AWS Database Blog
How CSC Generation powers product discovery with knowledge graphs using Amazon Neptune
This post is co-written with Bobber Cheng and Ronit Rudra from CSC Generation.
CSC Generation is a company that focuses on acquiring overlooked stores and catalog-based retailers and transforming them into high-performance, digital-first brands. As we grew through multiple acquisitions, it became apparent that our legacy product information system (PIM), backed by relational databases, was no longer able to handle the ever-increasing product inventory across all our brands.
In order to meet the scale required, we developed a new PIM system called CorePIM, which at its heart, uses a knowledge graph powered by the managed graph database service Amazon Neptune. Sitting tangential to the knowledge graph and supporting our APIs are a set of microservices that are tightly integrated with other AWS services like Amazon OpenSearch Service and Amazon Kinesis Data Streams.
The knowledge graph-based architecture of CorePIM provides efficient and flexible product information management, and is essential for the scalability of CorePIM. In this post, we discuss the use case, technical challenges, and implementation details of our knowledge graph and CorePIM system.
Background
The legacy PIM system was originally backed by a MySQL database, which ran product discovery well for a few thousand products but did not scale efficiently for millions of products, as the queries in our legacy system were required to fetch all data from a central database and manipulate the intermediary results before returning a final result. The following is an example of a small subset of one of our legacy system’s queries for extracting product data. Multiple SQL queries like this were run to generate the full data for a product.
In addition to unscalable performance, business teams also encountered schema restrictions, faced with either too rigid data validation or no validation at all for product information. So for CorePIM, we took a different approach by instead using a knowledge graph to represent the product information.
The Product Knowledge Graph
The heart of CorePIM is driven by our Product Knowledge Graph. Graphs are collections of nodes and edges, where nodes represent entities or real-world objects, and edges represent the relationships that dictate how those entities are related. By translating the product data into a graph format, we can better manage the heterogeneity of product data, regardless of product definition or which retail brand it comes from.
Amazon Neptune is a fully managed graph database service that makes it easy to build and run applications that work with highly connected data sets and supports both the labeled property graph framework (LPG) and the Resource Description Framework (RDF). Either framework can be used to represent connected graph data, but RDF is purpose-built for the Semantic Web and knowledge sharing. So, it made sense to use RDF for our use case, where product data could be easily shared and reused across different teams. Neptune supports SPARQL 1.1 Federated Query, which makes it possible to integrate third-party knowledge (for example, Wikidata data) with the product data that we already have.
Representing products in the graph data model
In RDF, Internationalized Resource Identifiers (IRIs) are used to represent source nodes and edges (and optionally target nodes). IRIs let you uniquely identify a given resource in the graph, and are especially helpful in the retail space. If we had two different products with the exact same name, if they have different IRIs they can always be distinguished from each other. For example, Retail Brand A and Retail Brand B might both have a product called “Cotton Sectional.” By using different IRIs, we can still distinguish the products across the different brands.
In RDF it’s also common to define and use ontologies with your knowledge graph, which can be loosely thought of as the data model or data schema of your graph. Ontologies define the different concepts within a given domain, and what kinds of relationships can exist between them. For example, teaspoons and tablespoons are both sub-classes of spoons, and spoons are sub-classes of cutlery. CSC Generation creates dozens of predefined RDF ontologies to model a product’s meta information. A few examples of ontologies we create include:
- Product ontologies – These define general product information that all products are required to include, such as ID, display name, and the creation time. It also includes optional attributes such as what categories the product might belong to or variants of the product exist.
- Product collection ontologies – These define general product-to-category relationships, or which categories a certain product can belong to. For example, a cast iron skillet might belong to the categories of cookware, stovetop, and sauté pans.
- Product attribute ontologies – These define general product-to-attribute relationships, or what attributes a product can have. For example, a cast iron skillet might have a set range of colors, sizes, and prices.
- Product self-ontologies – These define general product-to-product variant relationships, such as what variants a product can have. For example, a cast iron skillet that has a limited-edition enameled version.
When each brand team creates and modifies their products via user interface, under the hood they are creating and modifying RDF entities whose properties are bounded by our ontologies. Each product is mapped to a unique RDF entity and its corresponding set of attachments (for example categories, attributes, and/or variants). Its product stock keeping unit (SKU) is in IRI format, so it can be referenced by IRI for technical teams or by SKUs for business teams.
