AWS for Industries
Architecting for Resilience in the cloud for critical railway systems
Introduction
With the successful use of cloud computing in the IT space (analytics, simulation and workflow management), companies in highly regulated industries, such as railways, increasingly look at also migrating their OT systems (control systems, real-time monitoring, and transaction management) into the cloud. The main motivations for this are to achieve high availability and redundancy though increasing flexibility of global deployment, reducing the heavy lifting of IT lifecycle management through pay-per-use models, and reducing their maintenance efforts and security exposure through proven services and automation.
While the business drive to move into the cloud for critical workloads increases, proven and standardized methods to assess security and reliability in these systems are often based on paradigms that predate the existence of cloud providers. For instance, achieving function of compute equipment traditionally focuses on reducing failures and faults of each individual hardware component involved because each failure entails substantial (and often manual) effort. In contrast to that, hardware in the cloud is virtualized and replaceable, such that the focus lies on quick detection and automated replacement of faulty equipment. In other words, a paradigm shift in the assessment of IT equipment is required to enable highly regulated industries to move to the cloud and yield its benefits.
In this whitepaper, we dive deeply into the paradigm shifts required and highlight the key concepts and methods that allow businesses to apply reliability and security requirements for critical infrastructure to cloud workloads. More precisely, in this paper we focus on the requirements outlined in DIN EN 50129 that are applicable to safety- related electronic systems (including subsystems and equipment) for railway signaling applications. While we use this standard to serve as a guide for identifying central challenges and questions, the same concepts also apply to other industries, in particular, the broader DIN EN 61508 covering the functional safety of control systems.
The key concept of functional safety
The key concept behind safety-critical systems is to achieve functional safety. After introducing aspects of this key concept, we show how it manifests in EN 50129 for the railway industry.
What is the target of functional safety?
Formally, the objective of functional safety is elimination of unacceptable risk of physical injury or of damage to the health of people either directly or indirectly (through damage to property or to the environment) by the proper implementation of one or more automatic protection functions (often called safety functions).
Colloquially, working towards functional safety means to take measures that ensure a system performs its functions as intended by reducing known risks and protecting against unknown and unpredictable ones. For IT systems, this means that known risks, from environmental to equipment malfunctions or coding errors, are minimized in their impact.
How is functional safety achieved?
The exact procedures to achieve functional safety vary depending on industry, equipment, and application. At the same time, there are some common steps that are usually involved.
Functional safety typically requires assessing what function and level of performance is required from equipment, identifying the risks to achieve that performance (SIL, ASIL,…), mitigating any risks through redundant system design or resilience, and validating the achievement of the performance levels.
Applicability of norms to cloud infrastructure as “pre-existing items”
Within existing normative bodies, IT equipment typically falls into a category of “pre-existing items” that are to be used as part of the larger system and not developed based on the standard in question [For EN50129, Sec. 6.2.1]. Using such items is considered only as a concession to economic viability and is therefore limited to items that are used in a market in large quantities. It is also used where application of the detailed requirements of the process cannot be followed because doing so retroactively is too complex. Computer systems, such as cloud compute, as part of a larger OT system that meets all of these conditions, as one would also expect intuitively and especially for IT equipment in the cloud.
When using pre-existing equipment in the context of a larger system, functional safety sets out the requirements for the integration rather than the equipment itself. On a high level, these requirements are based on treating the item as a black box (specifically, internal processes are not considered). For such a black box, it then stipulates to:
- Collect information about the device, its function, and environment to ensure operational and environmental risks to the function are taken into account.
- Collect information about the risk of hazardous failure modes, specifically, the different reasons preventing the item from expected functioning to assess its suitability for the required performance level.
- Integrate the item in the overarching systems in such a way that validation, verification, and assessments are undertaken to protect its safety function.
Hence, to apply these norms to cloud infrastructure, we need to understand each of these points.
Consideration 1: Information about cloud equipment and environmental hazards
In the cloud, Amazon Web Services (AWS) and its customers share control over the IT environment and both parties have responsibility for managing the IT environment. The AWS role in this shared responsibility includes providing its services on a highly secure and controlled platform along with a wide array of security features customers can use. The customers’ responsibility includes configuring their IT environments in a secure and controlled manner for their purposes. While customers don’t communicate their use and configurations to AWS, AWS does communicate its security and control environment relevant to customers. AWS certifications does this by doing the following:
- Obtaining industry certifications and independent third-party attestations.
