AWS for Industries
How ERGO built a Risk Management Platform for IFRS 17 and Solvency II Calculations using NoOps Principles
This post is co-authored with Tobias Lierzer of ERGO
About ERGO Group
ERGO Group is part of Munich Re – one of the world’s leading reinsurers and risk carriers. As one of the major insurance groups in Germany and Europe, ERGO Group is represented in around 30 countries worldwide, focusing mainly on Europe and Asia. Like most insurance companies, ERGO must implement the new IFRS 17 accounting standard which is mandatory starting financial year 2023. Under IFRS 17, insurance contracts are measured using their expected cash flow-like discount curve and this will improve the comparability of insurance companies.
Our preparedness for IFRS 17
IFRS 17 is a major project at ERGO, with several hundred people working on it over several years. On the technology side, we chose an industry standard software to run the future IFRS calculations. While this software is also used to run the current calculations for the Solvency II standard, the calculation changes introduced in IFRS 17 made us re-think our existing platform architecture.
First and foremost, with the introduction of IFRS 17, the calculation windows for Solvency II have been reduced from thirty days to three days due to the changes in the calculation process. Both processes need an equal amount of compute resources, which leads to a multiplication of the required compute resources for a very small timeframe.
This poses a huge challenge in terms of compute scalability within a short time-span and such a demand elasticity for resources cannot be covered economically in the company’s own data center. Therefore using cloud computing to acquire and release resources as per our need seemed like the obvious answer.
Secondly, the IFRS 17 calculation platform and the associated COTS software have various constraints that require integration with the ERGO on-premises data center. This includes technical services such as Active Directory, data platforms, as well as direct end user access or process integration. In addition, the integration with several enterprise core systems like SAP, General Ledger, and MDM was also required. This meant that we not only had to select a cloud provider for resource elasticity, but also had to find a seamless integration with our existing core on-premises systems in a short amount of time.
After much consideration, ERGO selected AWS for the IFRS 17 calculation platform. AWS delivers the required resource elasticity and at the same time provides us with managed services such as Amazon FSx for Windows File Server that can be seamlessly integrated into on-premises core systems. This gives us the chance to focus on implementing the traditional COTS software in a modern way and quickly deliver value to the users.
Today, the business department controls the scaling of the environment through their need for calculations and is equipped to comply with the new accounting rules for the insurance industry under IFRS 17.
In the following section, we describe the mechanics of IFRS 17 environment scaling, hybrid integration with on-premises systems, and our no operations (NoOps) principle to overall platform management.
IFRS17 Platform Architecture
The core system of the platform is a classical Windows-based n-tier application along with the compute, data, and end users workstation stack.
Platform Compute layer: Consists of following different server roles:
- Application Server: Core component that manages calculation across Worker Node groups
- Web Server: API server to interact with the COTS software, for example to start calculations
- Worker Nodes: Scaling component that does the IFRS Calculations
- License Server: Static system that validates the COTS software license
Platform Data layer: Managed with MS SQL databases as well as Windows file servers to store input and output data. Both components are technical requirements by the COTS software. While SQL database holds the metadata for the calculation runs, file servers maintain the results of the calculations.
At this layer, we use AWS Managed Services namely Amazon RDS for SQL Server and Amazon FSx for Windows File Server to reduce operational efforts.
Workstation for Actuaries: In addition to the core system, a Windows-based, end user development system can be provisioned on demand to develop and simulate calculation models.
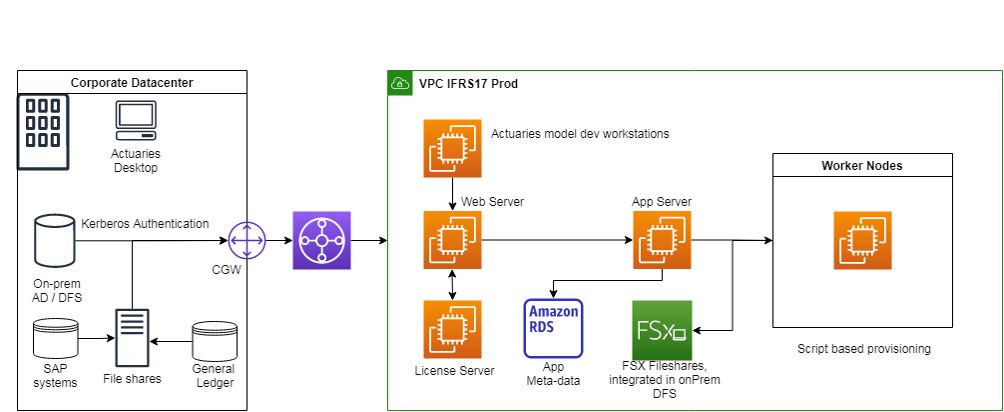 Figure 1: High level platform architecture
Figure 1: High level platform architecture
As indicated previously, while the platform itself runs on the cloud, the interfacing data providing and consuming systems like General ledger, SAP, MDM, and core technical services such as Active Directory or DFS are still on-premises. We therefore need a hybrid network and data center integration.