To control the specific attribute features that each product attribute is allowed to have (for example, a product that is allowed to have more than one color associated with it or only one weight associated with it), we use what we call attachment nodes. These attachment nodes are instances of the classes that our ontologies define. For example, if you want to store the color (defined by the product attribute ontology) of a product as beige and white, you’d achieve this via an attachment node like paa:myProduct:color (referenced in Figure 1), which stores the raw values of beige and white via the predicate paao:value. The attribute node itself (for example, attribute:color in the diagram) carries information on what the datatype should be (for color, it’s a string) and any other constraints that the attributes may have (for example, the color attribute can have more than one value). All product data that is written into Neptune is rigorously validated to ensure it follows the set attribute definitions and ontologies. Validation is done using multiple methods, one of which is via the RDF Shapes Constraint Language (SHACL).
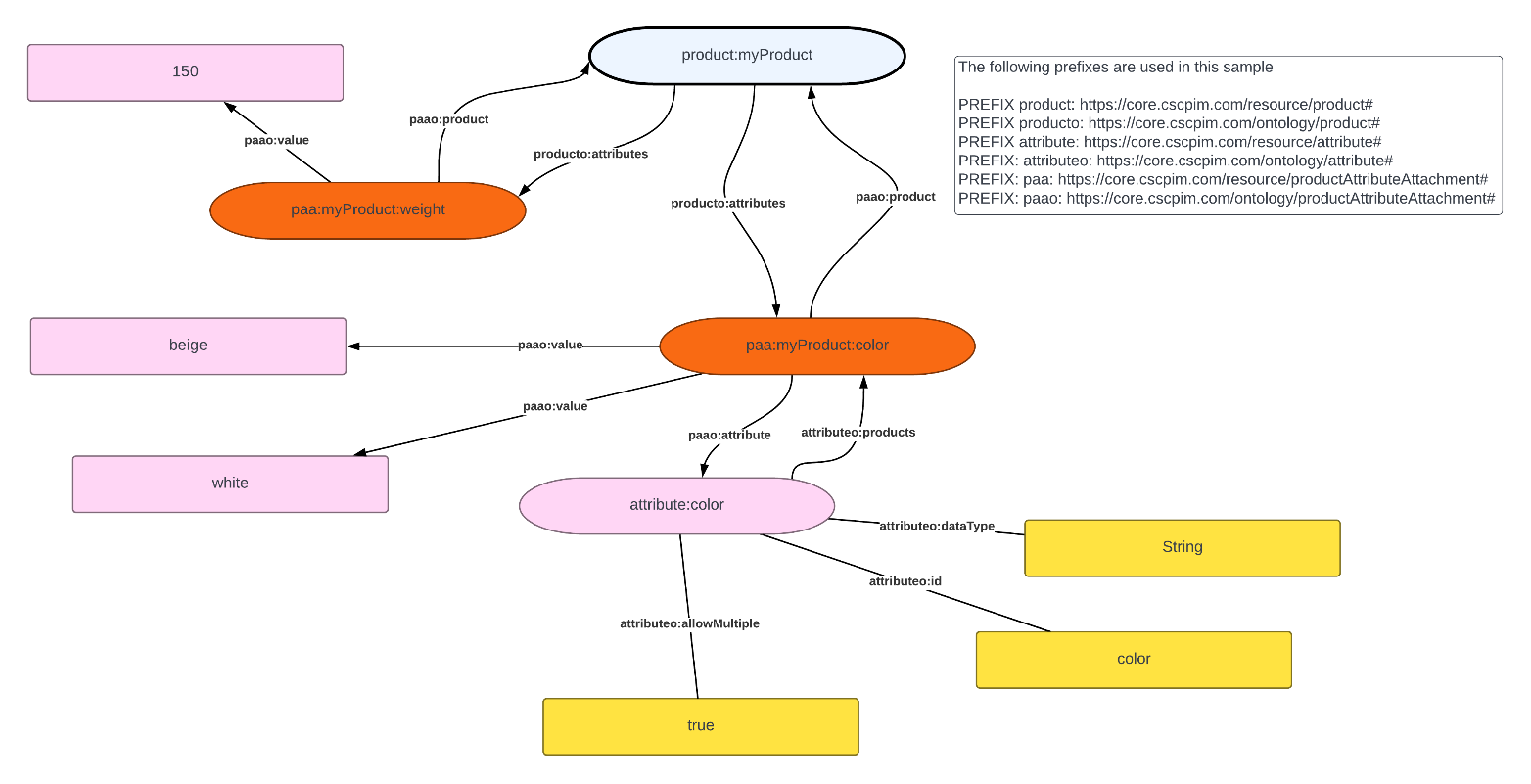
Figure 1: A sample of the attribute node attachment structure within the product knowledge graph.
