AWS Cloud Operations Blog
Simplifying Log Management using Amazon CloudWatch Logs Centralization
Managing logs across multiple AWS accounts and regions has always been a complex challenge for organizations. As AWS infrastructure grows to include separate accounts for production, development, and staging environments, along with regions, the complexity of log management increases exponentially. During critical incidents, especially during off-hours, teams spend valuable time, searching through multiple accounts, correlating events across different regions, managing complex log aggregation systems, and maintaining cross-account access permissions. This traditional approach to log management not only consumes significant resources but also delays incident resolution, potentially impacting customer experience. In this blog post, we show you how to simplify log management for large-scale environments.
Introducing CloudWatch Logs Centralization
While Amazon CloudWatch has offered cross-account observability through federation for logs across accounts, the new CloudWatch Logs centralization takes a fundamentally different approach—it consolidates your log data from multiple accounts and regions into a central account. This consolidation eliminates both the operational overhead and costs associated with managing custom-built aggregation solutions, providing organizations with a definitive single source of truth for all their log data as shown in Figure 1.
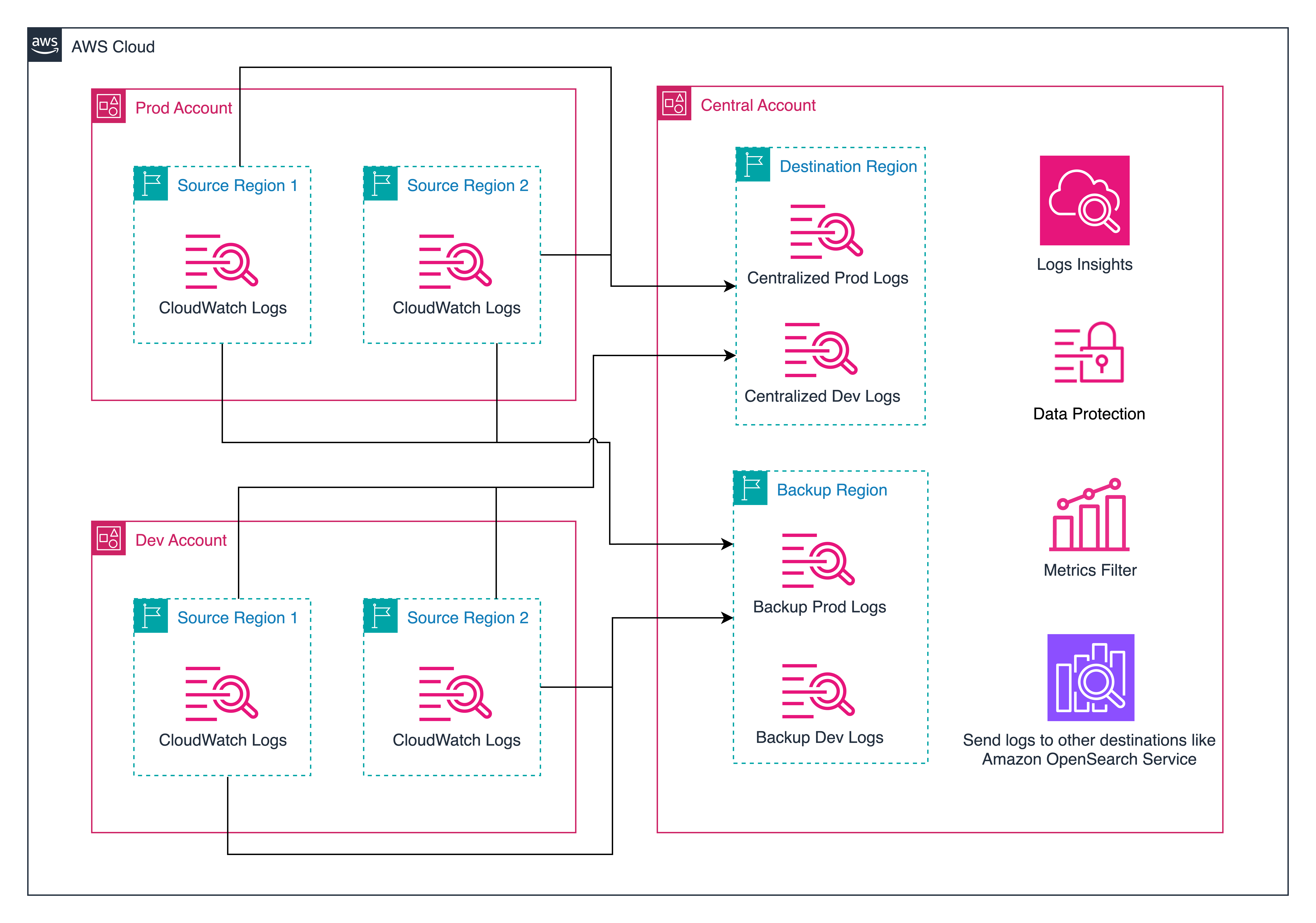
Figure 1:- Consolidating logs across multiple accounts and regions
CloudWatch Logs centralization works with AWS Organizations to define rules that automatically replicate log data based on your exact requirements. You get complete control over what gets centralized, where it goes, and how it’s encrypted—all while maintaining your security boundaries and compliance requirements.
