AWS for Industries
Going the last mile: An innovative instant delivery accelerator from AWS

Introduction
In the supply chain and logistic industries, the last step of the delivery process is called “the last mile.” This is usually handled by courier companies and can be either “instantaneous” (think of food deliveries, which need to be delivered as soon as they’re ready) or “same-day” or “multiple-day” deliveries (think of products bought on an ecommerce website).
In most cases, the last mile is the most complex and expensive part of a delivery, requiring couriers to solve multiple complex business, logistic, and technical issues all at once, such as
- monitoring driver availability and location;
- optimizing driver allocation based on their route and space availability on their vehicle;
- minimizing the distance of the driver’s journey to minimize costs;
- minimizing customer waiting time; and
- complying with other rules related to specific business rules.
With the recent global COVID-19 pandemic, consumer behavior has drastically changed, creating a surge in demand for delivery services across the board, including for ecommerce products, food, groceries, and more. In the post-COVID-19 pandemic world, analysts estimate this trend will continue (although, there is some reduction in the demand post pandemic).
To support the frequent asks by customers planning to launch delivery operations and last mile logistics services, AWS ASEAN (Association of Southeast Asian Nations region) prototyping team built and made available an open-source asset—which easily allows companies to build their own last-mile capability while addressing both instant and same-day delivery requirements and challenges. It makes use of IoT, serverless, machine learning, and geospatial technologies. It follows an event-driven architecture.
This is the first part of our blog series, where we describe this new asset in detail, how it works, and how to integrate it into an existing environment, with a focus on instant delivery. In the second part, we will cover same-day delivery.
Functional architecture
At a high level, the AWS Instant Delivery feature consists of two main parts, as illustrated in the functional architecture diagram below (Fig. 1).
- Track & Search. This module is capable of tracking tens of thousands of drivers in near real-time and making it possible to search their current location. It provides both a simple location search (drivers within a specific circular radius or rectangular shape) and complex search (drivers within a complex polygon/isochrone shape). The two key design considerations are latency (how soon a driver’s location is discovered) and throughput (how many drivers the system can track simultaneously).
- Order Dispatching. This module is used to efficiently assign orders to drivers. It has two submodules: “Instant Delivery” (covered in this blog) and “Same-Day Delivery” (covered in a future post). Any delivery business is usually a high Opex business, with the main expense being the management of the delivery fleet. Therefore, it is critical to have a well-designed system for matching orders with drivers, as it directly impacts business profitability and sustainability. Note that the accelerator uses a set of predefined optimization techniques, but these can be easily modified based on the company’s proprietary data and specific business requirements.

Figure 1. Functional architecture
High-level technical architecture

Figure 2. Technical architecture (high level/simplified)
The architecture displayed in figure 2 shows an event-driven, serverless system. It leverages Amazon EventBridge as an event bus. EventBridge makes it easier to build event-driven applications at scale using events generated from your applications, integrated software-as-a-service applications, and AWS services. This component is at the heart of the system: all orders and status updates pass through it. It can also forward messages to specific endpoints, based on custom business logic rules.
The two core modules of the system are
- Track & Search; and
- Order Dispatching
Track & Search service
This service helps to manage all tasks where geolocation plays a central part:
- Driver GPS live-tracker
- Location-based search
- Geofencing
It leverages the AWS IoT Core service, which acts as a high-throughput message broker to securely transmit messages to and from the Driver App and Customer App. It supports MQTT protocol, which requires comparatively fewer data compared with HTTP to transmit the same amount of information. For our use case, the Driver App continuously sends location data to AWS IoT Core, which in turn forwards these data packets to Amazon Kinesis, a service for collecting, processing, and analyzing real-time streaming data. From there, it is indexed by the Track & Search service. Data is ingested using Basic Ingest, which can securely send device data, following AWS IoT rules to the target service, without incurring messaging costs.
The Track & Search service consists of a combination of Amazon MemoryDB for Redis—a Redis-compatible, durable, in-memory database service for ultrafast performance—and Amazon OpenSearch Service, a service that makes it simple to deploy, operate, and scale OpenSearch clusters in AWS. The former supports simple queries (“all drivers within a radius or rectangle shape”); the latter supports complex queries (“all drivers within a polygon”).
The Driver App sends and receives status updates to and from Amazon Eventbridge through AWS IoT Core. On the other end, an instance of Amazon API Gateway, which helps create, maintain, and secure APIs at any scale, provides an API to query locations from Amazon MemoryDB for Redis and OpenSearch clusters of the Track & Search service.
Geofencing
When an order is assigned to a driver, the Order Manager (a part of Order Dispatching Service, details follow later) publishes the message to EventBridge. A geofencing submodule of Track & Search subscribes to these messages and starts tracking drivers assigned to those orders. Geofencing logic is applied using MemoryDB for Redis, and whenever the driver reaches a certain radius within a pickup or delivery point, a notification is generated by the Geofencing submodule and published onto EventBridge. From there, it can be shared with customers and partners such as restaurants and other businesses.

