AWS Developer Tools Blog
Provision AWS infrastructure using Terraform (By HashiCorp): an example of web application logging customer data
Many web and mobile applications can make use of AWS services and infrastructure to log or ingest data from customer actions and behaviors on the websites or mobile apps, to provide recommendations for better user experience. There are several ‘infrastructure as code’ frameworks available today, to help customers define their infrastructure, such as the AWS CDK or Terraform by HashiCorp. In this blog, we will walk you through a use case of logging customer behavior data on web-application and will use Terraform to model the AWS infrastructure.
Terraform by HashiCorp, an AWS Partner Network (APN) Advanced Technology Partner and member of the AWS DevOps Competency, is an infrastructure as code tool similar to AWS CloudFormation that allows you to create, update, and version your Amazon Web Services (AWS) infrastructure. Terraform provide friendly syntax (similar to AWS CloudFormation) along with other features like planning (visibility to see the changes before they actually happen), graphing, create templates to break configurations into smaller chunks to organize, maintain and reusability. We will leverage the capabilities and features of Terraform to build an API based ingestion process into AWS. Let’s get started!
We will provide the Terraform infrastructure definition and the source code for an API based ingestion application system for websites and applications to push user interactions, such as user clicks on their website into database hosted on AWS. The data ingestion process is exposed with an API Gateway endpoint. The Amazon API Gateway processes the incoming data into an AWS Lambda during which the system validates the request using a Lambda Authorizer and pushes the data to a Amazon Kinesis Data Firehose. The solution leverages Firehose’s capability to convert the incoming data into a Parquet file (an open source file format for Hadoop) before pushing it to Amazon S3 using AWS Glue catalog. Additionally, a transformational/consumer lambda does additional processing by pushing it to Amazon DynamoDB.
The data hosted in Amazon S3 (Parquet file) and DynamoDB can be eventually used for generating reports and metrics depending on customer needs, such as monitor user experience, behavior and provide better recommendations on their website. Per the needs for scale of the application you can use Amazon Kinesis and Amazon Kinesis Firehose Streams separately or in combination to scale, ingest and process your incoming data faster and cost efficiently. For example, AWS Lambda now supports the Kinesis Data Streams (KDS) enhanced fan-out and HTTP/2 data retrieval features for Kinesis event sources. The HTTP/2 data retrieval API improves the data delivery speed between data producers and Lambda functions by more than 65%. This feature is available wherever AWS Lambda is available. Refer to best practices on how to scale applications that ingest data via Kinesis Streams and other use cases for using AWS API Gateway with Lambda Authorizers.
The following steps provide an overview of this implementation:
- Java source build – Provided code is packaged & build using Apache Maven
- Terraform commands are initiated (provided below) to deploy the infrastructure in AWS.
- An API Gateway, S3 bucket, Dynamo table, following Lambdas are built and deployed in AWS —
- Lambda Authorizer – This lambda validates the incoming request for header authorization from API gateway to processing lambda.
- ClickLogger Lamba – This lambda processes the incoming request and pushes the data into Firehose stream
- Transformational Lambda – This lambda listens to the Firehose stream data and processes this to DynamoDB. In real world these lambda can more additional filtering, processing etc.,
- Once the data “POST” is performed to the API Gateway exposed endpoint, the data traverses through the lambda and Firehose stream converts the incoming stream into a Parquet file. We use AWS Glue to perform this operation.
- The incoming click logs are eventually saved as Parquet files in S3 bucket and additionally in the DynamoDB
Prerequisites
- Make sure to have Java installed and running on your machine. For instructions, see Java Development Kit
- Apache Maven – Java Lambdas are built using mvn packages and are deployed using Terraform into AWS
- Set up Terraform. For steps, see Terraform downloads
- An AWS Account
Walkthrough
At a high-level, here are the steps you will follow to get this solution up and running.
- Download the code and perform maven package for the Java lambda code.
- Run Terraform command to spin up the infrastructure.
- Use a tool like Postman or browser based extension plugin like “RestMan” to post a sample request to the exposed API Gateway endpoint
- In AWS Console, confirm that process runs after the API Gateway is triggered. Notice the parquet file is created in S3 bucket and corresponding row is triggered in the DynamoDB Table.
