AWS Database Blog
Empowering fraud detection at Delivery Hero with Amazon Neptune
This is a guest post co-authored by Amr Elnaggar, Saurabh Deshpande, Mohammad Azzam, Matias Pons and Wilson Tang from Delivery Hero.
Delivery Hero is available in 74 countries around the World. It operates a wide range of local brands that are united behind the shared mission Always Delivering an Amazing Experience — fast, easy, and to your door. Delivery Hero’s rapid growth (EUR20 billion in H1 2022 with +24% growth YoY) includes acquiring customers through promotions in the form of acquisition vouchers. However, Delivery Hero faced the problem of customers abusing the acquisition vouchers, causing financial losses.
In this post, we show you the initial approach we took to solve this problem, the challenges we faced, and how we solved them by using a graph stored in Amazon Neptune.
Neptune is a fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Neptune is optimized for storing billions of relationships and querying the graph with milliseconds latency, and supports the popular graph query languages Apache TinkerPop Gremlin, the W3C’s SPARQL, and openCypher. You can learn more about Neptune in the User Guide.
A first MVP for fraud detection
Back in 2019, a team of highly motivated engineers at Delivery Hero tried to solve the problem of voucher abuse for one of its brands with a solution called Account Association, which was built on a simple architecture, as shown the following diagram.
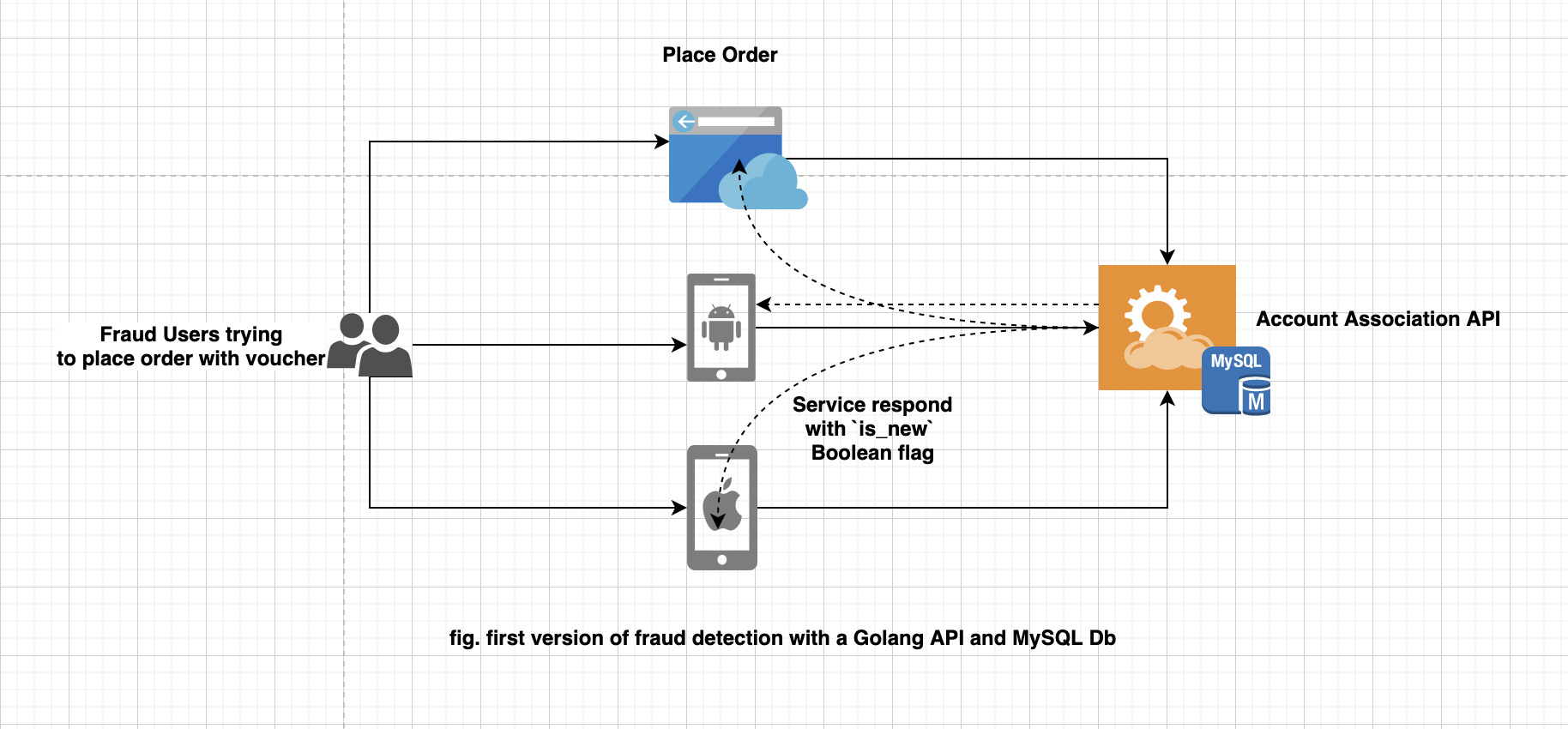
The solution’s stack was a Golang API with a Golang worker and an Amazon Relational Database Service (Amazon RDS) for MySQL database. The data stored in Amazon RDS for MySQL, which helped connect accounts based on certain attributes, was used by the Account Association API to determine if the customer’s voucher redemption was fraudulent or legitimate. This data was continuously updated by the Golang worker based on certain events that happen in near-real time.