Figure 3. Geofencing architecture
Additional considerations
Continuously tracking drivers can rapidly drain mobile batteries. However, not tracking drivers often enough can make it difficult to know exactly what route they took or where they are at a particular moment. It might also lead to assignment errors—for example, when a driver is close to a certain pickup point but doesn’t get orders from that pickup point due to a location not being updated.
The system uses two approaches to minimize battery consumption without losing track of drivers:
- Different driver-tracking frequencies are used with active vs. passive modes. These modes turn on different frequencies for capturing GPS locations and submitting data to the cloud.
- Batch submission: while GPS location capture is done at a higher frequency, transmission to the cloud is done at a lower frequency.
These approaches are configurable. When the app is started on a device, it fetches the latest configurations. For devices already running the app, they get configuration changes in near real time.
The diagram below illustrates this flow. This system can also be used to push any other configurations to the app (e.g., for A/B testing).

Figure 4. Global mobile app config
Order Manager: Rules engine and order distribution
The Order Manager module helps to centralize and dispatch orders to the fleet of drivers while factoring in a wide range of constraints, such as driver and delivery locations, availability, and business rules. The module consists of two core elements:
- Order Orchestrator and Provider Rules Engine (which enforces rules within demographic areas, explained below)
- Delivery Provider
Order Orchestrator and Provider Rules Engine
If a company launches a business involving last-mile delivery, it has the option of either building its own delivery fleet or using a third-party delivery fleet (or multiple fleets) by accessing their APIs. The system allows orders to be distributed between both internal and external fleets and allows different distribution proportions to be set for different demographic areas. For example, in Area A1, the customer might decide to use only a single provider—External Provider Pr1—whereas in Area A2 they might decide to split orders between External Provider Pr2 and External Provider Pr3. This distribution is enforced with the help of the Provider Rules Engine.
The prototype supports two technical implementations for communication, Webhook provider and Polling provider, to account for different implementations available by external providers.
Provider Rules Engine
The Provider Rules Engine implementation is fairly simple for most production use cases, yet the system has been designed with extensibility and configurability in mind. While transitioning into production, customers need to implement their own business rules to decide which provider should be selected for a given area. The codebase can be extended to accommodate additional business rules, define new priorities, and customize the system by adding new operators.

Figure 5. Example of multiple providers (internal and external providers) being selected by the Provider Rules Engine
Demographic areas
Demographic areas of a city or town are regions that have their own delivery provider rules. For example, for an area designated A1, only internal delivery fleets can be selected, while for another area designated A2, orders could be divided between two external delivery providers.
A list of demographic areas is stored in Amazon DynamoDB, a fully managed, serverless, key-value NoSQL database, and configurations for the Provider Rules Engine are stored in the same table lined to the respective demographic areas. Whenever a place of origin is registered, such as a restaurant or grocery store, a tag is applied to it, indicating which demographic area it belongs to.

Figure 6. Different rules for different areas (e.g., different external delivery providers for different areas)
Delivery Provider
Let’s take a closer look at the Instant Delivery Provider.