Solution Walkthrough
In this section, we will walk through how you can implement this solution in your environment. For example, imagine you need to consolidate logs from multiple production accounts running in different regions into a central account for improved operational visibility and faster incident response. The following step-by-step guide will show you how to set up log centralization rules, configure your source and destination accounts, and begin centralizing your production logs.
Prerequisites
- Setup AWS Organizations and ensure the source and destination accounts are part of the organization.
- Enable Trusted access for CloudWatch.
- Navigate to CloudWatch console and go to Settings.
- Under Organization tab, click on Turn on trusted access as shown in Figure 2.
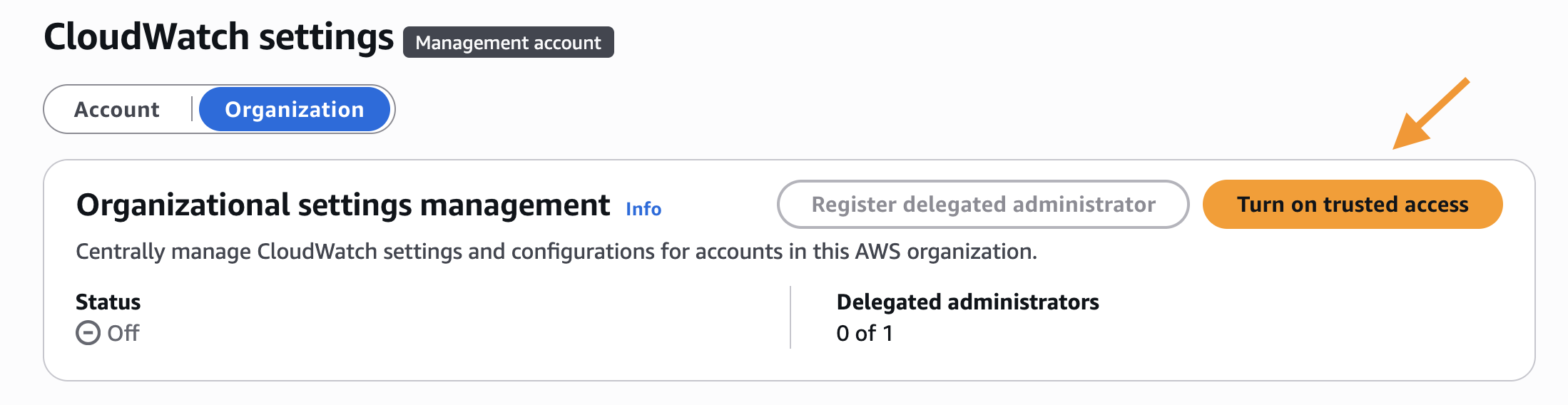
Figure 2: Enabling Trusted access for CloudWatch
- (Optional) Register a delegated administrator. Delegated administrators can choose to deploy CloudWatch features to all accounts in your organization or specific organizational units (OUs).
Setting up Log Centralization rules
Follow the below steps to create a centralization rule that replicates log data from source accounts to your destination account.
- Navigate to the CloudWatch console in the Management or Delegated Administrator account of the organization.
- Choose Settings and navigate to the Organization.
- Choose Configure rule.
- Specify source details
- Specify a rule name (ex:-
production-logs-central) - Select the
Source accountseither by Account ID or OU ID or select the entire Organization ID. - Select
Source Regionsfrom where you want to select the logs for consolidation as shown in Figure 3.