SHACL is a method that can be used to validate an RDF graph against a set of rules. It includes features to express conditions that constrain the number of values that a property may have, the type of such values, numeric ranges, string matching patterns, and logical combinations of such constraints. For example, “[sh:path schema:name; sh:minCount 1; sh:maxCount 1;]” means that one name only must exist. Since SHACL is used by engineers and not by business users, CorePIM provides a user interface for business users to manipulate SHACL constraints, by selecting dropdown items as shown later on in the user perspective given by Figure 5.
Representing retailers in the graph data model
As a multi-tenant platform for different retailers, all CSC brands consuming CorePIM share the same physical RDF database (single Neptune cluster) but are logically separated using named graphs, which can be thought of as subgraphs in RDF. Named graphs can be used to partition the overall graph (database contents), and allows for scoped queries and simplified permissions management whilst still taking advantage of being able to link data together. By using named graphs, we are able to integrate our identity and access management service with CorePIM to enforce granular permission management at the tenant level.
For instance, if a user wants to fetch information on their “Cotton Sectional” product, our identity and access management service first validates the user’s permissions to determine if access should be granted. If so, it then determines which named graph the query should be run against.
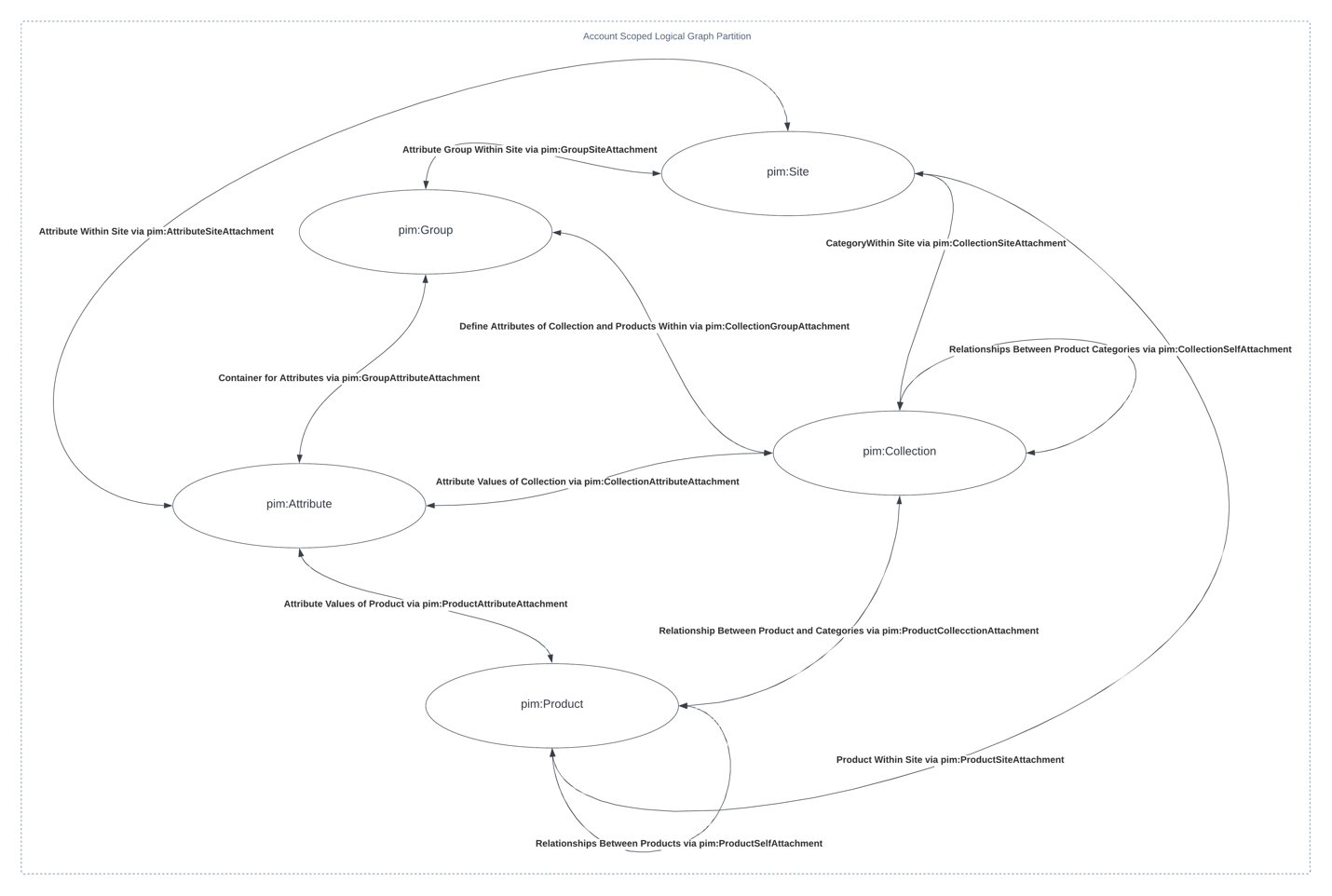
Figure 2: An example of the resource types that are collected within a given named graph, where each named graph is mapped to a single retail brand (tenant).
