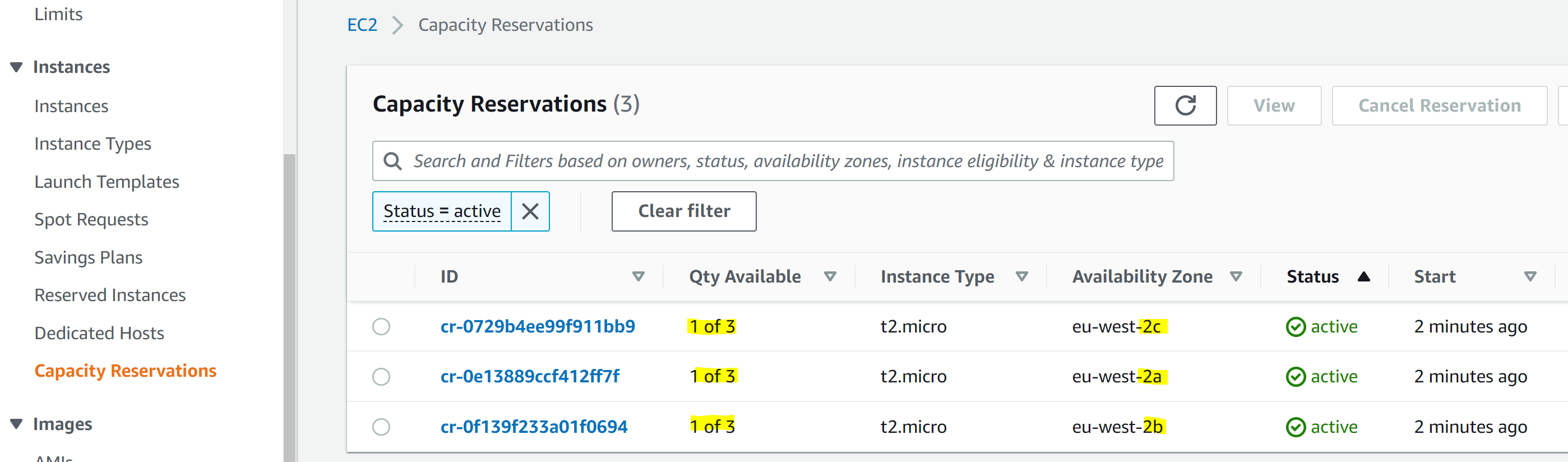
As expected, this shows that we are currently using six out of our nine On Demand Capacity Reservations, with two in each AZ.
Now let’s scale out our Auto Scaling Group to 12, thus using up all On Demand Capacity Reservations in each AZ, as well as requesting one extra Instance per AZ.
aws autoscaling set-desired-capacity \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--desired-capacity 12The Auto Scaling Group now has the desired Capacity of 12:

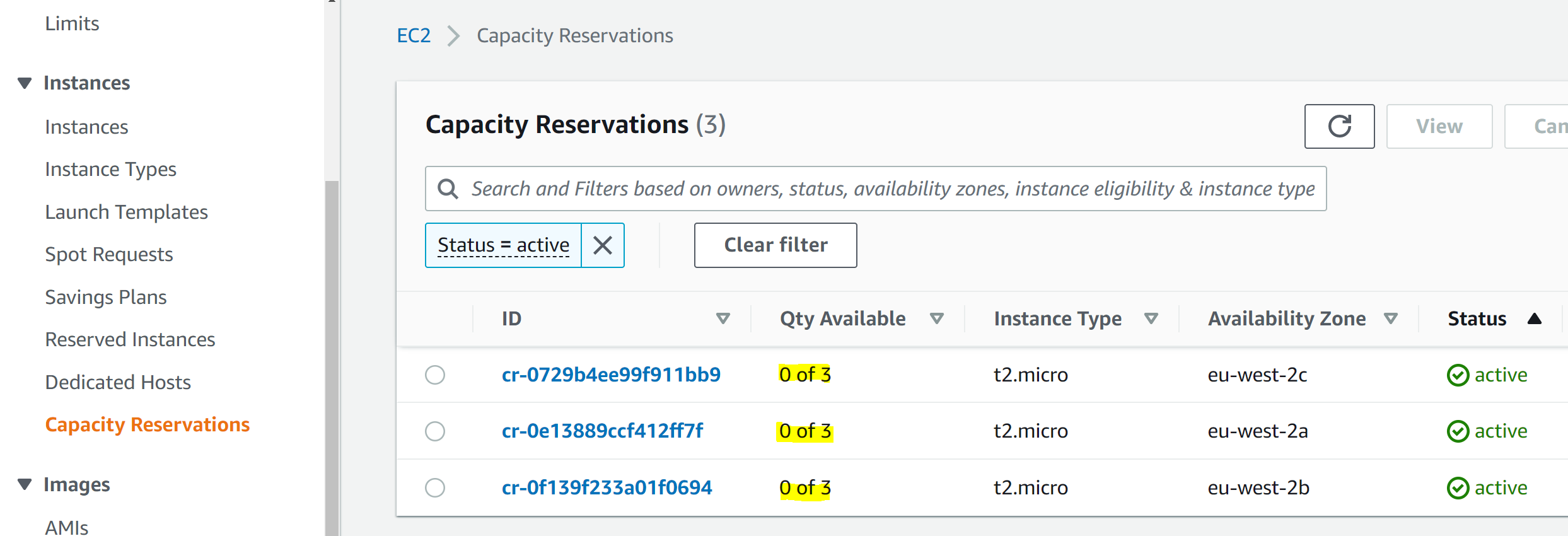
And in the Capacity Reservation screen we can see that all our On Demand Capacity Reservations have been used up:
In the Auto Scaling Group we see that – as expected – we weren’t restricted to nine instances. Instead, the Auto Scaling Group fell back on launching unreserved instances when our On Demand Capacity Reservations ran out:

How does the solution react to adding a matching instance outside the Auto Scaling Group?