The solution worked without using personally identifiable data because the problem we were solving only required us to know if multiple accounts were the same person—not who that person was. We only used hashed and anonymized data, both current and historical, and never had to access the raw original data.
This first version worked well for a while, but there were cases reported of further voucher abuse. To counter these cases, we started adding more attributes to the existing table structure to enhance the detection mechanism, but soon discovered that this wasn’t a sustainable strategy.
Because we were processing 1 million orders per day, the amount of data generated wasn’t allowing us to add more attributes to our tables. This was because adding new indexes to the existing tables locked them for an unacceptable period of time, during which the API wasn’t available.
We considered building another table and adding new indexes there in an offline mode, but this wouldn’t be a permanent solution. Furthermore, it would require new indexes when new columns were needed, as well as make the application code more complex.
Boots on Neptune
When the existing solution turned out to not be scalable enough, the team started looking for an alternative solution and designing its requirements.
To address the use cases we were working with, we wanted a solution that could accommodate the constant growth in the number of attributes required to detect voucher abuse, as well as the constant increase in number of orders, which by now was at 2 million per day.
It was during a whiteboarding session, when we were drawing our relational table and looking at the queries we needed to perform and indexes we needed to build, that we realized that the drawing on the whiteboard was actually a graph. We recognized that the data stored in Amazon RDS for MySQL was effectively connected data, because it determines the associations between customer accounts. We went back to the whiteboard, literally, and transformed the relational model into a simpler attribute-based graph. And on the whiteboard, the data in a graph representation was easier to understand and read, as well as extend, when compared to a flat relational table. The following figure shows an example.
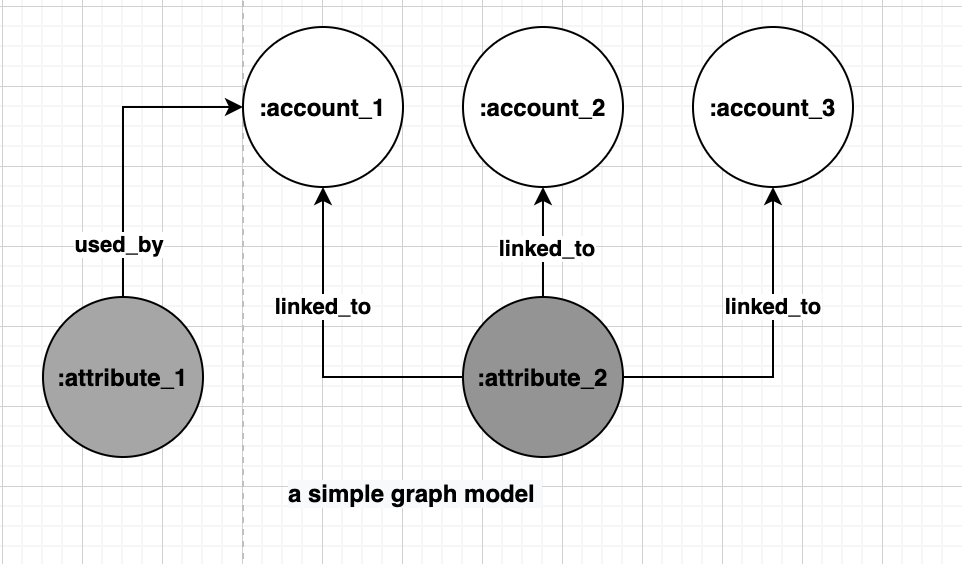
For confidentiality reasons, we only include placeholder names in the preceding attributes, but you can think of several attributes belonging to accounts making orders on Delivery Hero that, if they were the same in other accounts, could constitute a fraudulent order. They would indeed be fraudulent if they were taking advantage of discounts or offers only available via vouchers, for example.