- Once the code is downloaded, please take a moment to see how Terraform provides a similar implementation for spinning up the infrastructure like that of AWS CloudFormation. You may use Visual Studio Code or your favorite choice of IDE to open the folder (aws-ingesting-click-logs-using-terraform).
Downloading the Source Code
The provided source code consists of the following major components —(Refer to corresponding downloaded path on the provided below)
- Terraform templates to build the infrastructure – aws-ingesting-click-logs-using-terraform/terraform/templates/
- Java Lambda code as part of resources for Terraform to build – aws-ingesting-click-logs-using-terraform/source/clicklogger
Deploying the Terraform template to spin up the infrastructure
When deployed, Terraform creates the following infrastructure.

Provision AWS infrastructure using Terraform (By HashiCorp): an example of web application logging customer data
You can download the source from the GitHub location. Below steps will detail using the downloaded code. This has the source code for Terraform templates that spins up the infrastructure. Additionally, Java code is provided that creates Lambda. You can optionally use the below git command to clone the repository as below
$ git clone https://github.com/aws-samples/aws-ingesting-click-logs-using-terraform/
$ cd aws-ingesting-click-logs-using-terraform
$ cd source\clicklogger
$ mvn clean package
$ cd ..
$ cd ..
$ cd terraform\templates
$ terraform init
$ terraform plan
$ terraform apply --auto-approve
Once the preceding Terraform commands complete successfully, take a moment to identify the major components that are deployed in AWS.
- API Gateway
- Click-logger-api
- Method – POST
- Method Request – clicklogger-authorizer
- Integration Request – Lambda
- Authorizer – clicklogger -authorizer
- Stage – dev
- Click-logger-api
- AWS Lambda
- Clickloggerlambda