But what if someone else/another process in the account starts an EC2 instance of the same type for which we have the On Demand Capacity Reservations? Won’t they get that Reservation, and our Auto Scaling Group will be left short of its three instances per AZ, which would mean that we won’t have enough reservations for our minimum of six instances in case there are issues with an AZ?
This all comes down to the type of On Demand Capacity Reservation that we have created, or the “Eligibility”. Looking at our Capacity Reservations, we can see that they are all of the “targeted” type. This means that they are only used if explicitly referenced, like we’re doing in our Target Group for the Auto Scaling Group.

It’s time to prove that. First, we scale in our Auto Scaling Group so that only six instances are used, resulting in there being one unused capacity reservation in each AZ. Then, we try to add an EC2 instance manually, outside the target group.
First, scale in the Auto Scaling Group:
aws autoscaling set-desired-capacity \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--desired-capacity 6

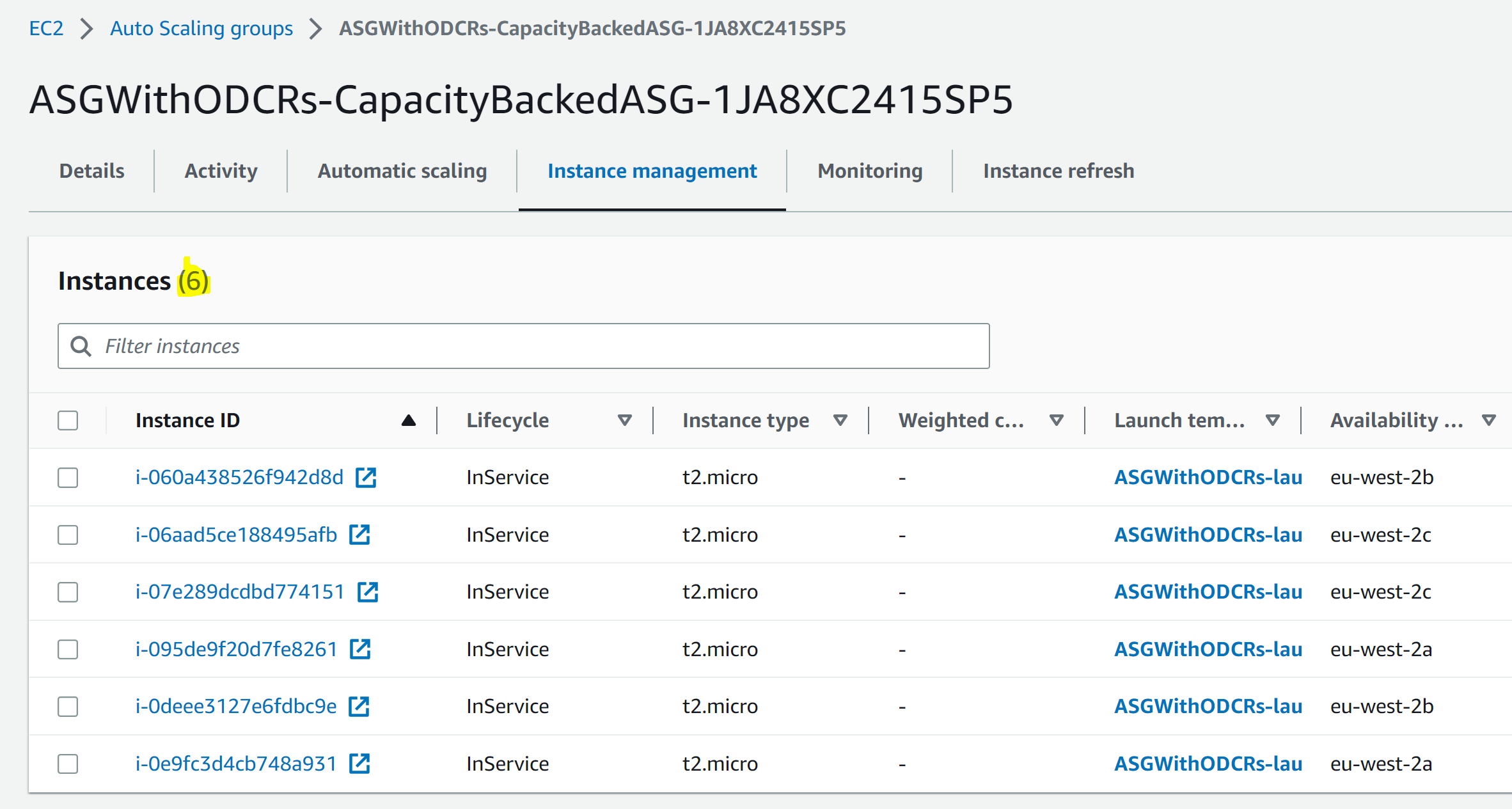
Then, spin up the new instance, and save its ID for later when we clean up:
export MANUALLY_CREATED_INSTANCE_ID=$(aws ec2 run-instances \
--image-id resolve:ssm:/aws/service/ami-amazon-linux-latest/amzn2-ami-hvm-x86_64-gp2 \
--instance-type t2.micro \
--subnet-id $SUBNET_FOR_MANUALLY_ADDED_INSTANCE \
--query 'Instances[0].InstanceId' --output text) ![]()
We still have the three unutilized On Demand Capacity Reservations, as expected, proving that the On Demand Capacity Reservations with the “targeted” eligibility only get used when explicitly referenced:

How does the solution react to an AZ being removed?
Now we’re comfortable that the Auto Scaling Group can grow beyond the On Demand Capacity Reservations if needed, as long as there is capacity, and that other EC2 instances in our account won’t use the On Demand Capacity Reservations specifically purchased for the Auto Scaling Group. It’s time for the big test. How does it all behave when an AZ becomes unavailable?
For our purposes, we can simulate this scenario by changing the Auto Scaling Group to be across two AZs instead of the original three.
