AWS for Industries
How Greenko uses AWS IoT and serverless for wind monitoring
India is going through a revolution in renewable energy (RE). During fiscal years 2016–2020, the Indian RE generation space saw a compound annual growth rate of 17.33 percent. This was fueled by dedicated support from the government in the form of RE-focused policies such as the Green Energy Corridor Project and increased investment in the sector. Since 2014 more than US$42 billion has been invested in India’s RE market. The Indian government is aiming to reach a target of total installed capacity of 227 gigawatts (GW) by 2022 and 523 GW by 2030. This will include almost 73 GW from hydro. Due to these factors, India is ranked third globally in investments in RE.
Driving the change to renewable energy
Greenko Group (Greenko) is helping drive this change to RE in India. Greenko is a leading energy solution provider in the changing energy landscape of India. With a total installed capacity of 7.5 GW, which includes wind (2000+ wind turbines), solar (5+ million solar panels) and hydro (25 sites), Greenko has electrified over 6.3 million households and has removed an equivalent of over 17 million tons of carbon dioxide from the atmosphere.
Greenko’s corporate strategy is focused on powering India with decarbonized, digitized, and decentralized energy assets. Toward this end, Greenko has moved from being a pure-play RE producer to a long-duration energy storage (LDES) provider. LDES providers address system challenges such as balancing electricity supply and demand and changing transmission flow patterns with corresponding decreases in system stability. They can accomplish this through a balanced combination of intelligent energy platforms and pumped storage systems, like Greenko’s Integrated Renewable Energy Storage Projects (IRESPs). IRESPs will harness the power of solar and wind resources with digitally connected storage infrastructure to provide scheduled and flexible around-the-clock power to the grid. Greenko has license to build and operate multiple IRESPs across five states in India with a daily storage capacity of 40 gigawatt-hours (GWh).
Addressing challenges in its renewable energy monitoring architecture
Greenko’s IT infrastructure was completely on premises, with data centers located in the city of Hyderabad. The company observed the following challenges with its RE asset monitoring architecture:
- It needed high availability, scalability, security, and storage capacity. As Greenko increases its fleet size across the country, the on-demand availability of IT infrastructure was a challenge. A lot of investment goes in the form on CAPEX and OPEX for the expansion and maintenance of the on-premises data centers. In particular, the cost of storage in historians is increasing annually as the fleet size increases.
- It was collecting telemetry data every 30 seconds per RE asset (e.g., wind turbines). However, the company faced a demand to increase the frequency to every 10 seconds. This was needed to run advanced analytics use cases like generation forecasting, predictive maintenance, minute level trading, and others. The 10-second data would lead to triple the volume of data being ingested, putting more stress on the on-premises infrastructure.
- There was no consolidated view of the data because the RE data was residing in two kinds of silos—the local MySQL databases at asset sites and the historian database through Open Platform Communications (OPC) at a central location. This led to reduced response times when there was a sudden demand for data, such as to process a performance curve comparison report of two assets in two different geographies for two different seasons. The on-premises system took some time to respond because it needed to collate the data from the various silos.
- Mix of third-party and internally developed visualization tools lack flexibility and increase O&M costs: For real-time data visualization Greenko, is using third-party IDEs and internally developed web applications. Today Greenko are looking at more diversity and flexibility in its dashboarding capabilities, making use of technologies such as AI/ML and advanced analytics, without incurring any additional costs.
Launching a minimum viable product (MVP) program using AWS
In December 2020, the India account team of Amazon Web Services (AWS) contacted Greenko to introduce the team’s work in the RE space, including the work outlined in Real-time operational monitoring of renewable energy assets with AWS IoT. The author of this blogpost engaged Greenko representatives, including the Greenko leadership team: Mr. Tirumala Raju Mandapati, head of information and communication technology (ICT), and Mr. Sateesh Konduru, general manager of ICT.
AWS presented a dive deep into the concepts of using the Internet of Things (IoT) on AWS and how AWS IoT services can be a vehicle to deliver part of the Greenko corporate strategy—the digitization and decentralization of renewable assets. AWS recommended a pilot program with a quantifiable minimum viable product (MVP) that resolves an important use case and highlights the capabilities that AWS IoT has to offer.
Greenko accepted the recommendation, and in April 2021 it delivered a pilot scope and an MVP was finalized. The MVP was to be performed on one of the largest Greenko wind farms in the city of Poovani in the state of Tamil Nadu. Greenko named the MVP Greenko Wind Farm Health 1.0. The scope of the MVP involved four pillars, as shown in Figure 1.