- Publishing information about the AWS security and control practices in whitepapers and web site content.
- Providing certificates, reports, and other documentation directly to AWS customers under a non-disclosure agreement (NDA).
- Policies that address environmental hazards and equipment protection
Since the IT equipment under question is located within AWS data centers, collection of information pertains to the standards and procedures that AWS sets in protecting data centers and the equipment therein. More precisely, AWS has strict controls and policies in place that govern, for instance, how suitable locations for data centers are chosen based on environmental risks and how the equipment’s electromagnetic integrity is protected. For instance, these policies outline the guidelines for protecting the equipment against unauthorized access, as well as the standards followed for maintenance.
More details around the controls and policies are available in the AWS Compliance Space.
Certifications regarding equipment protection
Based on these policies, AWS has achieved various certifications for its part of the shared responsibility that customers can build on. This information is detailed in a separate whitepaper, “Amazon Web Services: Risk and Compliance.” It includes the numerous industry certifications that AWS holds around cybersecurity, such as CSA, FedRamp, ISO 27001, and those certifications provided in AWS Artifacts. It also includes SOC 3 certifications around organizational assurance. Comprehensive information is available on the AWS Compliance Programs page.
Consideration 2: Understanding and mitigating failure modes for cloud equipment
The central consideration for achieving functional safety is to understand and mitigate the known functional at a high degree of reliability as much as required to achieve a suitable level of performance. Some of these hazards are the same in both IT and cloud equipment (for example, protecting the system consistency against random hardware failures, such as spontaneous byte-flips or corruption of memory). Others, in particular the networked reachability and processing capabilities of the equipment, are typically lumped together into overall failure hazards to availability. They are lumped together rather than broken out separately as one would with an on-premises system.
Ultimately, the procedure to establish system availability is the same in both approaches. On the one hand, one needs to analyze the failure hazard itself, which has two components: 1) the probability of occurrence and 2) the impact of the occurrence.
Hence, for the different failure modes, one can always both minimize the probability of occurrence and mitigate the impact to reduce the risk to the required level.
Protecting the system storage against random hardware failures (durability)
Random failures, such as a random byte-flip of a system memory, happen in virtually any hardware in the cloud as on premises due to inherent electromagnetic properties. One can mitigate the probability of occurrence by using high-quality hardware. At the same time, one can avoid a consequent system failure by using systematic consistency checks and redundant operations that identify when such a failure has occurred.
Figure 1: Cloud and on-premise comparison to minimize hardware failures
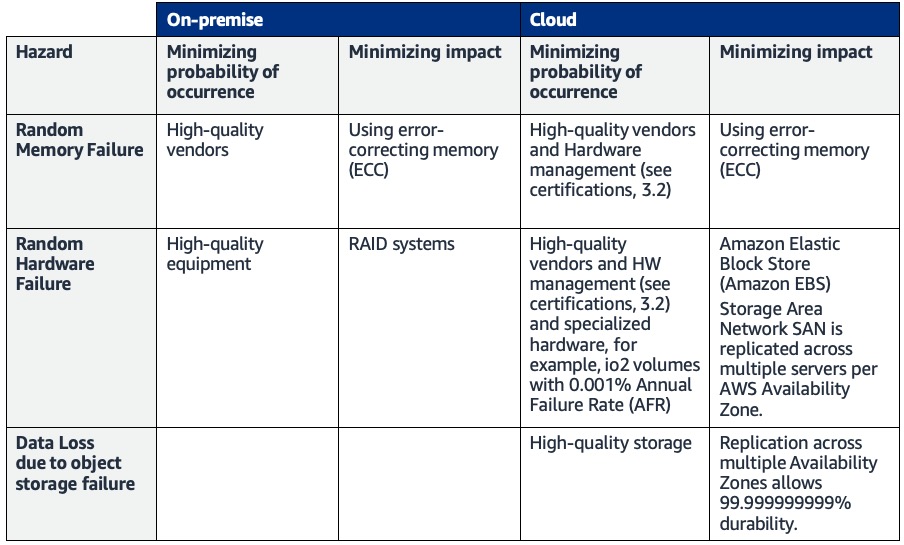
In summary: AWS uses ECC memory (which is 100 times more durable than non-ECC memory) as this is state-of-the-art technology. ECC memory offers the same or better performance as one would get in other environments. For storage and disks AWS relies on redundancy from network storage systems, offering different levels of durability according to customer needs. Ultimately, the question of achieving a suitable level of performance, therefore, means choosing a storage class suitable for the application in question.