- Clickloggerlambda-authorizer
- Clicklogger-lambda-stream-consumer
- Amazon Kinesis Data Firehose
- Delivery stream – click-logger-firehose-delivery-stream
- S3
- Click-logger-firehose-delivery-bucket-<your_account_number>
- Dynamo Table
- clicklogger-table
- CloudWatch – Log Groups
- /aws/kinesis_firehose_delivery_stream
- /aws/lambda/clickloggerlambda
- /aws/lambda/clickloggerlambda-stream-consumer
- /aws/lambda/clickloggerlambda-authorizer
- API-Gateway-Execution-Logs_<guid>
Testing: post a sample request to the exposed API Gateway endpoint
- In AWS Console, select API Gateway. Select click-logger-api
- Select Stages on the left pane
- Click dev > POST (within the /clicklogger route)
- Copy the invoke Url. A sample url will be like this – https://z5xchkfea7.execute-api.us-east-1.amazonaws.com/dev/clicklogger
- Use REST API tool like Postman or Chrome based web extension like RestMan to post data to your endpoint
Add Header: Key Authorization with value ALLOW=ORDERAPP. This is the authorization key token used by the lambda. This can be changed in the lambda.tf. In external facing web applications, make sure to add additional authentication mechanism to restrict the API Gateway access
Sample Json Request:
{
"requestid":"OAP-guid-12345-678910",
"contextid": "OAP-guid-1234-5678",
"callerid": "OrderingApplication",
"component": "login",
"action": "click",
"type": "webpage"
}{
“requestid”:”OAP-guid-12345-678910″,
“contextid”: “OAP-guid-1234-5678”,
“callerid”: “OrderingApplication”,
“component”: “login”,
“action”: “click”,
“type”: “webpage”
}
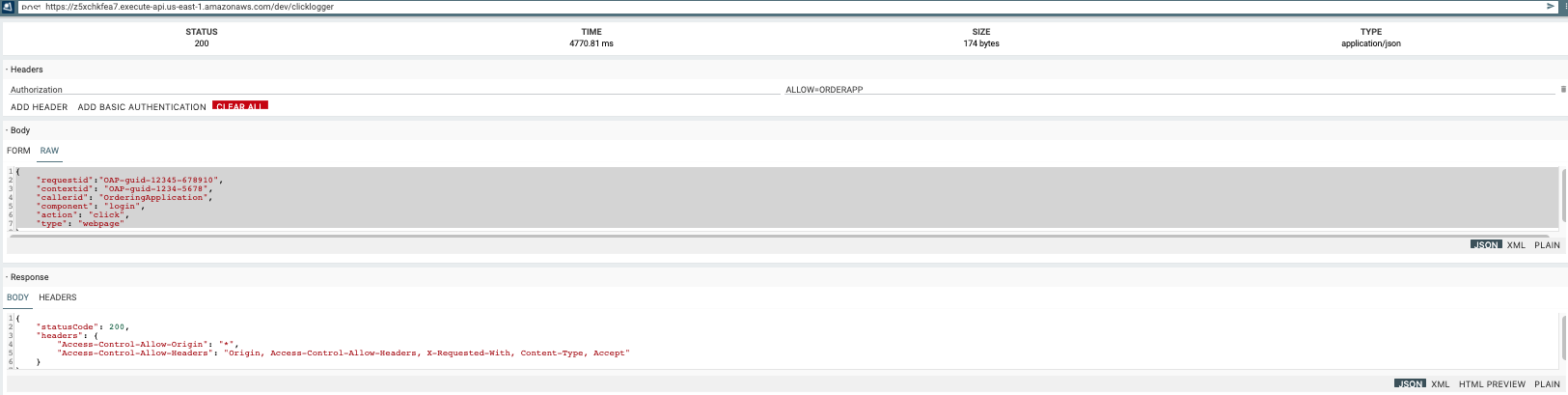
- You should see the output in both S3 bucket and DynamoDB
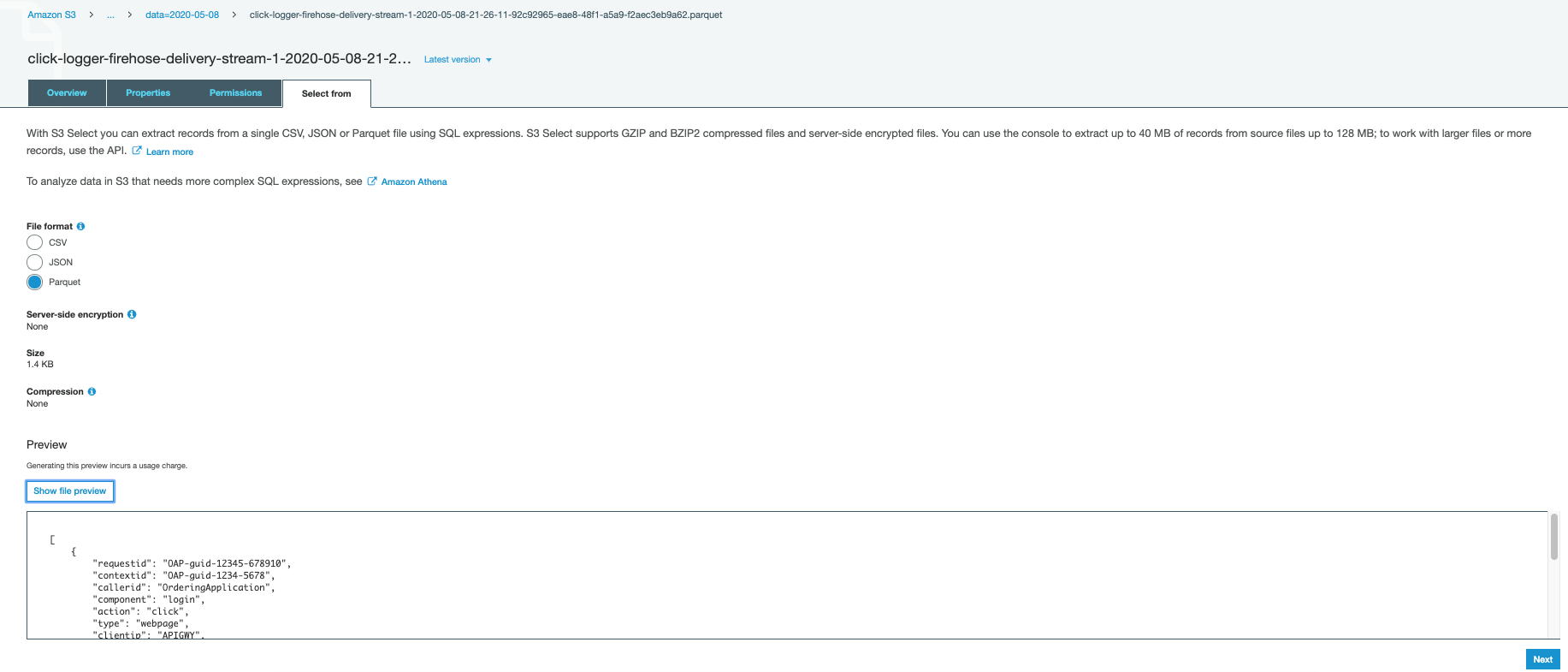
- S3 – Navigate to the bucket created as part of the stack
- Select the file and view the file from Select From sub tab . You should see something ingested stream got converted into parquet file.
