AWS for Games Blog
How NaturalMotion Migrated Dawn of Titans to Amazon EKS

Running games as services can have some serious perks. Players get to enjoy their favourite games for longer, and developers can see ongoing success from a single game for years.
But games with longer lifespans can also generate heavy overheads for development teams. Game studios are expected to deliver new experiences to players in increasingly tight timeframes, all while juggling maintenance of live games – and with limited engineering resources.
That’s the situation that Zynga subsidiary NaturalMotion found itself in 2019. Originally published in 2016, the action strategy game Dawn of Titans continues to maintain a lasting community by bringing console quality graphics and compelling gameplay to mobile audiences.
The success of Dawn of Titans has led NaturalMotion to handle millions of player battles every day. So the question is, how does any developer process that amount of data, let alone develop additional game features? NaturalMotion Engineering Manager, Siva Ganesamoorthy shared, “since launch, Dawn of Titans has relied on Amazon Elastic Compute Cloud (Amazon EC2) to power its core services infrastructure. Until 2018, we containerized workloads to power our game application as well as several other microservices,” but this posed multiple challenges for the team.
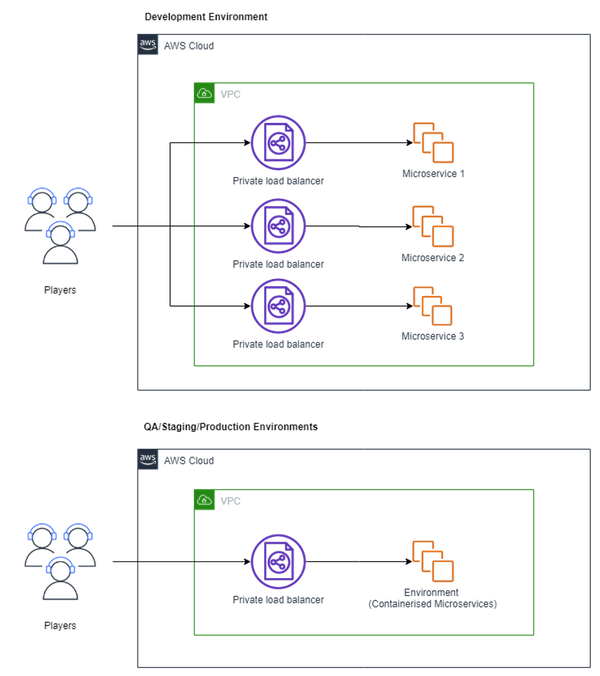
Fig a – NaturalMotion legacy architecture
“We had insufficient monitoring and alerting capabilities. We couldn’t immediately tell if a drop in concurrent users was the result of an outage on a dependent system that our core services integrated with. We depended heavily on our site reliability team to ensure our production cluster had a reasonable SLA,” said Siva.
“Our development and QA stacks also weren’t representative of our production set up. That meant everything developed and tested potentially missed issues that were only seen in our production environment.” To resolve this problem, NaturalMotion introduced a staging stack to mirror production. “This allowed us to perform load tests and gameplay at scale, but it didn’t solve everything. It introduced an extra step outside of our core development cycle.”
Migrating to a simpler life
To reduce the burden on the Dawn of Titans development team, it began to investigate ways to simplify and automate their architecture. “We evaluated Kubernetes, Mesos, and Docker Swarm. We ended up choosing Kubernetes because even though the technology was considered cutting-edge, we felt it was pretty mature. AWS also offered Amazon Elastic Kubernetes Service (Amazon EKS), a managed service that handles most of the heavy lifting for us.” explained Siva.
Once the decision was made to migrate to Amazon EKS, Siva and his team created a roadmap for moving their live game. “Running a live game meant that we couldn’t simply bring the game down to introduce a new architecture. Instead, we introduced our Dev and QA environments to the new cluster first before weighting production traffic between our legacy infrastructure and Amazon EKS. It took us 8 weeks to go from 0 – 100% of production traffic on our new Amazon EKS cluster.”