In the following table, we denote the options for achieving the desired level of performance.
Figure 2: Failure rate comparison of equipment (View details)

Maintaining availability of a system in the cloud under equipment failures
For the IT equipment on AWS to provide its functionality to the overarching system, it is necessary for the system to have sufficiently high availability so that it can provide its function according to the performance targets. In traditional systems, this was achieved by focusing on high-quality processing and low failure rates for each equipment in the overall system. Doing so would ensure full availability or add redundant equipment where needed while the failed equipment is repaired. In other words, the main driver of cost-effective yet highly available systems has been increased robustness (measured as mean-time-between-failure) of each equipment or compute instance. However, in the cloud, where equipment is easy to provision or remove, the reliability of each instance is no longer the driving factor of availability. Instead, it is more cost effective to look at building redundancy that minimizes the risk that a system will fail based on equipment failures. It’s also more cost effective to minimize the recovery time (ideally without any interruption to the service) in case a failure occurs. In other words, instead of engineering each equipment in a system for robustness, one can achieve availability in the cloud by designing for system resilience.
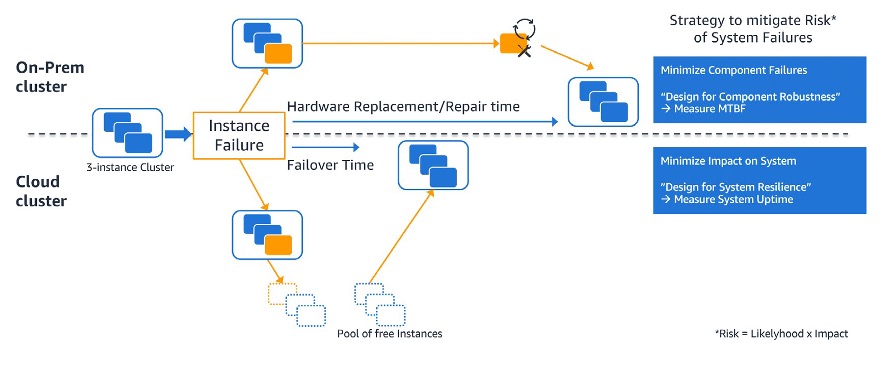
The following sketch highlights, in more detail, the differences when designing a system for a required availability in on-premises and cloud environments. Starting with a cluster that incurs a failure of a single instance, both configurations will suffer a failure or experience time with a reduced number of instances—until the failed instance can be replaced or repaired in the cluster. However, the difference is in the impact of that failure. In an on-premises situation, the recovery process can take significant time to reach the full cluster capacity again (from hours to days), whereas the switch to a new instance in the cloud typically takes only minutes. Hence, in the cloud case, the main driver for system availability is minimizing the failover time as a result of replacing failed parts of the system.
Figure 3: Equipment replacement in the cloud and on-premises
Reference architectures with different levels of resilience and availability
In this section, we dive deeper on standard architectures that allow businesses to leverage the cloud paradigm of resilience and achieve different levels of availability for a cloud-based computation cluster. Comparing these increasingly resilient architectures, IT professionals can choose the one that achieves the performance level for functional safety required for their system. To offer increasing resilience, these architectures use two separate strategies.