- Specify a rule name (ex:-
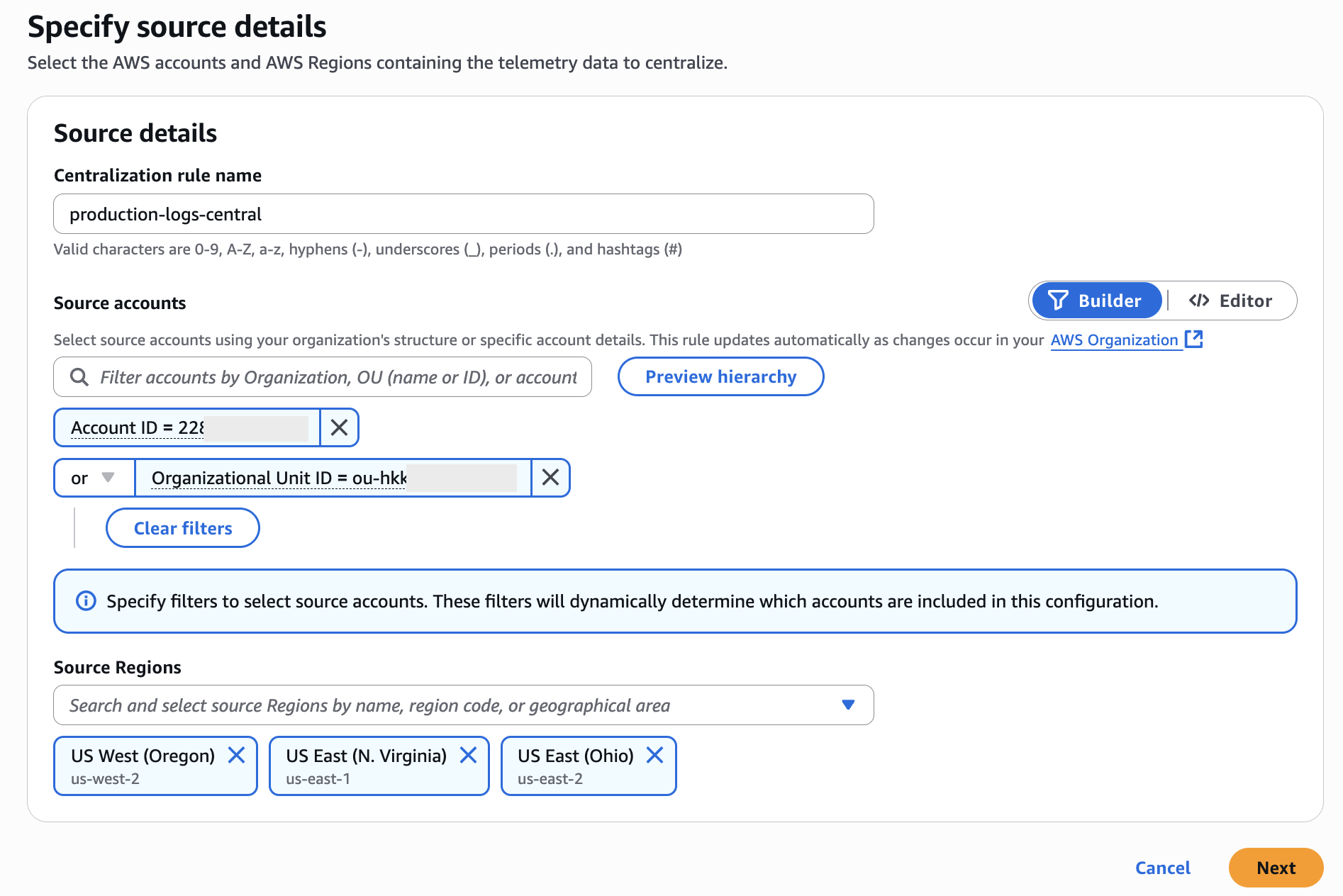
Figure 3:- Specifying Source Details for Log Centralization
- Choose Next
- Specify the destination details by selecting the destination account and Region as shown in Figure 4. You can also specify a backup Region within your destination account to maintain a synchronized copy of your logs, ensuring data availability if the primary Region experiences an outage.
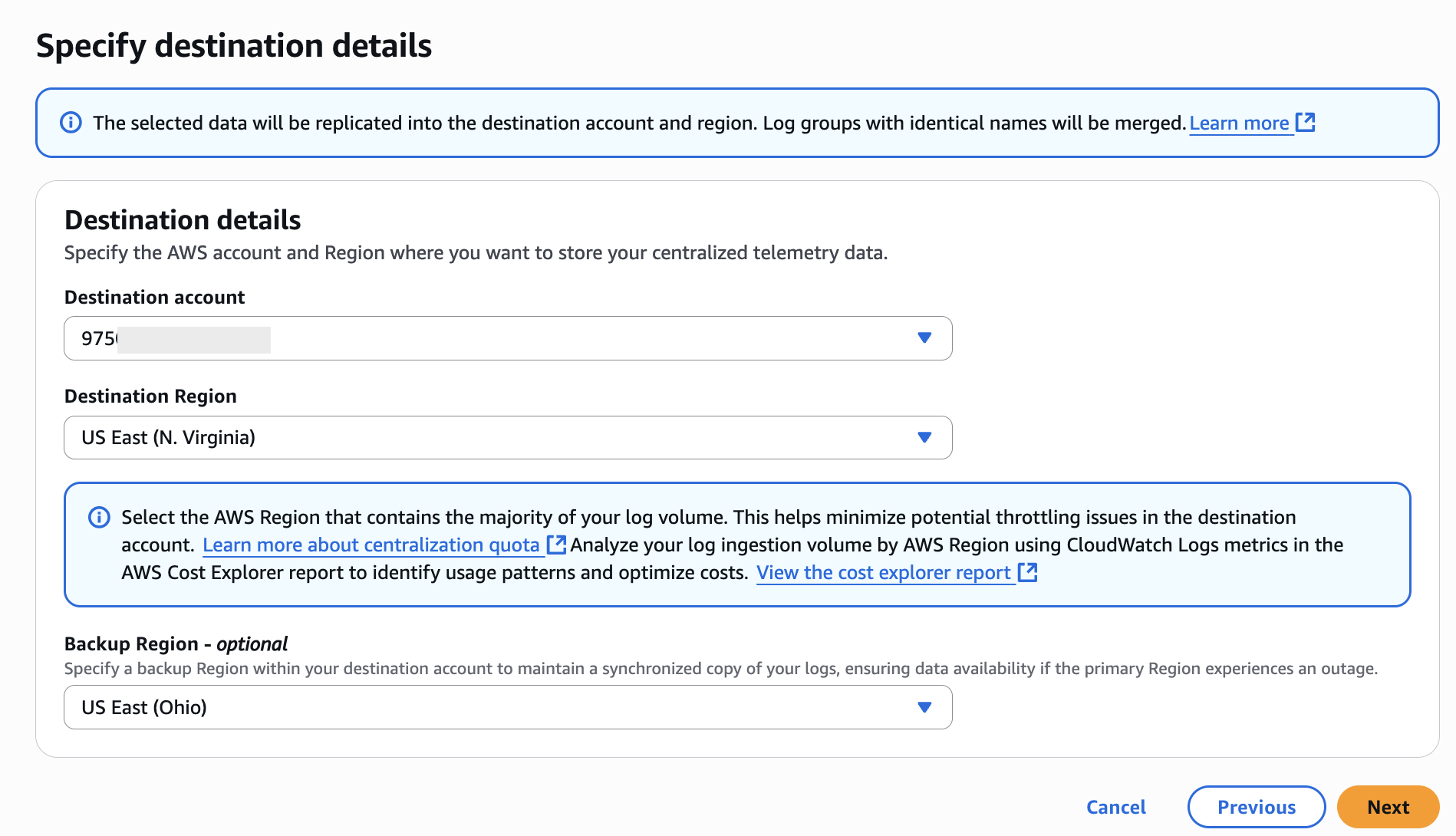
Figure 4:- Specifying Destination Details for Log Centralization
- Next, specify telemetry data by setting the following fields, then choose Next:
- Select either All log groups or select Filter Log groups and specify the log groups that you want to consolidate as shown in Figure 5.
- Supported syntax for log group selection criteria:
- Supported Keys:
LogGroupName | * - Supported Operators:
= | != | IN | NOT IN | AND | OR | LIKE | NOT LIKE
- Supported Keys:
- To handle the KMS encrypted logs groups, you will have the following options
- Centralize log groups encrypted with AWS KMS key in destination account with AWS KMS key.