We looked for graph-based databases and built a small proof of concept. The results were surprisingly good in terms of the information we could derive from the graph model. We immediately found associations that we weren’t aware of and big clusters of users committing fraud in our system—all of this from a proof of concept.
As we started planning the migration, we decided to go with Neptune because it’s a fully managed service from AWS, freeing us from maintenance in our infrastructure. Adding new attributes didn’t mean any downtime for rebuilding indexes manually, as we had to do with MySQL, to accommodate new query patterns. Neptune keeps a set of three indexes that covered our use case, and manages them automatically. The query performance of evaluating account associations was approximately 15 milliseconds, which was good for our needs, and our load tests with 100 concurrent calls to the API had no effect on query performance. Looking into the future, we knew we could have up to 15 read replicas, which gave us plenty of room to expand if needed. Finally, we could also visualize graphs using the Neptune workbench.
Ultimately, Neptune allowed us to focus on solving the fraud detection problem, while still giving us features that opened new possibilities.
We started our evaluation by migrating the data from Amazon RDS for MySQL to Neptune. We considered three options: using AWS Data Migration Service (AWS DMS), the Neptune bulk loader, or just the plain Gremlin API through a purpose-built CLI tool. We went with building a CLI tool because this way we had fewer requirements on the infrastructure side and we controlled all the components of the migration.
Throughout the whole process we also learned Gremlin, which is one of the graph query languages that Neptune supports. This was ultimately a fun process, and building the CLI tool certainly helped us get acquainted with it.
The new architecture
After the evaluation phase, the team built the infrastructure around Neptune to generate account association graphs, as shown in the following diagram.
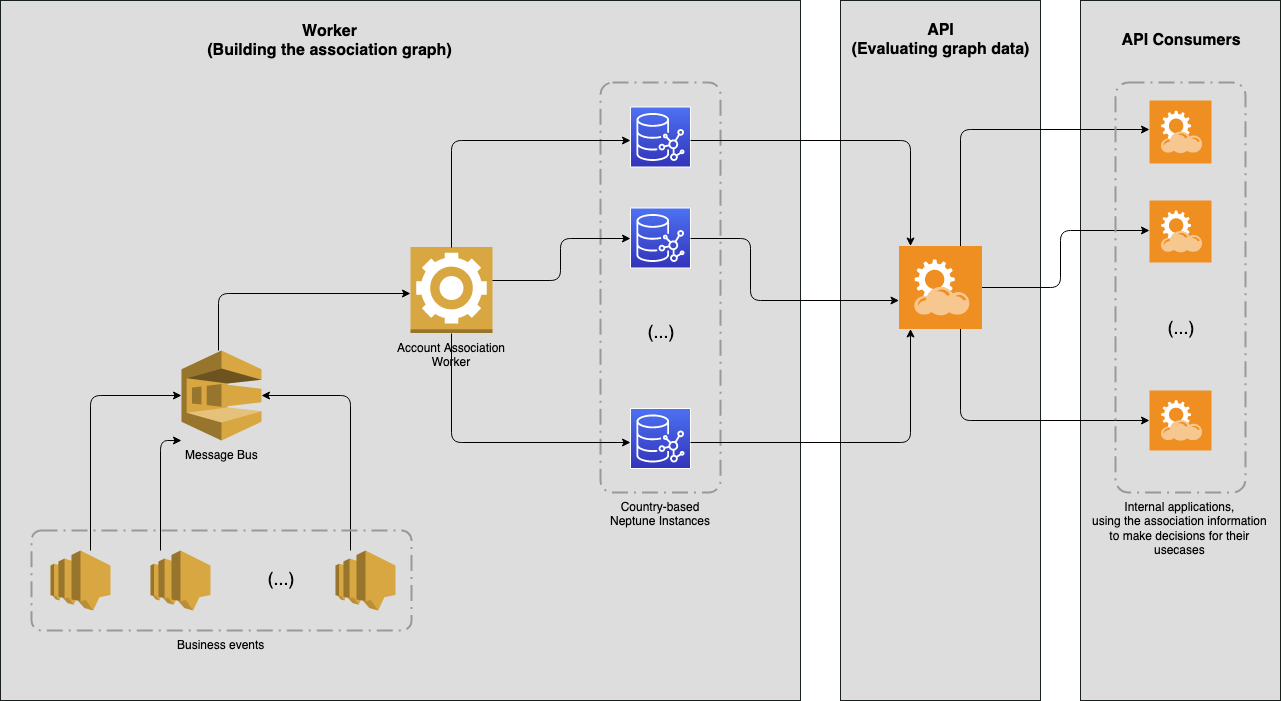
With the new architecture in place, we could identify more associations between accounts—namely, cases where multiple different accounts actually belonged to the same person for the purpose of fraud. Therefore, we could start preventing more voucher abuse, and also easily add more attributes and nodes to Amazon Neptune.