The first is achieving increasing geographical distribution of equipment in use to protect against localized failures. The second is increasing redundancy in terms of the total number of instances that are used in the system or held ready for fast replacement. For simplicity, we will consider a typical cluster consisting of a set of control planes and nodes that perform both storage and process capacity tasks. The same logic, however, also applies to clusters that rely on highly available services for storage, such as Amazon Simple Storage Service (Amazon S3) or Amazon Aurora which are AWS managed services that manage redundancy for the user. Explicitly, we will consider the following architectural setups that have different redundancies and the impact of each of the equipment failure modes in each of the below leveraging setups:
Figure 4: Deployment options for higher availability
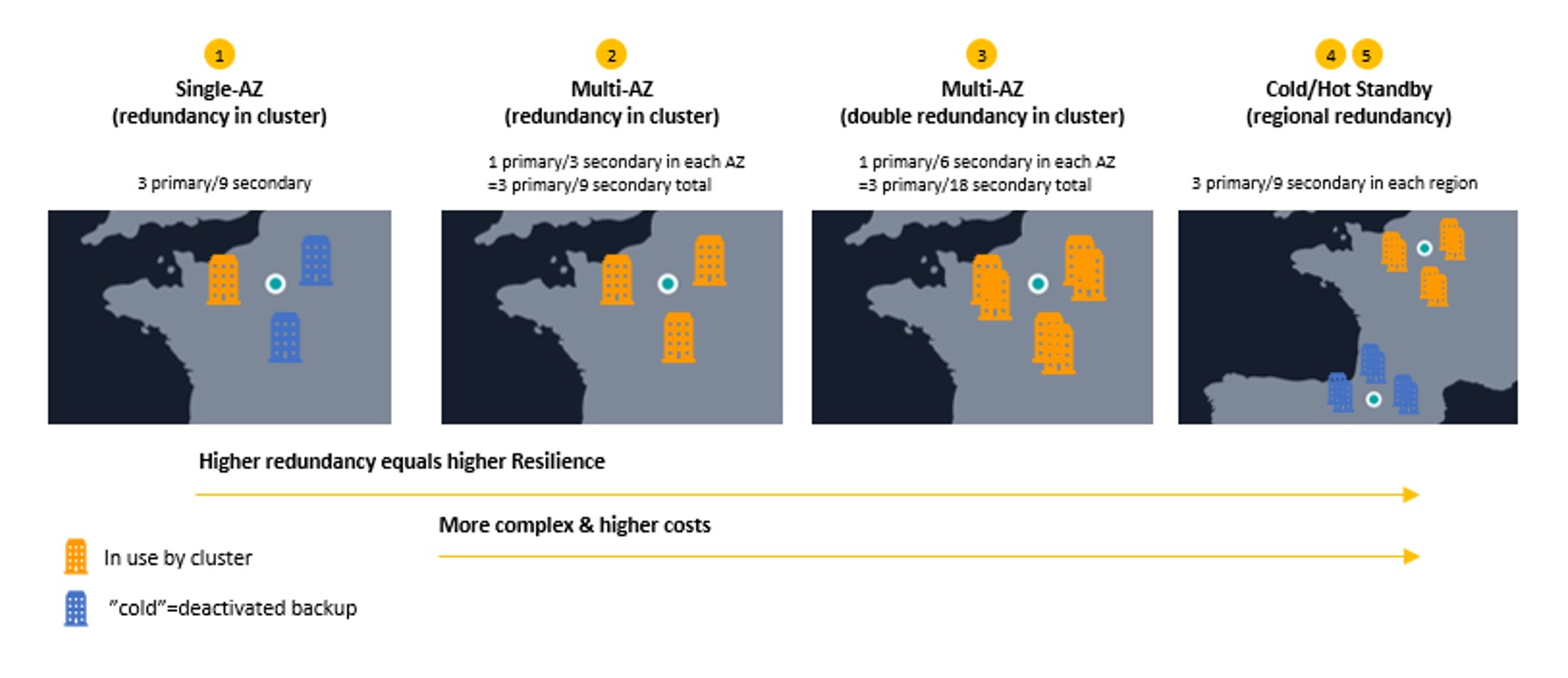
Option 1 is a situation similar to an on-premises setup with a single cluster running in a single data center within one Availability Zone. In this setup, a single machine failing means that the remaining cluster is still running on reduced capacity (for example, two out of three control planes). However, a failure of an entire data center means that the whole cluster could become unavailable. This option is similar to the typical on-premise setup of a cluster in a single data center.