Expanding the Product Knowledge Graph with OpenSearch Service
While Neptune is highly tuned to run connection-focused queries such as “Fetch all products under a specified category hierarchy by traversing connections amongst all child categories,” other queries focused on aggregation, full-text searching, and ordering are optimized in other database solutions.
Because of the hybrid nature of some queries (for example full-text searching on IRIs, sorting large result sets by feature, and more), we decided to incorporate purpose-built database solutions that were tailored to the data access pattern and data shape of those other queries – in this case, OpenSearch Service.
OpenSearch Service is a managed service that makes it easy to do everything from interactive log analytics to website searching and more. It is a managed version of OpenSearch, an open source, distributed search and analytics suite.
In the CorePIM architecture, while Amazon Neptune is used to hold the core product knowledge graph, OpenSearch Service is used in conjunction with Neptune as a weakly consistent (replication lag on the order of a few hundred milliseconds) but extremely low latency read layer. When making an API call, clients have the choice of either targeting Neptune for strong consistency, or OpenSearch Service for weak consistency. Requests that need to prioritize query response times perform their read operations with weak consistency, achieving sub-second response times when requesting large datasets, for example when scanning over an ordered collection of millions of products for an ETL process. Strong consistency is needed for schema and state validation tasks during write operations.
However, unlike other OpenSearch Service solutions we have developed (for example scheduled bulk ETLs from source store to destination), CorePIM requires real-time streaming of any write operations invoked through our API/SDK into OpenSearch Service. To meet this requirement, Amazon Kinesis Data Streams was also integrated into the solution. Using Kinesis Data Streams with an appropriate consumer can trivialize streaming data into OpenSearch Service. CorePIM has nearly one hundred API endpoints which serve customers through the Console, Command Line, and SDK. Users are also able to ingest millions of products into PIM via our Bulk Ingestion workflow by uploading a file to Amazon Simple Storage Service (Amazon S3). Kinesis Data Streams is the most appropriate service to rapidly ingest data from multiple sources regardless of volume.
The overall architecture flow is as follows:
- After a successful write to Neptune, an API handler or an Ingestion Workflow writes the corresponding events to a Kinesis Data Streams stream corresponding to the resource types it is handling. The following is an example Kinesis Data Streams record emitted on product write.
{PartitionKey: 'opensearch-product',Data: '{"action":"CREATE","resource":"product/cottonSectional","accountId":"000000000009"}'}
The partition key specifies the AWS Lambda consumer that will handle the event. Event Source Mapping Filters are used to target consumers. - Consumer application reads from the Kinesis Data Streams stream and indexes the data into OpenSearch Service. In our case, a Lambda function mapped to Kinesis parallelly processes batches by querying Neptune for data, transforming that data into documents, and bulk inserting/updating into OpenSearch Service.
- Data is indexed and stored directly in the form that will be consumed by API callers. Additional transformations are included to facilitate full-text search and aggregation. Neptune to OpenSearch Service lag is on the order of a few hundred milliseconds.
- Interactions with the primary application aim to put event data into Kinesis in a non-blocking fashion to maintain acceptable response times. In case of errors, the event is pushed into an Amazon Simple Queue Service (Amazon SQS) queue for retries.
- Fallback solutions bulk index data on a schedule to maintain parity.
- PUTs are randomized across Kinesis Data Streams shards to maximize throughput. A source has a choice of querying the current shard key ranges or statically generating them, given an expected number of Shards.
- All AWS resources have multiple Amazon CloudWatch Alarms configured for key metrics such as Lambda timeouts, Neptune CPU and queued requests, and Kinesis Data Streams record age, that send notifications via AWS ChatBot to our monitoring Slack channels.