Although implementing this new architecture was a quick win, the solution started producing issues for users with multiple associations. This was happening because graph query latency is related to how many elements (nodes, edges, or properties) of the graph a query touches—users with more associations take longer to process. In these cases, we were responding in approximately 50 milliseconds, which was especially bad because these were exactly the cases of people who were committing fraud in the system.
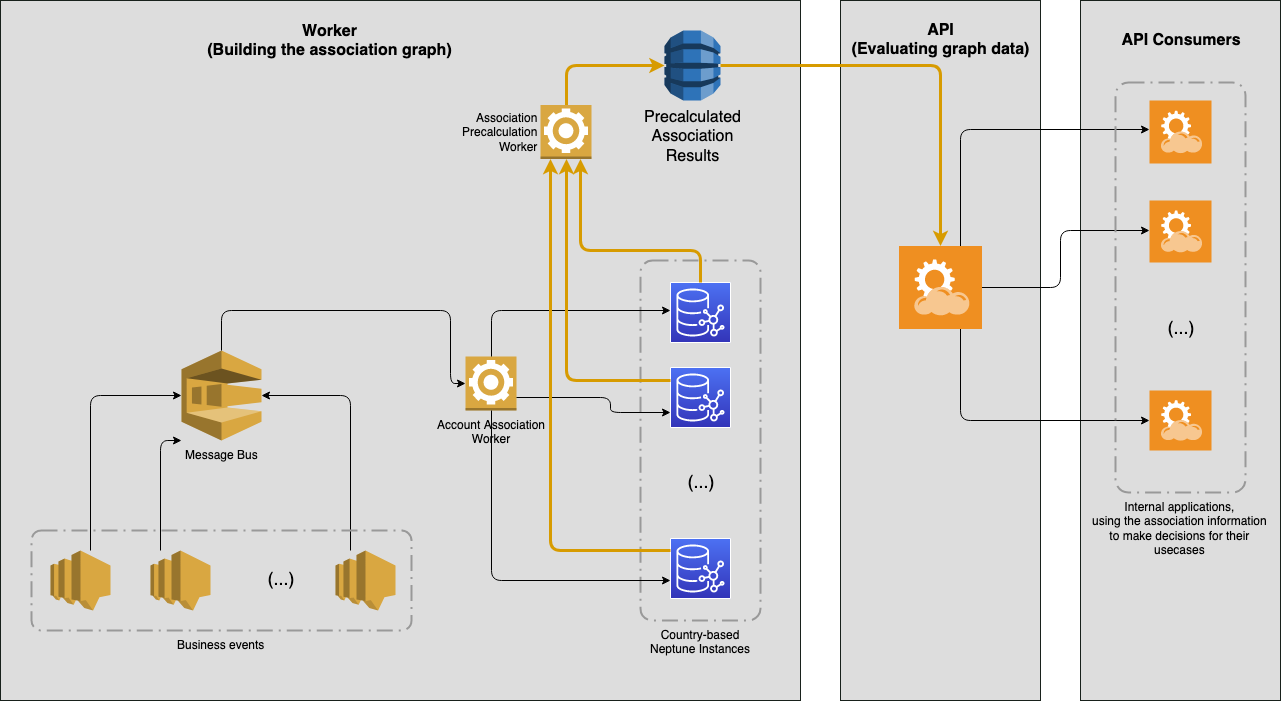
To solve this problem, the team experimented with pre-calculating the association results in another store. Doing so meant that no matter how many associations an account has, the query fetching the needed data wasn’t affected. This pre-calculation was triggered by the updates to Neptune by the Account Association workers, to ensure that the API consumers had access to up-to-date data.