- This option will centralize encrypted log groups from source accounts to the destination using the provided destination KMS key ARN
- If you select this option, you must provide destination encryption key ARN and a backup destination encryption key ARN (needed only if you selected backup Region in previous step)
- Specified KMS Key must have permissions for the CloudWatch Logs to Encrypt. For more information, please see Step 2: Set permissions on the KMS key.
- Centralize log groups encrypted with AWS KMS key in destination account without AWS KMS key.
- This option will centralize the KMS-encrypted log groups in source accounts without encryption in the destination account
- Do not centralize log groups encrypted with AWS KMS key.
- This option makes sure that the log groups with AWS KMS encryption in source accounts will not be centralized
- Centralize log groups encrypted with AWS KMS key in destination account with AWS KMS key.
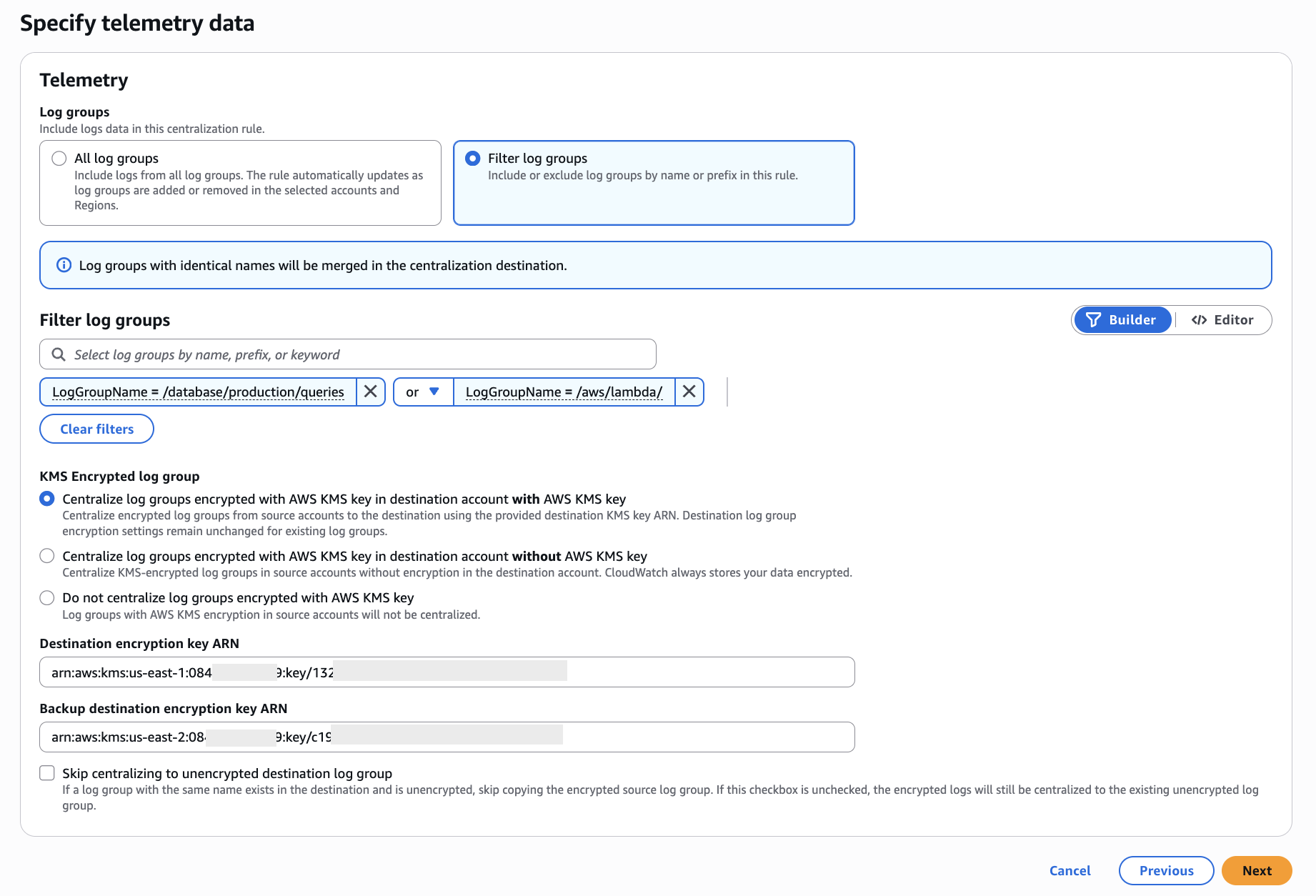
Figure 5: Specify telemetry data for Log Centralization