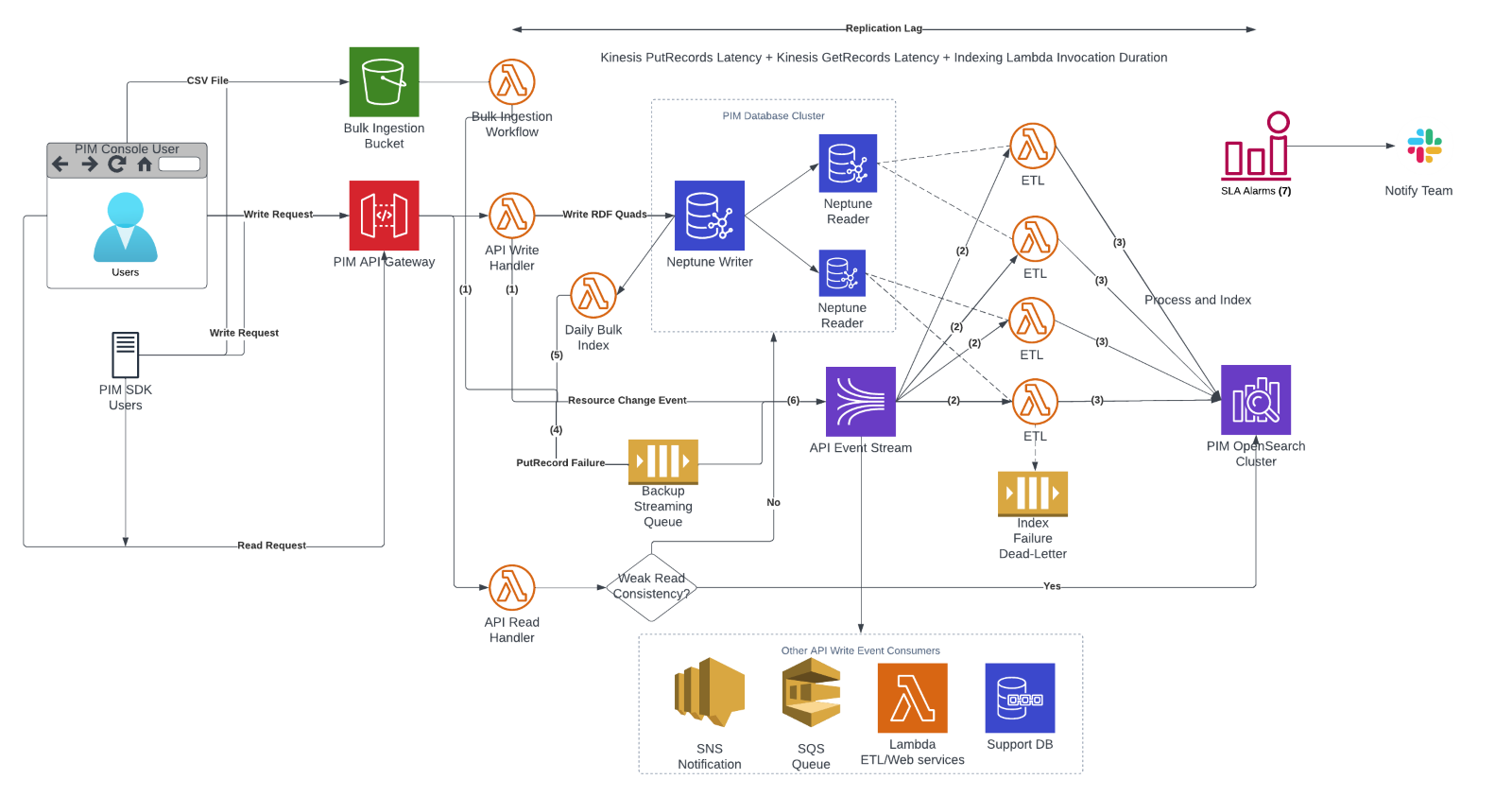
Figure 3: Diagram of the overall architecture.
The Product Knowledge Graph in Action
Having understood the technical implementation of the product knowledge graph and CorePIM as a whole, let’s see it in action from the end user perspective.
As a retail and e-commerce business, one of our daily jobs is to add and update product information such as prices and quantity, and improve catalog findability to help consumers discover more products with lower cost. CorePIM provides the “gold stack” for retail teams to manage their products within a shared responsibility model.
The first step of managing product information is creating the product attribute definition. As we saw earlier, the product attribute definition is defined within the attribute nodes (attribute:color in Figure 1). In CorePIM, a set of common product attributes are already predefined such as the id, product group, bases, and variants. To accommodate further schema flexibility, retail teams are allowed to create custom product attribute definitions (as shown in Figure 4), which then are mapped to attributes that follow certain rules (as shown in Figure 5). These custom product attribute definitions can also be grouped according to a hierarchical taxonomy, which is definable by retail teams. For example, a name of a product in a catalog is a short string, product availability is a Boolean, the color of products is an enumeration, and so on. The following images show the flow of how a user defines product attribute definitions through the user interface.