We decided to adjust the initial architecture by introducing an Amazon DynamoDB table, from where the API reads the pre-calculated associations, resulting in a p95 latency of approximately 5 milliseconds for API calls. DynamoDB also brought a few extra advantages: it allowed us to export our data to Amazon Simple Storage Service (Amazon S3) for further analysis with Amazon Athena, for example. Additionally, through the use of global secondary indexes, it allowed us to scale the query patterns of our business users and provide special indexes for specific views they wanted to have of the system. The following diagram illustrates our improved architecture.
Conclusion
With the insight that voucher abuse is a graph problem, and our solution architecture based on Neptune and DynamoDB, the platform security team was able to bring value to the business by increasing the amount of blocked fraudulent purchases by 32%.
Equally relevant is that we can add new data points to the graph in a scalable way. Performance isn’t affected, even in the face of a constantly increasing number of orders per day (as of this writing, 2 million per day). Finally, other teams have also tapped into the graph and API we implemented in order to do further analysis and inference, as well as to get their own specific business units’ perspective on fraud, which is a testament to how stable this solution is, and the value it provides beyond its immediate users.
- For more information about data modeling on Neptune, refer to Neptune Graph Data Model, and dive deep into Gremlin on the Apache TinkerPop website.
- To learn more about Neptune and building graph databases, including best practices, code samples, and other blog posts, refer to Amazon Neptune Resources.
About the authors
 Wilson Tang is the Director of Engineering at Delivery Hero based in Berlin, Germany. He has over 15 years of experience in the tech industry. Currently focusing on providing secure and scalable SaaS to internal teams such as Authentication/Authorization and Auditing solutions.
Wilson Tang is the Director of Engineering at Delivery Hero based in Berlin, Germany. He has over 15 years of experience in the tech industry. Currently focusing on providing secure and scalable SaaS to internal teams such as Authentication/Authorization and Auditing solutions.
 Mohammad Azzam is the Director of Product at Delivery Hero based in Berlin, Germany. He is Responsible for several company-wide centralized services including Authentication & Identity Management, Authorization, and Auditing.
Mohammad Azzam is the Director of Product at Delivery Hero based in Berlin, Germany. He is Responsible for several company-wide centralized services including Authentication & Identity Management, Authorization, and Auditing.
 Saurabh Deshpande is an Engineering Manager at Delivery Hero SE based out of Berlin, Germany. He has more than 11 years of industry experience, including design and development of scalable systems. He currently focuses on delivering the unified Authentication experience for various Delivery Hero Brands.
Saurabh Deshpande is an Engineering Manager at Delivery Hero SE based out of Berlin, Germany. He has more than 11 years of industry experience, including design and development of scalable systems. He currently focuses on delivering the unified Authentication experience for various Delivery Hero Brands.
 Matias Pons is a Software Engineer working as Engineering Manager at Delivery Hero, Germany. He has been working in the industry for over 10 years. Currently focused on providing core service solutions for internal developers throughout all Delivery Hero platforms.
Matias Pons is a Software Engineer working as Engineering Manager at Delivery Hero, Germany. He has been working in the industry for over 10 years. Currently focused on providing core service solutions for internal developers throughout all Delivery Hero platforms.
 Amr Elnaggar is a Staff Software Engineer at Delivery Hero based out of Berlin, Germany. He has more than 5 years of industry experience, including design and development of various distributed systems.
Amr Elnaggar is a Staff Software Engineer at Delivery Hero based out of Berlin, Germany. He has more than 5 years of industry experience, including design and development of various distributed systems.
 Luís Rodrigues Soares works with Game Development Studios across Europe to help them build, run and grow their games on AWS. Besides AWS for Games, he has a passion for well crafted products, and uses his Software Engineering and CTO experience to help people make the best out of Amazon Web Services (AWS). Outside of work, he loves solving math and coding puzzles, and he writes fan fiction for his favorite video game, “Elite: Dangerous”.
Luís Rodrigues Soares works with Game Development Studios across Europe to help them build, run and grow their games on AWS. Besides AWS for Games, he has a passion for well crafted products, and uses his Software Engineering and CTO experience to help people make the best out of Amazon Web Services (AWS). Outside of work, he loves solving math and coding puzzles, and he writes fan fiction for his favorite video game, “Elite: Dangerous”.