Figure 1: Scope of the Greenko MVP
MVP achievements by pillar
- Data ingestion
- Securely connected 100 wind turbines to the cloud, with each turbine generating 93 tags every 10 seconds
- Achieved ingestion rate of 56,000 tags per minute
- Data lake hydration
- Built a highly available and scalable IoT data lake
- Implemented a single version of truth for all downstream applications
- Enacted data curation and calculation with 15-minute aggregates
- Data visualization
- Set up a live operational dashboard for 100 turbines
- Identified 58 tags (out of 93 total) as hot tags
- Achieved dashboard ingestion rate of 35,000 tags per minute
- Achieved dashboard refresh rate of once per minute
- Data analytics
- Delivers live metrics of AWS services in use through Amazon CloudWatch—a monitoring and observability service
The four pillars are supported by two very strong foundation stones:
- Complete Security: AWS services provide tools and mechanisms to facilitate security from end to end—for example, private/public certificates, encryption of data in transit and at rest, and fine-grained access control through AWS Identity and Access Management (AWS IAM)—which lets companies apply fine-grained permissions to AWS services and resources.
- AWS Partners: The AWS Partner Network (APN) is a global community that uses programs, expertise, and resources to build, market, and sell customer offerings. For this initiative, Greenko selected India AWS consulting partner, Locuz Enterprise Solutions, to develop and deliver the MVP. Locuz has more than two decades of experience and 350+ deployments in High-Performance Computing (HPC).
MVP delivery timeline
Working with the AWS team and Locuz, Greenko successfully delivered the MVP with bias for action in just under 10 months. The timeline and milestones of the delivery are shown in Figure 2 below.

Figure 2: The Greenko MVP delivery timeline
- December 2020: The Greenko leadership team first interacts with the AWS team, focusing on the art of the possible with AWS IoT. The AWS team recommends an MVP demonstrating the capabilities of AWS IoT for renewable assets.
- April 2021: Greenko approves and identifies an MVP. The MVP reference architecture is created.
- May 2021: Greenko initiates the build with AWS Partner Locuz.
- July 2021: The MVP goes live.
- August 2021: Greenko adopts the MVP as production ready for the Poovani wind farm (100 wind turbines).
- October 2021: Greenko moves to production, deciding to onboard 27 wind farms (700+ wind turbines) to the AWS IoT–based wind farm health approach.
MVP reference architecture
The following is the AWS reference architecture that was created for the Greenko MVP. Although the MVP was done on 100 wind turbines, the architecture is scalable and robust to support multiple sites with thousands of assets.
It’s important to note that the solution is completely serverless with minimal to no infrastructure to manage for the Greenko team.
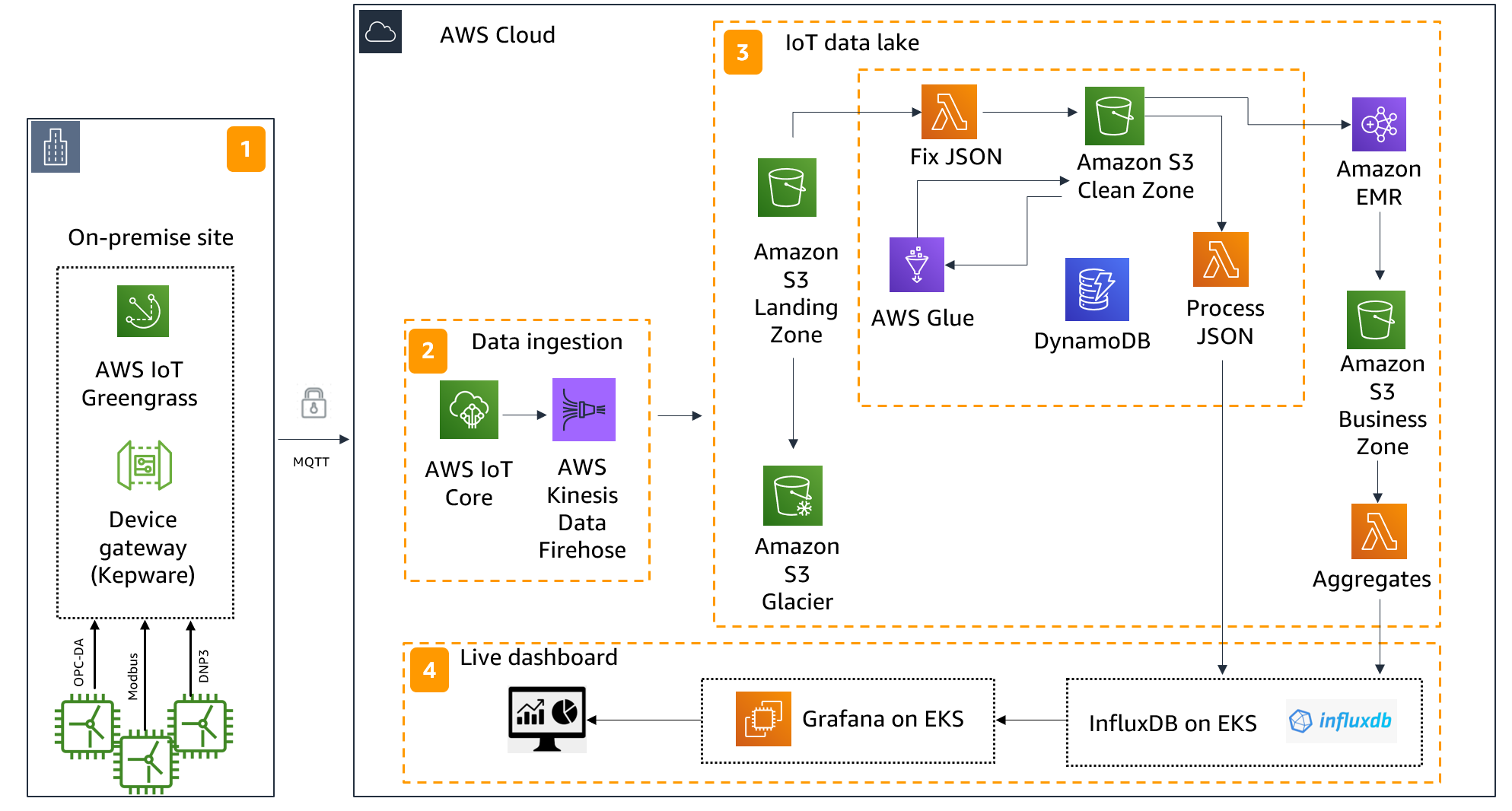
Figure 3: The Greenko MVP reference architecture
Let us go through each stage of the data journey, one block at a time.