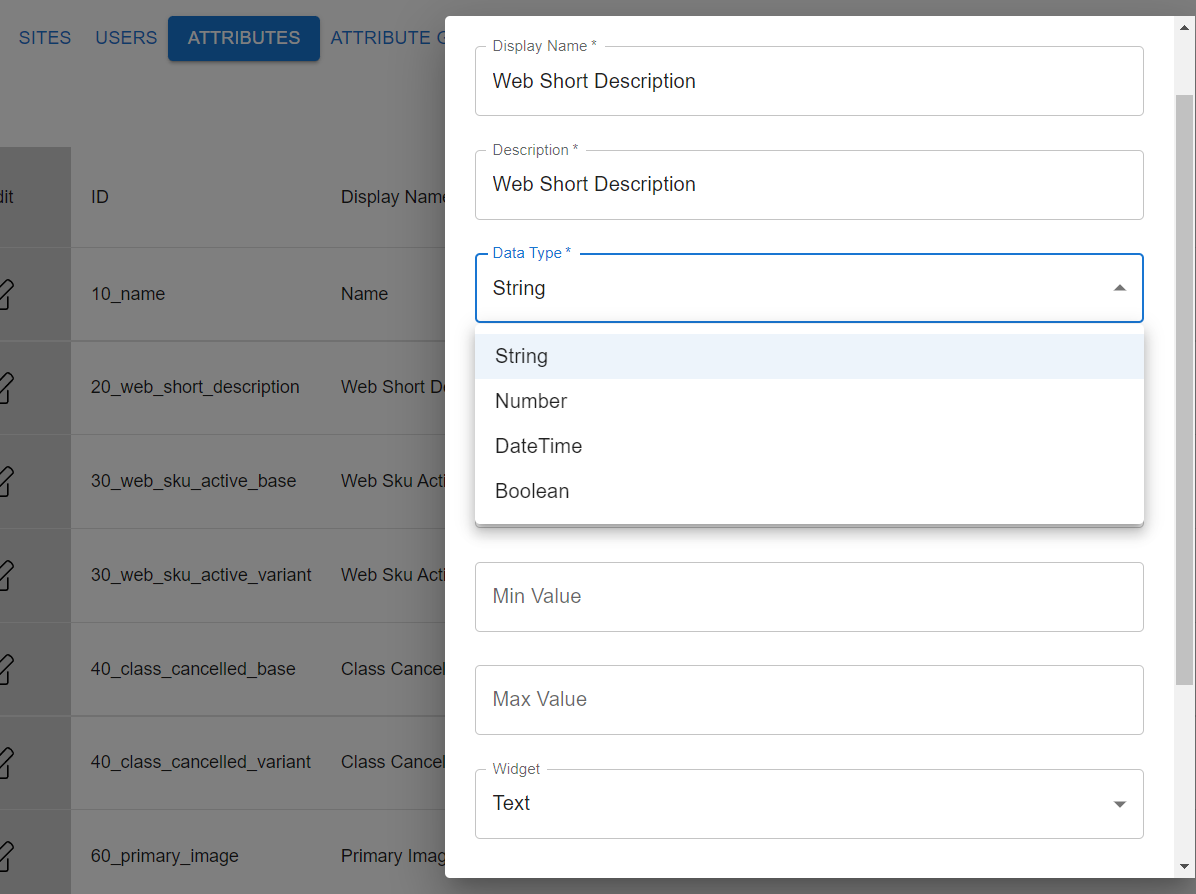
Figure 4: Adding a custom product attribute definition, “Web Short Description”, through the CorePIM user interface. This custom product attribute definition is defined to be a string.
Once a team’s product attribute definitions are ready, the product and catalog data can be loaded into CorePIM’s knowledge graph, which uses the product attribute definitions to validate the product data entered by teams via SHACL. Once the data is loaded, business teams can easily do product knowledge discovery across all the brands in CSC Generation. For example, if a user wants to search for red-colored and glass-made cookware, they can search based off those previously defined product attributes.