Fig b – simpler and consistent set up by NaturalMotion now have across all Dawn of Titans environments
During migration – the Zeus event
Dawn of Titans ran its largest live event at the time. Highly anticipated by players, the Zeus event was the culmination of a 7 month long ‘Greek Gods’ campaign which saw mythical Gods like Athena, Poseidon, and Hades appear in the game as powerful Titans.
During the five-day event, battles increased by over 200% as players joined to celebrate the addition of the brand-new Titan, Zeus. “We were running 20% of our Production traffic through our new Kubernetes cluster. We experienced an increase in traffic 4x our baseline in under a minute. Our monitoring data ingestion failed to cope with the very sudden increase in requests to our game servers and for a period of 5 mins, we were riding blind wondering if the game had gone down,” said Siva.

Fig c – Kubernetes Cluster (handling 20% of all requests)
“What happened was an incredible experience for our team. Our legacy infrastructure, which was handling 80% of all requests, scaled up and started to respond to requests properly in 45 mins. Amazon EKS managed this within 15 minutes.”
What NaturalMotion had previously understood but not experienced at scale, was the self-healing of Kubernetes; “we saw Amazon EKS self-heal quickly during the Zeus event, and we later discovered that our over-provisioning pods had been set up incorrectly. Had there been over-provisioned pods available, Amazon EKS could have handled requests within 10 mins of receiving the initial spike of traffic,” Siva shared.

Fig d – Legacy Infrastructure (handling 80% of all requests)

Fig e – Legacy Infrastructure experiencing severe load
“The experience we had during the Zeus event vindicated our decision to migrate to Amazon EKS. We sunset our legacy infrastructure soon after the migration and have been running on our new Kubernetes cluster without any issues for the last 2 years,” Siva continued.

Fig f – NaturalMotion’s Amazon EKS cluster
Learnings
One of the biggest learnings NaturalMotion had after migrating was it had under estimated the maintenance of the Kubernetes ecosystem. “Our team isn’t set up as a dedicated DevOps team. We very quickly found ourselves having to upgrade our Kubernetes clusters every 3 to 4 months,” Siva explained. “Given we had 3 clusters, this meant that we had to put a lot of test coverage on our development cluster before moving on to our staging and production clusters. We also used Helm 2 within our clusters at the time which brought about other complexities.”
When you’re working with cutting-edge technology, your innovation journey should always prepare for a little turbulence along the way. Siva said, “You have to be prepared for components to sunset or for breaking changes to happen regularly between component versions or Kubernetes Version updates.” And NaturalMotion found itself in this position a number of times. “For example, Helm 2 was being deprecated and so we had to ensure that all the Helm charts that our clusters relied on were upgradeable to Helm 3.”
But for Siva and his team, the biggest learning is dependency. “We relied on system components from quay.io, a Red Hat container repository,” Siva shared. In May 2020, quay.io suffered a major outage, leading its production cluster to suffer scaling issues. Siva continued, “certain system pods were failing to come up because images couldn’t be pulled down, impacting cluster availability over a few hours. We had to closely monitor and run our cluster at about 85% availability.” When quay.io recovered, NaturalMotion began pulling images down and pushing them into Amazon ECR. “We updated our clusters to pull images from Amazon ECR. Today, we have automated jobs in our build pipeline to help us keep track of this and pull appropriate versions that our clusters require.”
Siva concluded, “for teams looking into Kubernetes and wondering if they should perform a similar migration to what we did here at NaturalMotion, there’s a huge learning curve. Our advice would be to understand the ecosystem and to plan appropriately based on the experience of your team. It took us 6 months from planning to running Production traffic in EKS, however that time was very well spent and the benefits speak for themselves. Since we migrated, we have improved and added automation to our cluster and reduced the overhead for maintaining each of our clusters.”