Block 1: Connectivity
- AWS IoT Greengrass: AWS IoT Greengrass is an open-source edge runtime and cloud service for building, deploying, and managing device software. It facilitates local processing, messaging, data management, and machine learning (ML) inference and offers prebuilt components to accelerate application development. AWS IoT Greengrass also provides a secure way to seamlessly connect edge devices to any AWS service as well as to third-party services. Greenko uses Kepware as its device gateway, and connectivity is established by configuring the AWS IoT Greengrass components—for example, the MQTT bridge and the X.509 certificates. Both of these components are crucial for communicating with Kepware. Greenko runs AWS IoT Greengrass on the edge, on a Linux machine on the same on-premises network as Kepware.
- Kepware: KEPServerEX provided by Kepware communicates with the original equipment manufacturer (OEM) supervisory control and data acquisition (SCADA) server of the Poovani wind farm. Kepware’s parent company, AWS Partner PTC, provides tools for industrial protocol conversion. The Poovani wind farm uses OPC Data Access protocols and Distributed Network Protocol 3, which are converted to MQTT by Kepware. AWS IoT Greengrass then uses the MQTT protocol to send data to the cloud.
- 509 Certificates: AWS IoT Greengrass issues a unique set of X.509 certificates, which are used to mutually authenticate the connectivity with Kepware. All traffic passing from Kepware to AWS IoT Greengrass is encrypted through secure Transport Layer Security connection. Furthermore, AWS IoT Greengrass encrypts all traffic sent to the cloud with a private X.509 certificate. This is independent of the presence of a VPN. Basically, all traffic from the edge to the cloud is encrypted by default.
Block 2: Data ingestion
- AWS IoT Core: AWS IoT Core lets you connect billions of IoT devices and route trillions of messages to AWS services without managing infrastructure. As a managed cloud solution, it lets connected devices easily and securely interact with cloud applications and other devices. AWS IoT Core also contains a rules engine, which facilitates continual processing of data sent by connected devices. You can configure rules to filter and transform the data. You can also configure rules to route the data to other services through AWS Lambda—a serverless, event-driven compute service—for further processing, storage, or analytics. For example, you can route it to any of the following:
- Amazon DynamoDB: a fully managed, serverless, key-value NoSQL database
- Amazon Simple Notification Service (Amazon SNS): a fully managed messaging service
- Amazon Simple Queue Service (Amazon SQS): a fully managed message queuing service
- Amazon OpenSearch Service (with built-in Kibana integration): a service that makes it easy to perform interactive log analytics, real-time application monitoring, website searches, and more
- Amazon CloudWatch
- Other non-AWS services
In Greenko’s case, we use the AWS IoT rules engine to divert the IoT data to Amazon Kinesis Data Firehose.
