AWS for Industries
Digitizing paper intake forms to deliver accurate, structured patient data
Even in this digital age, when healthcare systems are building out digital front doors, many providers require patients to fill out paper forms or questionnaires in writing at the time of their appointment. Additionally, patients bring pre-filled paper forms containing text from another provider which require processing. Back-office staff are expected to read the forms and manually transfer appropriate data into the patient chart. This approach tends to be time consuming and prone to error. Important data points can be missed and can result in negative impacts to quality measurement and safety requirements.
In this post, we describe an automated Health Insurance Portability and Accountability Act (HIPAA) eligible solution for processing patient intake forms, transforming them into structured patient data and presenting the data for review by office staff. Per HIPAA eligibility requirements, all patient data processed by the solution is encrypted both in transit and at rest. Once approved, the form data, in its encrypted structured format, can easily be ingested by downstream applications, like an Electronic Health Record (EHR) system, so that this valuable patient data is captured accurately and stored with the patient’s record.
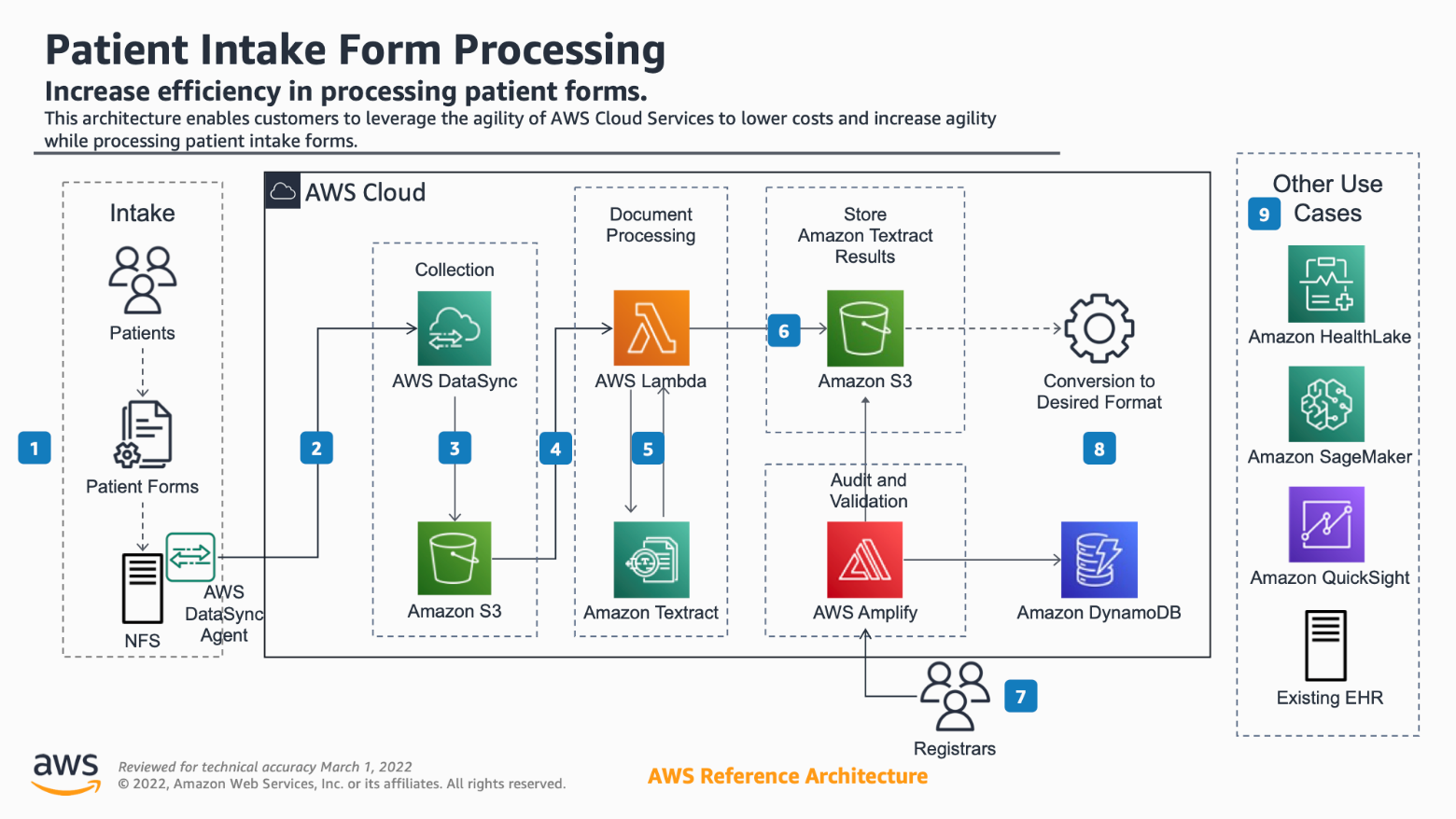
Patient Intake Form Processing Architecture Walkthrough
- Each patient intake form is scanned at the provider’s office.