- In the Review and configure page, review all the details and click Create centralization rule.
After the centralization rule is created and activated, log events will begin consolidating into the central account. Log groups with identical names are merged to streamline log management, while log streams are appended with their originating source account ID and source Region identifiers as shown in Figure 6. Additionally, log events are enriched with new system fields (@aws.account and @aws.region), enabling clear traceability of the log data’s origin.
NOTE: CloudWatch log centralization feature only processes new log data that arrives in source accounts after you create the centralization rule. Historical log data (logs that existed before rule creation) is not centralized.
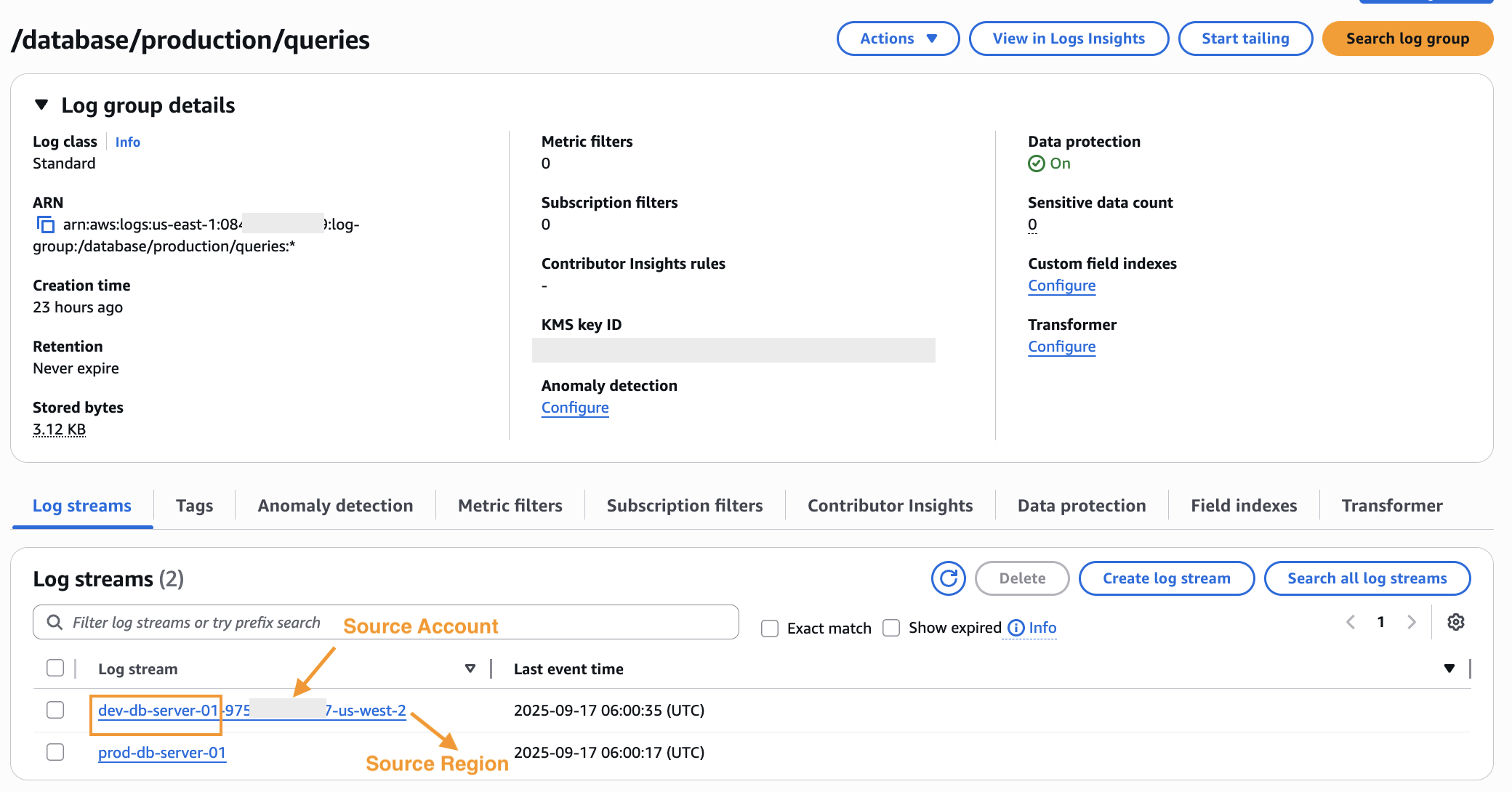
Figure 6: Centralized Logs in the destination account
Monitoring the centralization rule health
Once the rule is active, you can check the status of its health using console as shown in Figure 7 or programmatically using GetCentralizationRuleForOrganization API