In Option 2, a cluster of the same size as for option 1 has been distributed across three Availability Zones and therefore different data centers in a single AWS Region. In this setup, a failure of an entire Availability Zone means that the cluster is still running at reduced capacity based on the two other Availability Zones.
In Option 3, a cluster with additional nodes is distributed across the three Availability Zones such that even when an entire Availability Zone fails, the remaining Availability Zones offer sufficient capacity to perform the full system functionality. Due to the deployment in a single Region, only a disaster that affects all Availability Zones will mean that the cluster is no longer functional.
Options 4 and 5 can tolerate the failure of an entire Region by setting up a spare cluster in a secondary Region which can be started within minutes (Option 4). Or, it runs without load (Option 5), such that it acts as a fallback in case of a disaster—causing as little interruption to the services as possible.
How to determine the right architecture based on the required performance and cost
To give an intuitive idea of how the architectural choices relate to the availability of the overall system and its cost, let us establish an example calculation for each of those factors. First, we estimate the probabilities and impact of fundamental equipment failures (such as a single instance of a cluster, complete Availability Zone, and so on) on the overall availability for an example case.
Specifically, we consider an industry Red Hat OpenShift cluster consisting of three control planes and three tiers of three nodes (three nodes per routing, task execution, and storage each). Typically, these setups are designed so that they require only two of their three nodes for each tier for (at least limited) functioning. This way they can tolerate the loss of single nodes in each tier.
Availability
In a first step, we need to understand the probabilities and impact that different equipment failures will have on the overall system. To estimate those, we use the Service Level Agreements (SLAs) published by Amazon Elastic Compute Cloud (Amazon EC2) at the time of writing. (For details and up-to-date numbers, see https://aws.amazon.com/compute/sla/.)
Figure 5: Amazon EC2 Service Level Agreement for availability
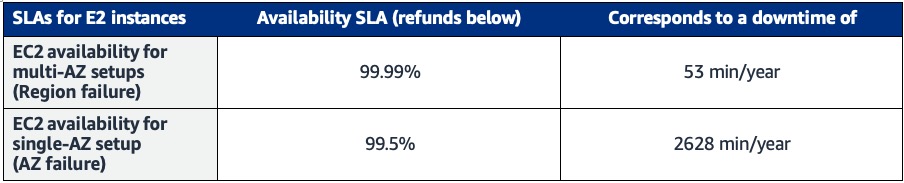
From this we can then understand the likelihood that an equipment failure mode will affect our cluster and its impact on the overall cluster availability. For each failure hazard, we indicate the availability impact (likelihood) in percentages, as well as the impact:

Temporary failures that can recover do so by using a mitigation mechanism that replenishes the functioning instances or failing over to a pre-provisioned Region.
Figure 6: Failure hazards and their impact on availability in the cloud
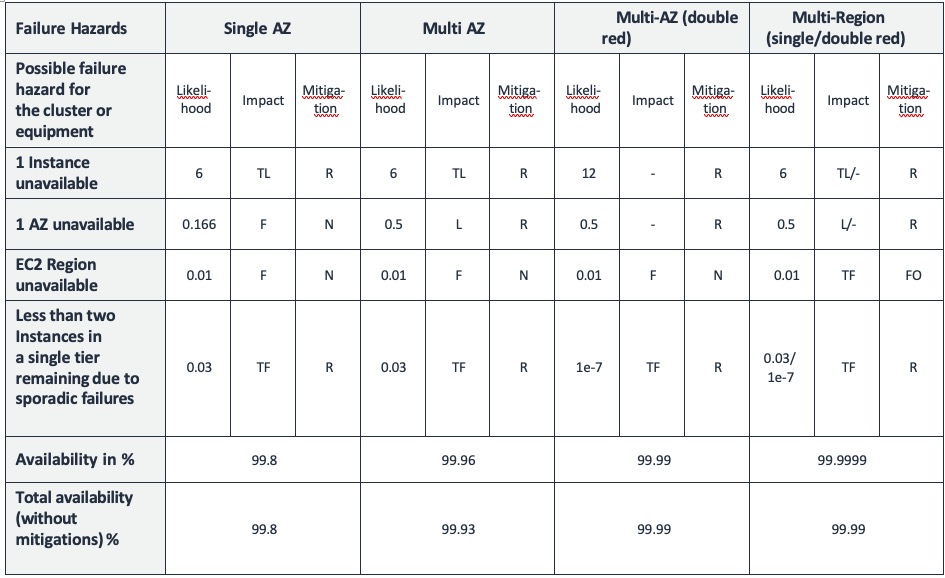
To visualize this, the resulting times of unavailability (failures, both temporary and permanent) are shown here.