First, we scale out to seven instances so that we can see the impact of overflow outside the On Demand Capacity Reservations when we subsequently remove one AZ:
aws autoscaling set-desired-capacity \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--desired-capacity 7
Then, we change the Auto Scaling Group to only cover two AZs:
aws autoscaling update-auto-scaling-group \
--auto-scaling-group-name $AUTOSCALING_GROUP_NAME \
--vpc-zone-identifier $SUBNETS_TO_KEEPGive it some time, and we see that the Auto Scaling Group is now spread across two AZs, On Demand Capacity Reservations cover the minimum six instances as per our requirements, and the rest is handled by instances without Capacity Reservation:


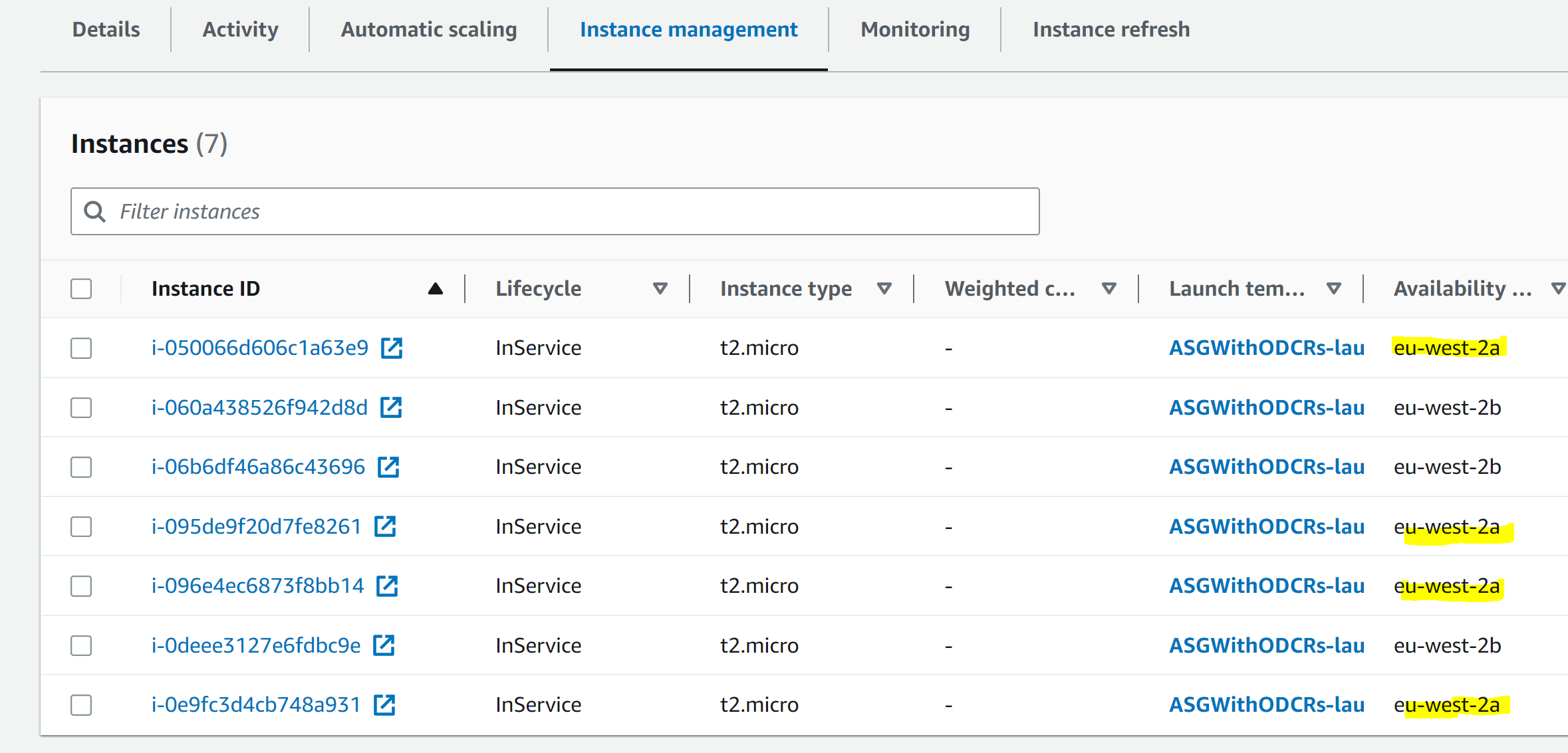
Cleanup
It’s time to clean up, as those Instances and On Demand Capacity Reservations come at a cost!
- First, remove the EC2 instance that we made:
aws ec2 terminate-instances --instance-ids $MANUALLY_CREATED_INSTANCE_ID
- Then, delete the CloudFormation stack.
Conclusion
Using a combination of Auto Scaling Groups, Resource Groups, and On Demand Capacity Reservations (ODCRs), we have built a solution that provides High Availability backed by reserved capacity, for those types of workloads where the requirements for availability in the case of an AZ becoming temporarily unavailable outweigh the increased cost of reserving capacity, and where the best practices for architecting for flexibility cannot be followed due to limitations on applicable architectures.
We have tested the solution and confirmed that the Auto Scaling Group falls back on using unreserved capacity when the On Demand Capacity Reservations are exhausted. Moreover, we confirmed that targeted On Demand Capacity Reservations won’t risk getting accidentally used by other solutions in our account.
Now it’s time for you to try it yourself! Download the IaC template and give it a try! And if you are planning on using On Demand Capacity Reservations, then don’t forget to look into Savings Plans, as they significantly reduce the cost of that Reserved Capacity..