- Amazon Kinesis Data Firehose: Amazon Kinesis Data Firehose is an extract, transform, load service that reliably captures, transforms, and delivers streaming data to data lakes, data stores, and analytics services. It can capture, transform, and load streaming data into Amazon Simple Storage Service(Amazon S3) (an object storage service), Amazon Redshift (a fast, fully managed petabyte-scale data warehouse), Amazon OpenSearch Service, and Splunk, facilitating near-real-time analytics with existing business intelligence tools and dashboards you might already be using today. It is a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration. It can also batch, compress, and encrypt the data before loading it, minimizing the amount of storage used at the destination and increasing security. In Greenko’s case, we use Amazon Kinesis Data Firehose to deposit a JSON file to Amazon S3 every 1 minute.
Block 3: IoT data lake
- Landing zone S3 bucket: From the previous step, Amazon Kinesis Data Firehose deposits a JSON file into the first Amazon S3 bucket: the landing zone S3 bucket. This bucket represents the raw version of the data received from the edge. It is not edited in any way and is kept in its original form. Many customers face a regulatory requirement to store the original version of the data, and the landing zone S3 bucket achieves this purpose.
- Amazon S3 Glacier bucket: The Amazon S3 Glacier storage classes are purpose-built for data archiving, providing you with the highest performance, most retrieval flexibility, and the lowest cost archive storage in the cloud. We create a data life cycle policy that moves data from the Landing zone S3 bucket to the Amazon S3 Glacier bucket, after 30 days. This contributes to further reduction of storage costs.
- Fix JSON lambda: We have observed that the JSON file deposited into the landing zone S3 bucket is not structurally correct—that is, it’s not a good JSON. To fix this, we invoke a fix JSON lambda. This is orchestrated by an Amazon S3 lambda event that invokes the lambda every time a file lands in the landing zone S3 bucket. The lambda corrects the JSON structure and deposits a good JSON into the next S3 bucket: the clean zone S3
- Clean zone S3 bucket: This S3 bucket now has the good JSON files deposited by the fix JSON lambda function from the last step. A number of important activities happen at this point:
- Process JSON lambda: This lambda is invoked in response to an Amazon S3 event every time a file arrives in the clean zone S3 The lambda reads the contents of the JSON file and identifies the hot tags. The list of 58 hot tags is stored in an Amazon DynamoDB table. Designed to run high-performance applications at any scale, Amazon DynamoDB is a great choice for storing metadata. Once the hot tags are identified, it updates them to the time series database (TSDB) InfluxDB. This lambda function updates the near-real-time streaming data to InfluxDB and is invoked every 1 minute.
- AWS Glue: AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Here we use AWS Glue to convert the JSON files to Parquet. An AWS Glue job is invoked every 5 minutes, picks up all the new JSON files arriving in the last 5 minutes, and converts them into Parquet. The Parquet files are deposited into a folder called “Parquet Files” in the clean zone S3
- Amazon EMR: Amazon EMR is a cloud big data solution for running large-scale distributed data processing jobs, interactive SQL queries, and ML applications using open-source analytics frameworks such as Apache Spark, Apache Hive, and Presto. Here we use Apache Spark running on a “one leader, two worker node” Amazon EMR cluster on an Amazon Elastic Compute Cloud (Amazon EC2) instance with an AWS Graviton processor. With 64-bit Arm Neoverse cores, AWS Graviton processors are designed by AWS to deliver the best price performance for cloud workloads running on Amazon EC2, which provides secure and resizable compute capacity. Using AWS Graviton2–based Amazon EC2 instances, we were able to achieve up to 15 percent improved performance at up to 50 percent lower costs relative to equivalent previous generation instances in the Mumbai region.
- An Apache Spark job runs every 15 minutes, reads all the new JSON files arriving in the clean zone S3 bucket in the last 15 minutes, and calculates the mathematical average of each of the 93 tags.
- Amazon S3 Business Zone: The mathematical average calculated by Amazon EMR is stored as a JSON file in the Amazon S3 Business Zone. This basically means that for every 15 JSON files in the clean zone S3 bucket, there is 1 JSON file in the Amazon S3 Business Zone. This 15-minute average data is a great source for artificial intelligence (AI) / ML and data science workloads, such as predictive maintenance, time to failure, and energy output forecasting.