Figure 7: System Downtime by Failure (1-System Availability)

Cost impact
As a second factor, we also investigate the cost of the different architectures. For this, we use a multi-availability zone (AZ) cluster as a cost reference (100%) and analyze the relative cost increase when using more or less resilient architectures in a simplified case.
Figure 8: System Availability by AWS SLA & Annual Cost by AWS Setup
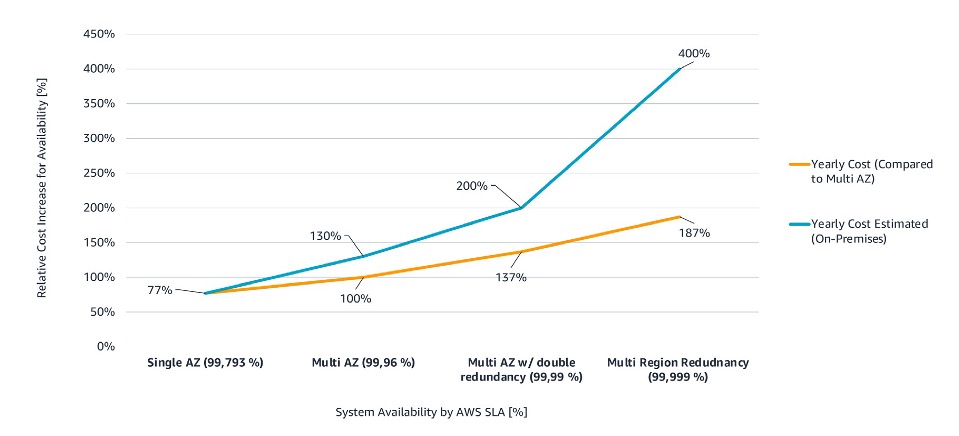
This comparison shows that reaching two, three, four or five ‘nines’ of availability (depending on the performance required for safety) means lowering the cost by 30% for two ‘nines’, or increasing the cost by 37% or 87% to reach four or five ‘nines’ of availability respectively.
Protection against failures due to updates and software errors
The need for IT equipment to undergo planned software or hardware maintenance, and the risks that come with deploying updates to the existing system, are not failures rooted in technical issues. Rather, they are failures to perform their function within the system. Flexibly adding or removing instances to functionally test a system should apply here as well to achieve protection. Most notably, by using a method of blue-green deployments one creates a second system with the new software coexisting alongside it. In this way, the old system can be used as a fallback whenever any issue with the new system is detected. This method enables businesses to test for the function of the new system under real-world conditions. It also enables them to run comparative benchmarking and rollbacks without interruption to business when an issue is found. This process can be performed, for instance, by AWS CodeDeploy, making it easier to add to an existing solution.
Consideration 3: Assuring quality, safety, and continuity
In addition to designing IT equipment as part of a larger system according to the required performance level for known failure modes, there can always be unknown or random failures. To ensure that these failure modes are covered, the relevant standards are set out in the guides and requirements for detecting and mitigating them. For instance, according to EN50129, such assessments must follow a “black-box” approach to detect such failure modes and impose a safe state on the system. This means that continuous monitoring of the interface (typically API or network gateways) for functioning is required and automations move to a safe system state based on the monitoring results. AWS offers additional capabilities to continuously monitor and assess cloud components and designated resilience mechanisms. As an additional precaution, it is useful to also use the AWS capabilities to continuously monitor the cloud components and assess if the designated resilience mechanisms are functioning.