Figure 7. Instant Delivery Provider
This module manages a sequence of three different processes:
- The first process receives orders through the Order Fulfillment Request Handler and assigns a status to each one.
- Next, the orders go to the Geo Clustering Manager, where orders are grouped to form clusters based on their proximity to one another.
- Finally, the Dispatch Orchestrator triggers the Instant Delivery Dispatch Engine to analyze these clusters, load and solve the constraints defined by the business, and assign the orders to the drivers accordingly.
Geo clustering
By default, the Instant Delivery Provider exposes the same interface as all other providers, and the Order Orchestrator service invokes a provider using an HTTP request through an Amazon API Gateway endpoint. The provider uses Amazon Kinesis to batch incoming orders before processing them. This grouping mechanism allows the Instant Delivery Provider to process orders in bulk. The group size can be configured based on the business need. Note that a big group size can result in bigger clusters, which could lead to longer runtimes for the Dispatch Engine to generate optimal solutions.
Before processing the orders from a group, Geo Clustering Manager performs a preoptimization procedure. This component, implemented using AWS Step Functions, which are visual workflows for distributed applications, will cluster orders that have pickup points close to one another, which will prevent the downstream Dispatch Engine from performing time-consuming, complex lookups to find available drivers and, in general, will make sure that the dispatching is optimal and fast.
The Dispatch Orchestrator is also implemented using AWS Step Functions. It is executed for every geo cluster generated by the Geo Clustering Manager. Dispatch Orchestrator invokes the Dispatch Engine, which optimizes assignments (and minimizes costs) for every given cluster. When drivers are selected for orders, the Dispatch Orchestrator notifies them by messages through AWS IoT Core. Drivers can accept or reject assignments. If a driver rejects an order, it is added back to the batch (with Kinesis). Order status is maintained in the Order Status Store.

Figure 8. Geo clustering example (source: GraphHopper)
More on constraint solving by the Dispatch Engine
The Dispatch Engine is a custom application used to address the linear optimization problems associated with instant and same-day delivery domains. The prototype uses OptaPlanner, an open-source, artificial intelligence (AI)–based linear optimization solver, to model and implement both domains. For a technical deep dive, we highly recommend these blogs and documentation.
As far as constraint solving, one can define different levels of constraints—such as hard, medium, or soft—and a score function to be maximized (or a cost function to be minimized). This OptaPlanner documentation covers all the information needed to successfully model a problem domain. There are many ways drivers can be allocated to an order; the software needs to compute a score for each allocation and provide assignments that have the highest score. OptaPlanner is a smart way to reduce the amount of computation required to arrive at an optimal result. The best constraint-solving approaches verify that the system can deal with competing priorities, such as distributing orders equally among drivers versus prioritizing drivers with higher ratings.
Default optimization recommendations in the instant delivery accelerator:
- Distribute orders among the available drivers as much as possible. If there are free drivers, assign orders to them instead of assigning multiple orders to one driver.
- Select drivers that are closer to a pickup point—such as a restaurant—rather than ones that are farther away. (Note that customers might choose different constraint/scoring functions that will lead to different outcomes. For example, you could prioritize drivers with higher ratings or batch orders with nearby pickup and delivery locations.)
A quick note on geospatial technologies in use: The role of GraphHopper
This system uses the open-source version of GraphHopper for its routing engine. The Track & Search service supports simple geospatial queries with Amazon MemoryDB for Redis and complex polygon geospatial queries with Amazon OpenSearch Service. You can use GraphHopper to get isochrones around a pickup point and use the result to query drivers inside the polygon by using Amazon OpenSearch. You can cache them and use them later for geospatial queries.