- The resulting PDF document is stored locally on a Network File System (NFS). AWS DataSync (DataSync) is an online data transfer service used to automate the movement of data securely between on-premise and AWS storage services.
- Using a DataSync agent, the NFS communicates with DataSync in the AWS Cloud.
- This communication delivers the files to an Amazon Simple Storage Service (Amazon S3) bucket for processing.
- When each patient’s intake PDF arrives in the Amazon S3 bucket, an AWS Lambda (Lambda) function is automatically triggered via an event notification.
- The triggered Lambda function then contacts Amazon Textract.
- Amazon Textract, a machine learning service, is used to extract text, handwriting, and data from scanned documents using object character recognition.
- After Amazon Textract has finished processing the document, it creates a JSON formatted file.
- This file contains the form’s data, in key value pairs, in a second Amazon S3 bucket.
- Once the JSON formatted output file has been delivered to the Amazon S3, it is loaded into an application that uses AWS Amplify (Amplify).
- Amplify is a service that allows you to build scalable mobile and web applications. Inside the Amplify application, a web page is made available for provider staff to review the structured patient data in a simple HTML, editable form. The original document is displayed alongside this form. This makes it easy for the reviewers to identify and correct any discrepancies between the handwritten intake form and the structured patient data output from Amazon Textract.
- Once the extracted patient data has been reviewed for accuracy and any changes have been saved, it is made available for downstream processing.
- Amazon DynamoDB database can save the structured forms. Amazon DynamoDB is a NoSQL database, which is ideal for storing key value pair data for later use.
- Consolidated Clinical Document Architecture (CCDA) can be created from the structured Amazon Textract results if you have an existing EHR solution.
- Some downstream use cases offered by the portfolio of AWS analytics services:
- Amazon SageMaker makes it easy for healthcare organizations to build, train and deploy ML models, using structured patient data. Customers can use Amazon SageMaker to identify patients at risk for adverse health events, predict patient utilization, population health risk scoring, as well as, many other AI/ML use cases.
- Amazon QuickSight, a Business Intelligence (BI) solution, can be used to quickly visualize patient data and gain valuable insights.
- Amazon HealthLake can be used to extract meaning from the form data using natural language processing. Amazon HealthLake uses ML models to automatically understand and extract meaning by analyzing input data and recognizing medical information such as medications, procedures, and diagnoses. It can even map this information to medical ontologies including ICD-10, RxNorm, and SNOMED for you at the same time, saving many hours of manual work. Amazon HealthLake also natively supports the Fast Healthcare Interoperability Resources (FHIR) format. Amazon HealthLake Partners can help you get started quickly with a range of Amazon HealthLake applications and services. If your data is not yet in the FHIR standard, you can work with AWS Partners who have built validated Amazon HealthLake connectors to transform existing healthcare data in to the FHIR format and move it in to Amazon HealthLake.
Using these digital steps, the original information provided by the patient on the handwritten form has been digitally processed for ingestion into the patient record within an EHR in an accurate and timely manner. The overall result is a more efficient intake process for the practice. For the staff working at the provider’s office, poor handwriting can be difficult to understand and patients may accidentally skip questions, which can result in a loss of important information. The office staff at the provider are no longer burdened with the painstaking tasks of having to read, understand poor handwriting and enter every answer into the electronic system by hand. The solution automatically consumes the form data and presents it, alongside the original patient generated health data, to a healthcare provider (HCP) who can correct and fill in any gaps as needed. This can reduce what psychology calls “time pressure” which is a major contributor to HCP burnout.
Patients benefit from a more efficient intake process, which can lead to less time spent refilling out forms and lower wait times. Digitalization enhances the original patient’s record with important data, which can be leveraged by many other innovative AWS services with the same goal of improving the patient experience and delivering better care. Additionally, hand written intake documents might be added, as attachments, to the electronic record in a section which is not typically viewed by the physician. Automatically populating the relevant section of the electronic record provides the physician with more complete and accurate information about the patient that contributes to the best care possible.
To learn more about how AWS and AWS Partner Solutions can be used for health data interoperability visit, https://aws.amazon.com/health/healthcare/solutions/.
Further Reading
- Extract entities from insurance documents using Amazon Comprehend named entity recognition
- Postprocessing with Amazon Textract: Multi-page table handling
- Intelligently split multi-form document packages with Amazon Textract and Amazon Comprehend
- Augment search with metadata by chaining Amazon Textract, Amazon Comprehend, and Amazon Kendra
- Get started with the Redox Amazon HealthLake Connector
- Build patient outcome prediction applications using Amazon HealthLake and Amazon SageMaker