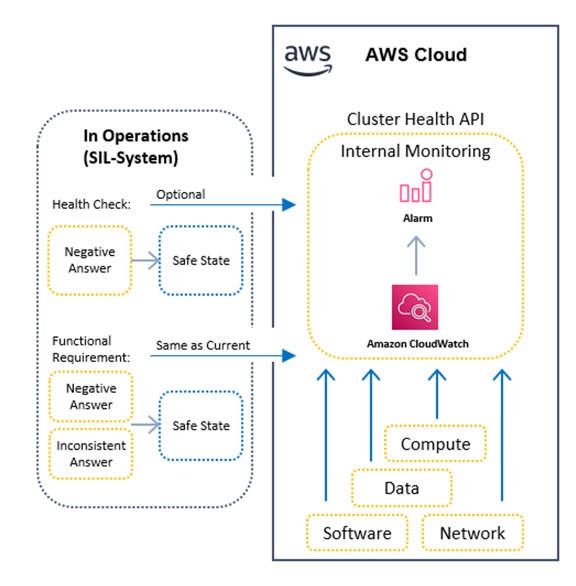
Detection of errors and system health monitoring
In the cloud, businesses can monitor workloads continuously from various perspectives to detect if the workload is acting as designed. For example, Amazon CloudWatch continuously monitors metrics, such as CPU and memory, that are indicative of the normal system functioning. Amazon GuardDuty detects anomalies in the network traffic (Amazon Virtual Private Cloud or Amazon VPC Flow logs) that could point to non-conformant traffic. Elastic Load Balancing provides logs about customer requests and resulting responses. All of these metrics can be used to provide flexible insights into workload health. In the context of integrating “pre-existing” equipment, this means that the external system can monitor for “plausible consistency” when interacting with the “pre-existing equipment” or cluster through their functional access points. Additionally, a cluster can actively provide its current health as an additional layer of safety. Hence the external system can achieve a safe state both when implausible responses are received and when internal metrics point to an existing or imminent failure of the cluster.
Figure 9: System Health Monitoring and Error Detection in the Cloud
Assuring resilience on the cloud: Chaos engineering
The availability of pre-existing equipment in the cloud relies largely on system resilience against failures of smaller components. This is specific to a system that recovers from an internal failure with no or little interruption of its function. Hence, assuring the functioning of this resilience is a continuous process that spans the entire lifecycle of the equipment. During coding and equipment creation, businesses must adopt a high-quality coding style. Standard testing covering the software development stack is also essential and building on an industry- grade operation system also helps avoid errors in the software components.
After development and commissioning, and in operation, resilience of the system as a critical function can be continuously assured with a somewhat counterintuitive approach. In that approach, called “chaos engineering,” an external process occasionally and randomly deletes resources, such as instances or larger components of the system, and monitors the recovery process. For example, the external process might cut off traffic to one or a few cluster instances. It may also monitor the increase and remaining capacity of the remaining cluster while checking how the seemingly faulty instances are removed from the cluster and replaced.
Even though one would expect that this method has a deteriorating effect on system performance, it instead has a double benefit. First, it ensures that workloads developed for this environment are unconditionally resilient and cannot have any single points of failure. Second, this approach provides continuous testing if the resiliency mechanisms put in place are operating as designed. Ultimately, subjecting the system to small “chaos engineering” disturbances that are designed to not result in a system failure—allows businesses to verify resilience and intervene before a real issue or failure can lead to one that impacts cluster or equipment performance.
Business continuity: Backups
So far, the discussion of equipment and system resilience has been centered around recovery from item failures without an impact on the system function. While this is the prime necessity for achieving an operational system, the cloud also facilitates the recovery from more severe and broader failures, such as a failure of an entire Availability Zone or a large-scale crash that requires a complete restart of the entire system or backup restoration efforts. For example, taking regular snapshots of the existing system and storing them in Amazon S3. These backups can be replicated to multiple Regions around the globe with minimal overhead, allowing businesses to restore to the flexible times of the past even in the case of large-scale events.
Outlook
This document identifies the most important concepts that allow equipment to become part of a system, including the need to achieve functional safety according to standard norms in the railway space, such as EN50129. With a vast set of norms existing in different areas of the industry, adaptations will be required for the respective use case. If you find yourself in this situation or need support, please contact your AWS Account representative or contact us here.