Figure 9. Isochrone: How far can you get within 10 or 20 minutes of driving? (source: GraphHopper)
Simulator
In order to test the prototype at scale a simulator is included. The prototype is designed to be an event-driven backend system, so the simulator generates relevant events (driver’s GPS updates, orders, order assignments, accept/reject messages).
The simulator helps determine whether the system is behaving as desired, such as properly distributing orders between internal and external providers, and whether the system can handle a specified load.
The simulator helps users to mimic the behavior of a variety of actors, including drivers, origins (restaurants, warehouses), and destinations (customers). These entities are simulated with the help of containers in Amazon Elastic Container Service (Amazon ECS), which makes it simple for organizations to deploy, manage, and scale containerized applications. Each container can simulate multiple counts of each actor—up to 10 or more per container, depending on container sizing.
- The driver container simulates driver behavior (movement, accept/reject, pickup/deliver). The container will receive messages from the cloud through a dedicated IoT topic (each driver has their own personal topic). When the message is received, the driver can accept or reject the assignment and eventually simulate the route and send order status updates to another IoT topic to acknowledge the changes to the specific delivery (e.g., accepted, pickup, delivering, delivered). The driver also sends its GPS coordinates periodically to a dedicated IoT topic that triggers the ingestion and indexing of the data performed by the Track & Search module. Recall the Track & Search module is also responsible for sending geofencing events when the driver approaches the pickup or drop-off point.
- The origin container is a simple entity that receives incoming orders from its dedicated IoT topic and decides whether to accept or reject the order. From the Web UI it’s possible to configure the rejection rate, which will determine the percentage of orders that will get rejected automatically.
- The destination container provides the logic to pick up random origins and submit orders into the system from the Web UI. This container also has an option to replay existing events based on an input file. This helps to simulate specific load test scenarios by using the data distribution of a normal day (low, medium, or high peak) to see how the system reacts. The events are played in the order that they appear, based on the time interval of the incoming orders.
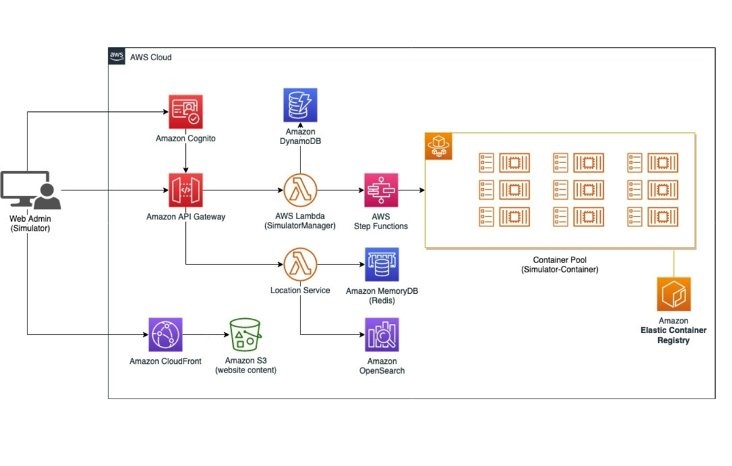
Figure 11. Simplified simulator architecture