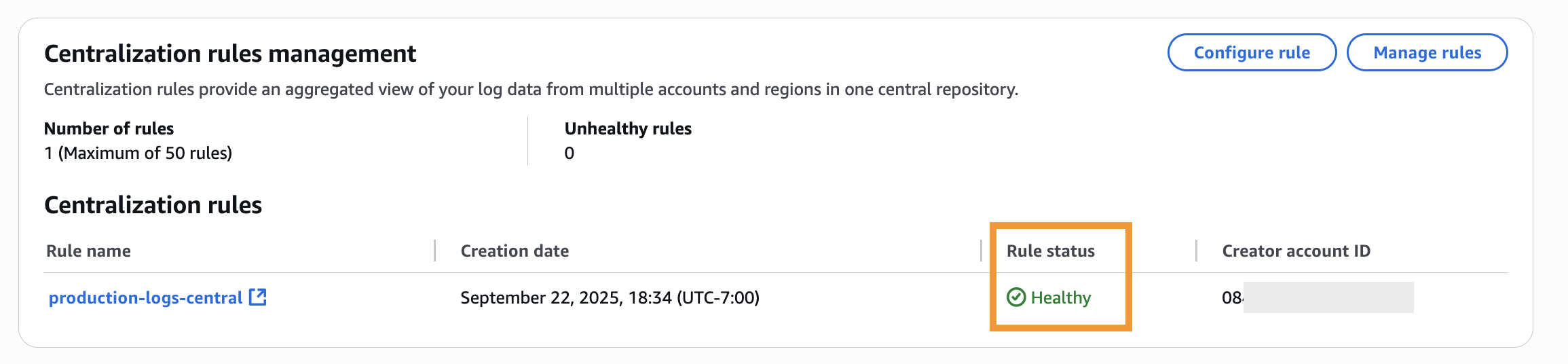
Figure 7: Monitoring centralization rule health
Rule health statuses include:
- HEALTHY: The rule is operating normally and replicating log data as configured
- UNHEALTHY: The rule has encountered issues and may not be replicating data correctly
- PROVISIONING: Centralization for the organization is in the process of being set up.
When a rule is marked as UNHEALTHY, the FailureReason field provides details about the specific issue that needs to be addressed.
Unified Analytics using centralized logs
Once your logs are centralized, you unlock powerful analytical capabilities that were impossible with distributed logs. With the addition of @aws.account and @aws.region system fields, you can transform how you troubleshoot and analyze at scale. These fields are automatically indexed to help you query the results faster. In the example below, CloudWatch Logs Insights demonstrates a query that displays timestamp, account, Region, message, log stream, and log group fields from the us-west-2 region, limited to 100 entries, as shown in Figure 8.