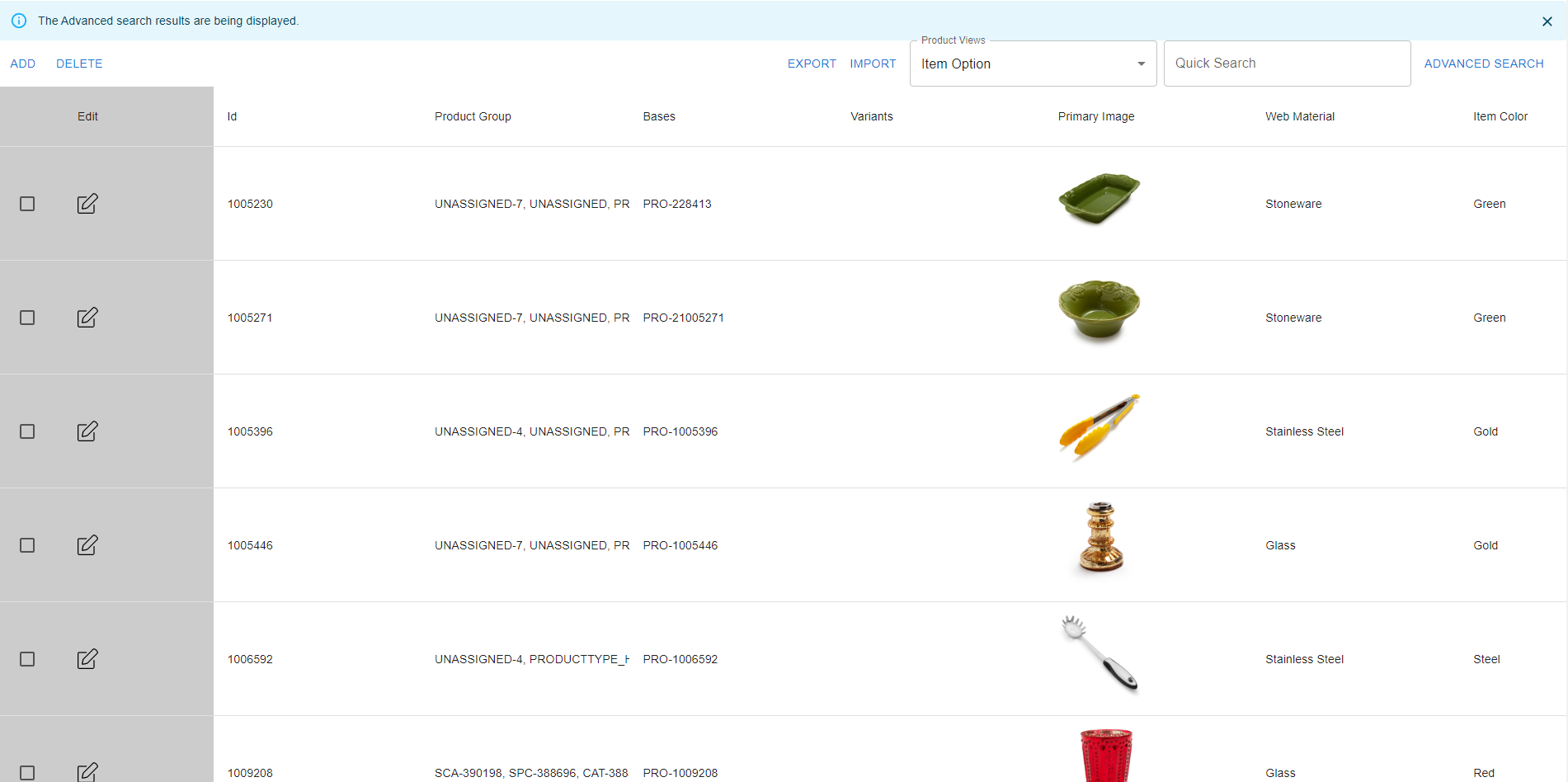
Figure 6: Product view from the search user interface.
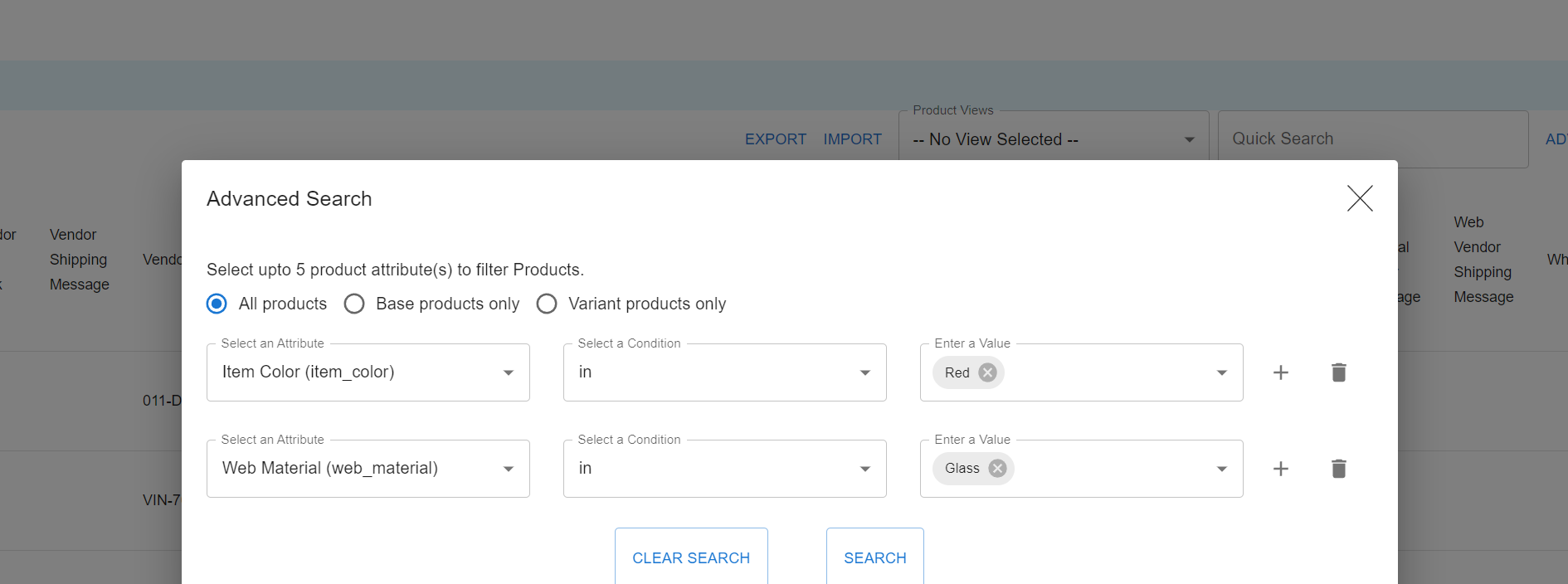
Figure 7: Finding red-colored and glass-made cookware across different retail brands via user search interface.
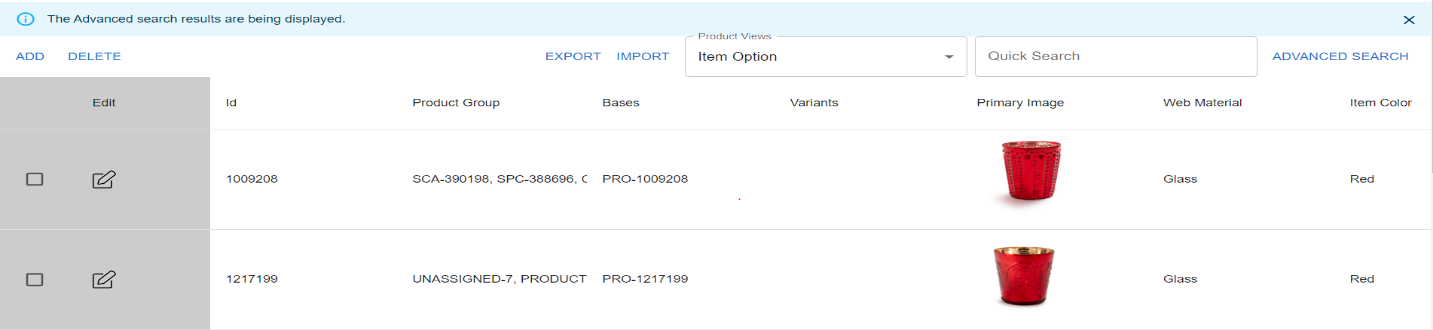
Figure 8: Search results for red-colored, glass-made products.
Conclusion
This post shows how we modernized our legacy PIM by re-architecting the data layer of our product catalog from SQL-based tables to a knowledge graph. Since modernizing, business teams no longer have to adhere to a strict, fixed schema, or worry about product quantities outscaling traditional database servers. By using knowledge graphs to represent our product data, we’re able to define and enforce the different product attributes and relations that exist between them – all with the flexibility, efficiency, and scalability needed to meet the rapid expansion of our retail brands. Using a knowledge graph also opens future possibilities for enhancing our data with other open data sets to gather more insights. For example, matching products in our inventory against generalized ontologies for product hierarchies, which could unlock the ability to do more accurate product recommendations by product type or function.
By using fully-managed services and the right database for the right job, CorePIM not only provides higher product availability, better performance, and lower maintenance overhead, but provides room for future feature growth and expansion.
About the Authors
Bobber Cheng is an Engineering Manager at CSC Generation Toronto Canada. He has more than 20 years of experience in software development. In recent years, he has been advocating for the integration of AI to empower engineering teams.
Ronit Rudra is a Senior Software Engineer at CSC Generation Chicago US. He has worked on several key initiatives for retailers under CSC, namely; One Kings Lane, Z Gallerie, DirectBuy to enhance their technology stack and empower the business. Currently, he’s involved in building core SaaS products, one of which is CSC’s in-house Product Information Management service.
Melissa Kwok is a Neptune Specialist Solutions Architect at AWS, where she helps customers of all sizes and verticals build cloud solutions with graph databases according to best practices. When she’s not at her desk you can find her in the kitchen experimenting with new recipes or reading a cookbook.