Figure 12. Simulator UI

Figure 13. Simulator dashboard
Load-handling capacity
The prototype has been tested to track 50,000 drivers concurrently and handle 5,000 orders every 5 minutes, amounting to hundreds of thousands of orders over a day. The overall system is horizontally scalable, allowing for volumes beyond these numbers.
Scaling of individual services:
- Serverless components like
- AWS IoT Core;
- AWS Lambda, which makes it possible to run code without thinking about servers or clusters;
- Amazon EventBridge;
- AWS Step Functions, which offers visual workflows for distributed applications; and
- Amazon Kinesis Data Streams, a serverless streaming data service that makes it easy to capture, process, and store data streams at any scale,
will scale to handle demand automatically (make sure you don’t run into any AWS account limits).
- You will need to plan in advance to scale Amazon MemoryDB for Redis, Amazon OpenSearch, and Amazon ECS. These services are both horizontally and vertically scalable.
Integration with customer front-end and backend
Global Event Hub, implemented with Amazon Event Bridge, makes it simple to integrate with external systems that can be developed by the customer or third parties. This will require you to publish events to the Global Event Hub and listen to events in Global Event Hub for responses and updates. This event-driven architecture makes loose coupling possible.
As you would recall, the Order Dispatching Service and the Track & Search service listen to the Global Event Hub and also publish events back to the Global Event Hub.
For example:
- The Order Dispatching Service publishes order assignment details to Global Event Hub, which are then conveyed to interested parties (e.g., drivers) and functional components (e.g., geofencing).
- The geofencing component of the Track & Search service publishes geofencing notifications to Global EventHub.
The Order Dispatching Service also directly calls the Track & Search service to get data synchronously, such as for drivers within a radius or polygon. This is done for low-latency requirements.
Public endpoints for drivers and customer front-end apps:
- The Driver App interacts with the cloud through AWS IoT Core using the MQTT protocol.
- The Customer App interacts with the cloud through AWS API Gateway using the HTTP protocol.
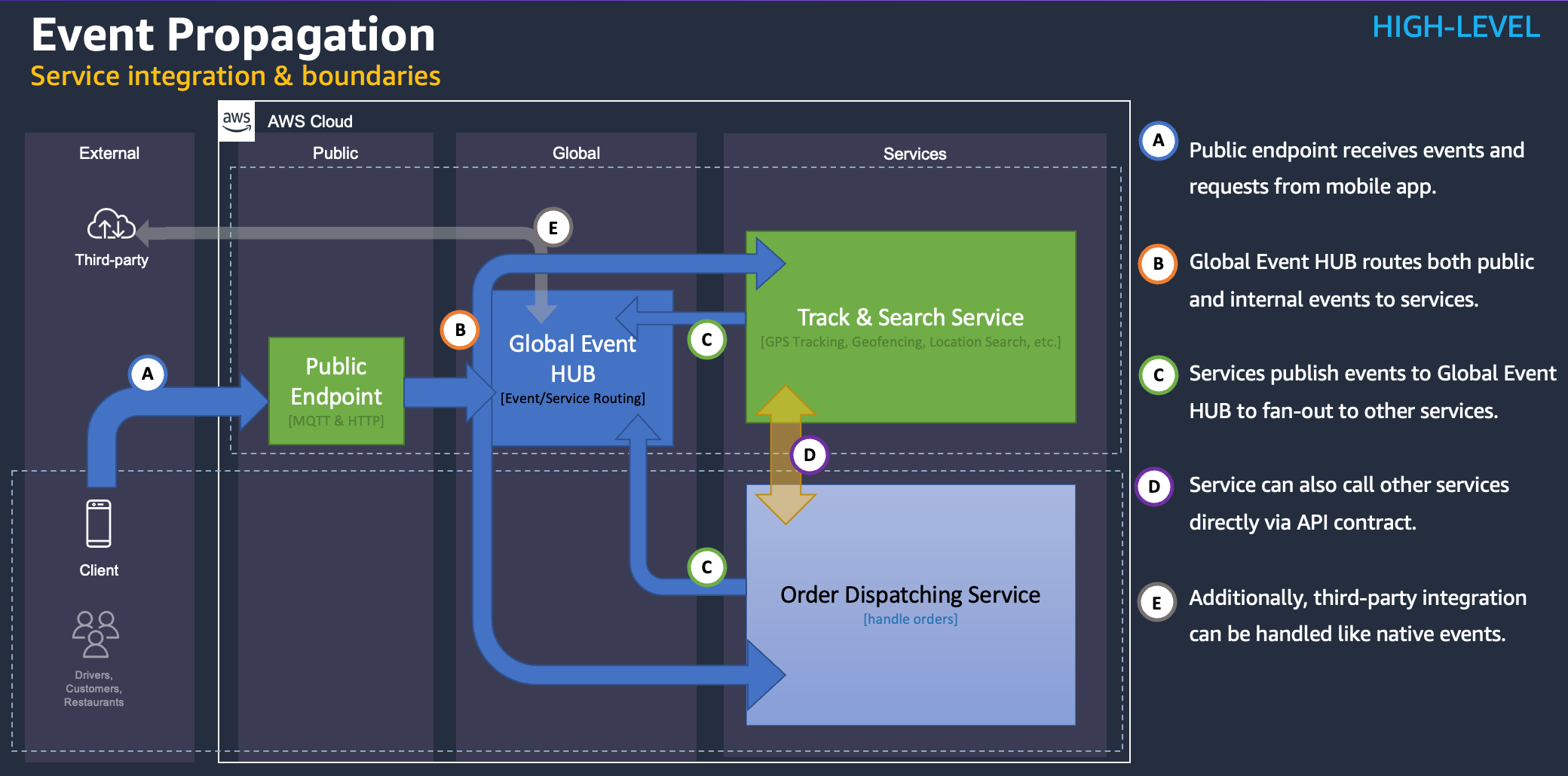
Figure 14. Integration through event propagation
Conclusion
The Last Mile Delivery Accelerator for Instant Delivery saves customers unnecessary heavy lifting and makes it possible for them to focus on data-driven innovation. Most components of the system are serverless; others are managed, which makes maintenance and operations easier. Most components are automatically scaled, making the cost of operations relatively low. The system facilitates innovation through configurable rules engines and optimization engines. The system also accounts for the reality that a lot of delivery businesses might be using third-party fleets.
Additionally, the system shows how to use various AWS services in effective manner to solve the challenges of Last Mile Delivery. These services include AWS IoT Core, Amazon Kinesis, AWS Lambda, AWS Step Functions, Amazon API Gateway, Amazon MemoryDB for Redis, Amazon OpenSearch Service, Amazon ECS, and more.
In our next blog post, we will take a detailed look at the AWS-based Last Mile Delivery Accelerator for Same-Day Delivery.
Disclaimer
The software is shared under Amazon Software License (ASL), and AWS does not bear any liability. The system design has followed AWS Well-Architected principles for performance, reliability, cost efficiency, and sustainability. The customers are advised to do their due diligence and testing before deploying it in production.