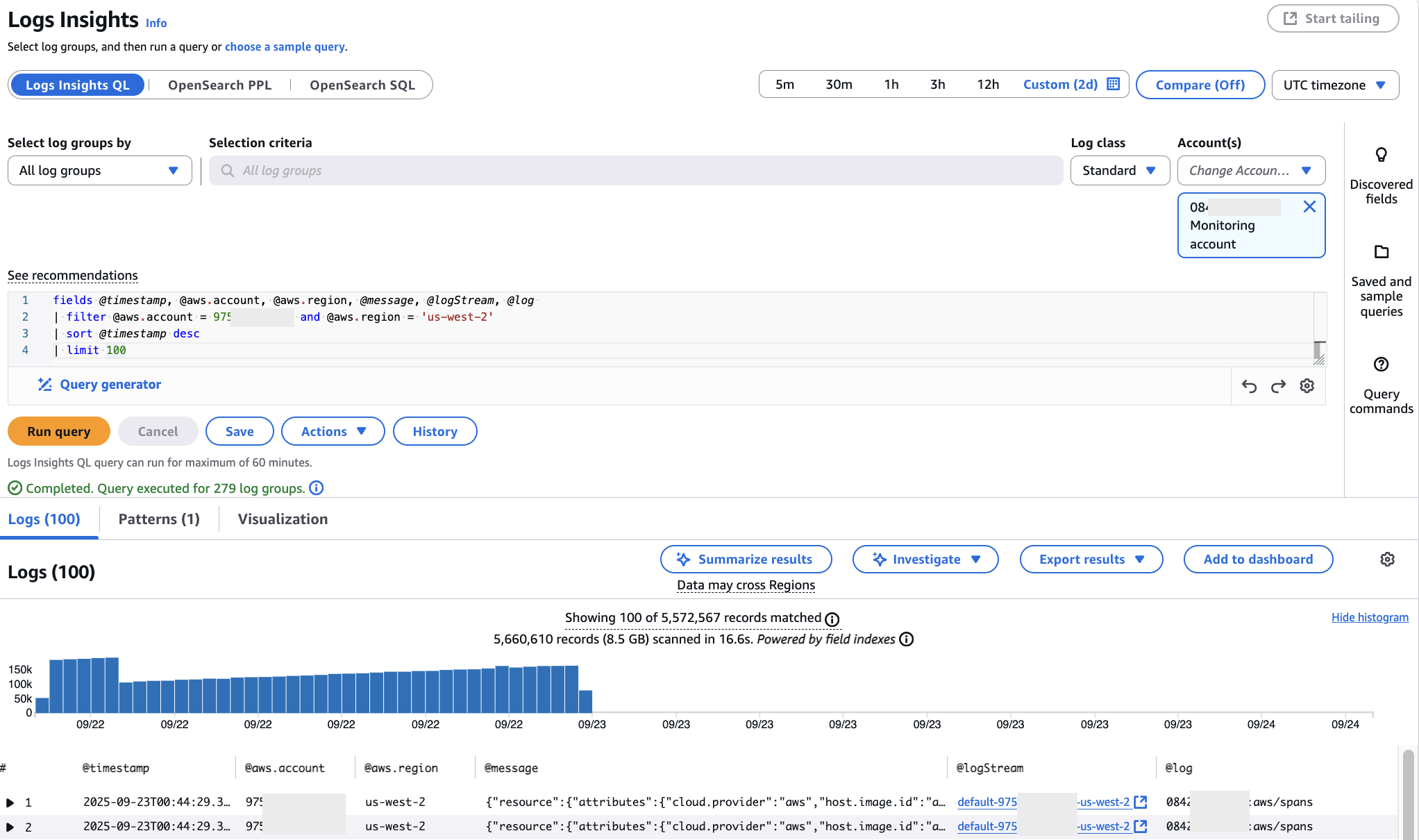
Figure 8: Querying using CloudWatch Log Insights
Here are additional sample queries that demonstrate how to leverage the @aws.account and @aws.region fields for analytics:
1. List failed authentication attempts by account and Region
2. Slow DB query analysis across multiple accounts and Regions
Best Practices for CloudWatch Logs Features
When implementing CloudWatch Logs centralization, following these best practices for CloudWatch features will help you maximize the value of your centralized logs. These practices cover metrics, subscription filters, log transformation, and cost optimization to ensure secure, efficient, and cost-effective log management across your organization.
1. Metrics and Subscription Filters
CloudWatch Logs centralization enables powerful data transformation and integration capabilities through metrics and subscription filters. Organizations can convert their centralized log data into numerical metrics, enabling visualization through graphs and alarm-based monitoring.
For example, you can create metric filters across all your logs regardless of account and Region.
Additionally, you can setup real-time log event streaming through subscription filters, which can seamlessly integrate with various services like Amazon Kinesis stream, Amazon Data Firehose stream, Amazon OpenSearch Service or AWS Lambda. When configuring subscription filters, you can use account, and Region filters to selectively forward logs from specific sources. To include source account and Region information with your log data, enable the @aws.account and @aws.region system fields by selecting them under Emit system fields, as shown in Figure 9.