- Aggregator Lambda: This lambda is invoked in response to an Amazon S3 lambda event every time a JSON file gets deposited by Amazon EMR into the Amazon S3 Business Zone. The lambda reads the content from the file and identifies the hot tags based on the list in the Amazon DynamoDB table. The hot tags in the JSON file are the 15-minute average values. The tags are then updated to InfluxDB. This lambda function updates the 15-minute average values to InfluxDB and is invoked every 15 minutes.
Block 4: Live dashboard
- InfluxDB on Amazon Elastic Kubernetes Service (Amazon EKS):
- Amazon EKS is a managed container service that you can use to run and scale Kubernetes applications in the cloud or on premises. InfluxDB is an open-source TSDB developed by InfluxData. It is a well-performing data store for retrieval of IoT time series data.
- InfluxDB is an open-source time series database (TSDB) developed by InfluxData and is a performant data store for retrieval of IoT time series data. Both Locuz and Greenko had previous experience working with InfluxDB, and we determined that InfluxDB would be the ideal choice for a time series data store. As InfluxDB is open source, there were no licensing cost associated with InfluxDB leading to an efficient cost to performance ratio. In order to make the setup serverless, we launched InfluxDB on a Kubernetes cluster using Amazon EKS. Amazon EKS provisions and scales the Kubernetes control plane, including the application programming interface (API) servers and backend persistence layer, across multiple Availability Zones for high availability and fault tolerance. Amazon EKS automatically detects and replaces unhealthy control plane nodes and patches the control plane.
- However, although InfluxData provides a highly available InfluxDB option called InfluxDB Cloud, it provides it only in the AWS US-East and AWS US-West Regions. The Greenko solution is based completely in the AWS Asia Pacific (Mumbai) Region, and the Greenko team wanted grassroots-level control over the cluster. This could only be achieved if InfluxDB was set up independently, so we use Amazon EKS to do the heavy lifting of creating and managing clusters. InfluxDB holds the hot data for 48 hours, then deletes it. With the live dashboard available for only the past 48 hours of data, we avoid having unnecessary and redundant data.
Grafana on Amazon EKS: Grafana is a multiplatform open-source analytics and interactive visualization web application. It provides charts, graphs, and alerts for the web when connected to supported data sources. It easily connects with InfluxDB and has a number of plugins for various graphs. Within a short time, we can get insightful visualizations into our time series data. We set up Grafana on Kubernetes using Amazon EKS. Below are few screenshots of the Grafana live dashboard.


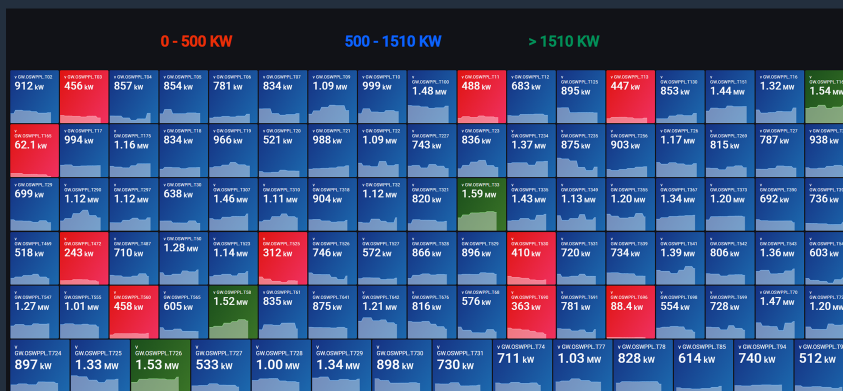
Figure 4: Greenko Sample Dashboard
Determining the costs
Once the MVP was live, we let it run for 1 month. At the end, the AWS cost of running the solution was approximately $8.00 per wind turbine per month. In return for a cost of $8 per month per wind asset (worth $1 million or more each), Greenko gets the following benefits:
- Complete serverless solutions with little to no infrastructure to manage
- Secure connectivity from edge to the cloud
- A highly available and scalable IoT data lake
- A live operational dashboard with a latency of 1 minute
Looking to the future
In the future, Greenko will continue to work with the AWS team to onboard approximately 1,100 wind turbines to the cloud. Greenko will soon expand this effort to solar and hydro assets as well. At the same time, Greenko will continue to collaborate closely with the AWS team on its goals of establishing integrated renewable energy projects and deploying ML-based predictive maintenance and energy forecasting use cases.
For more information, visit Greenko Group. And to find out more about how AWS is empowering digital utilities, visit here.