- Select the file. An example will be like below
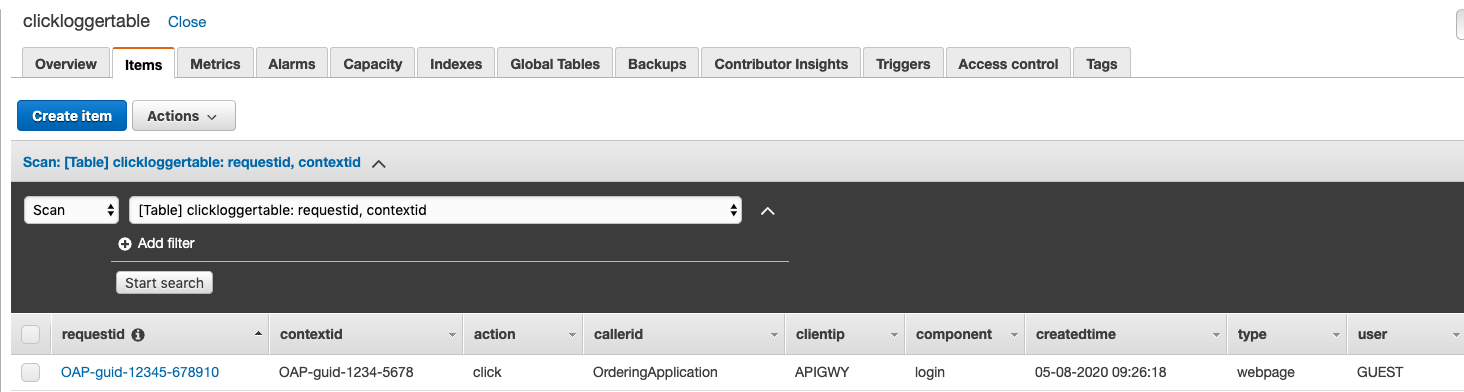
- DynamoDB table —Select clickloggertable and view the items to see data.
Sample screenshot
Clean up instructions
Terraform destroy command will delete all the infrastructure that were planned and applied. Since the S3 will have parquet file generated, make sure to delete the file before initiating the destroy command. This can be done either in AWS Console or using AWS CLI (commands provided). See both options below
- Clean up resources from the AWS Console
- Open AWS Console, select S3
- Navigate to the bucket created as part of the stack
- Delete the S3 bucket manually
- Clean up resources using AWS CLI
# CLI Commands to delete the S3
$ aws s3 rb s3://click-logger-firehose-delivery-bucket-<your-account-number> --force
$ terraform destroy –-auto-approveConclusion
You were able to launch an application process involving Amazon API Gateway which integrated with various AWS services. The post walked through deploying a lambda packaged with Java using maven. You may use any combination of applicable programming languages to build your lambda functions. The sample provided has a Java code that is packaged for Lambda Function.
For the authorization of the flow, we used Lambda Authorizer with header based token mechanism. Make sure to use additional authentication mechanisms also restrict the API Gateway to specific clients/application. AWS Glue catalog is used to handle the incoming data and is converted into parquet files. This can be implemented with CSV/Json and/or in other formats also. The blog provides an architecture to stream the data into AWS infrastructure. The data can be even sourced to Amazon Elastic Search Service, Amazon Redshift or Splunk based on specific needs. This can be eventually used for reporting or visualization
If you decide to give it a try, have any doubt, or want to let me know what you think about the post, please leave a comment!
References
- Terraform: Beyond the basics with AWS
- API Management strategies
- Amazon Kinesis
- API Gateway with Lambda Authorizers
About the authors
 Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at AWS. His expertise is in application optimization, serverless solutions and using Microsoft application workloads with AWS.
Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at AWS. His expertise is in application optimization, serverless solutions and using Microsoft application workloads with AWS.