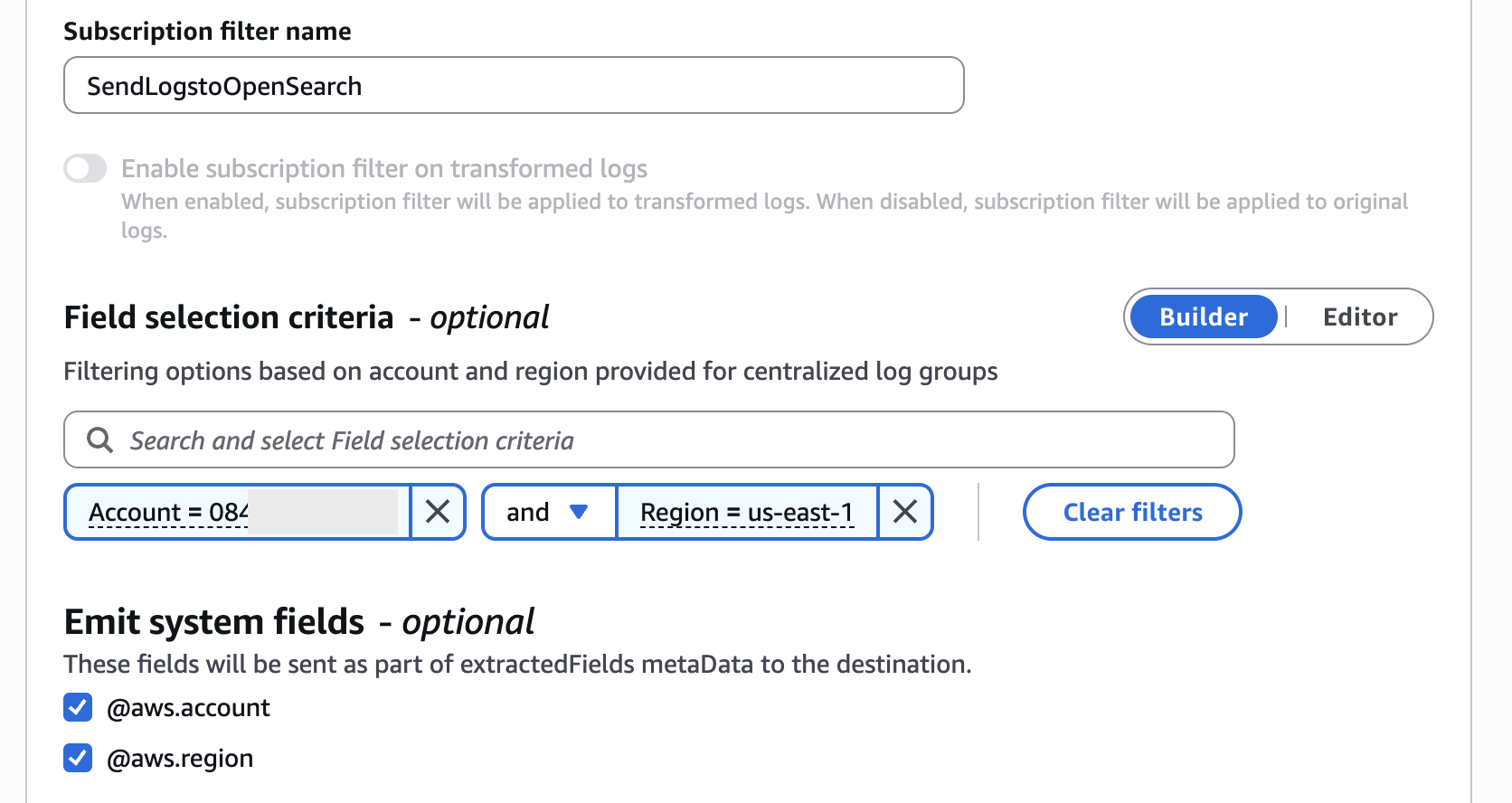
Figure 9: Filtering account and Region fields in subscription filters
2. Logs Transformation
When using CloudWatch Logs centralization, only raw log data is copied from source accounts to the central account. Any log transformations applied during ingestion in source accounts will not be reflected in the centralized logs. For consistent log transformation across your organization, we recommend applying log transformations directly in the central account after the logs are consolidated.
3. Optimizing log storage costs
CloudWatch Logs centralization offers a cost-efficient pricing structure for managing logs across multiple accounts and Regions. The first copy of centralized logs comes with no additional ingestion charges or cross-region data transfer costs, with customers paying standard CloudWatch storage costs and feature pricing. For any subsequent copies beyond the first centralization, there is a charge of $0.05/GB (using the backup Region feature also creates an additional copy). For more information, please see the CloudWatch pricing page. To help you optimize costs while using CloudWatch Logs centralization, we recommend implementing the following best practices:
1. Implement a Tiered Retention Strategy
You can significantly reduce storage costs by implementing a dual-tier retention policy.
- Configure your source accounts with short-term retention periods (7-30 days) to handle immediate operational needs.
- For your centralized account, set longer retention periods (90+ days) to meet compliance requirements and support historical analysis.
2. Use Selective Centralization
When creating additional copies of your logs, be strategic with your centralization approach:
- Leverage log group filters to centralize only specific applications or services
- Identify and centralize only the logs that align with your business requirements
- Avoid centralizing unnecessary log data that doesn’t serve a specific use case
3. BackUp Strategy
Consider these factors when planning your backup strategy:
- Be mindful that backup copies are treated as additional copies and incur a charge of $0.05/GB
- Enable backup centralization only when you have a specific requirement for dedicated backup in a central account
- Consider utilizing your source accounts as backup copies to eliminate additional charges
By implementing these optimization strategies, you can maintain effective log management while controlling your costs.
Conclusion
CloudWatch Logs centralization transforms cross-account and cross-Region log management by providing a native AWS solution that eliminates the complexity of custom log aggregation systems. With features like automatic replication, seamless AWS Organizations integration, cross-Region support, and flexible encryption options, organizations can achieve comprehensive log management with minimal setup time. It delivers immediate value through improved operational efficiency, enhanced security posture, and faster incident resolution. To get started, please see Cross-account cross-Region log centralization documentation.