To achieve this, we built a central network solution that connects several AWS Accounts with each other and to the on-premises data center as depicted in the following diagram. This network connection is built with AWS Transit Gateway and each VPC gets its own distinctive IPv4 segment. Why is a well thought-through IP allocation strategy important? In our experience, using distinctive IPv4 segment not only avoids NAT, but it also enables the platform to utilize VPC internal DHCP mechanisms without having to worry about conflicts with other systems.
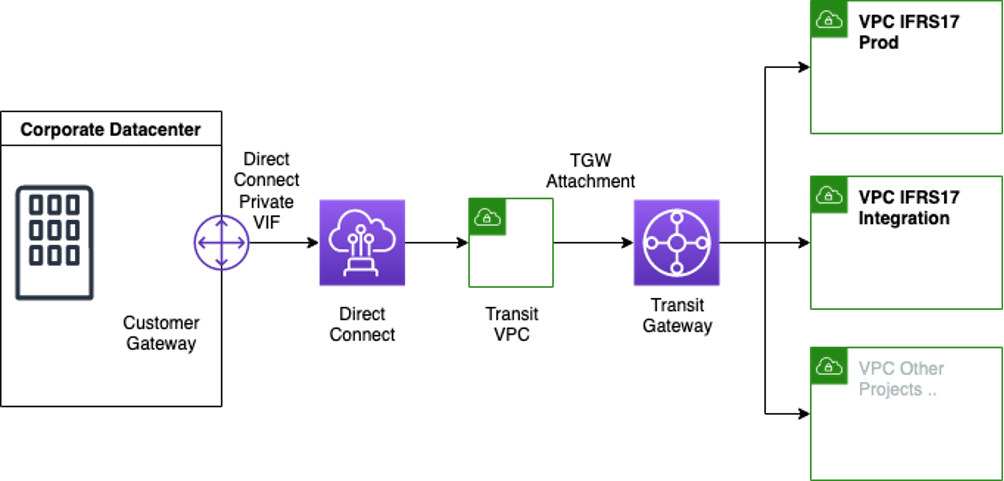 Figure 2: Hybrid networking
Figure 2: Hybrid networking
Next we focus on the hybrid authentication piece of the puzzle. We considered various options available on AWS, namely AWS Managed Microsoft AD, Active Directory Connector, and others, and our final choice was to integrate the platform within a dedicated OU in our on-premises Active Directory. We choose this setup so that we are able to maintain the on-premises authentication and security context for our cloud servers as well as seamlessly integrate file shares and manage user permissions. The ability to use Amazon FSx for Windows File Server with self-managed Active Directory enabled our Active Directory users to bring their existing user identities in Active Directory to authenticate themselves and access the Amazon FSx file system.
With the transparent network connection and integration into data center services we accomplished the foundational steps of the platform.
Next we shift our focus on the mechanisms for platform scaling and maintenance and finally give you a view of how our NoOps approach binds everything together.
Platform Scaling and Automation
As mentioned earlier, scaling the platform during calculation periods is the key driver of bringing the platform to the cloud. The main scaling component is the Worker role. In idle mode during the year, we have a couple of mid-sized Worker servers running. In peak times, we consume up to 150 Amazon EC2 instances with 24 physical cores each!
Interestingly, the lifespan of a Worker during scale-out scenarios is less than a day. But before an instance can be added to the calculation pool, it needs to comply with several requirement categories:
- Functional requirements (working system software installed)
- Security requirements (such as server hardening configuration)
- Compliance requirements (such as up-to-date operating system)
As we were faced with the question of scaling the Worker role for the platform, we thought through three possible options. Let’s look at them one by one:
- Standby Worker Nodes
In this option, we could have a couple hundred Amazon EC2 instances shut down and ready to launch when we need them for calculation. They could be started relatively quickly but this option also has several downsides:
- To keep them up to date (Windows patching, component patching), they’d have to be turned on for at least an hour each month, which will lead to unnecessary EC2 costs.
- Operation costs will go up when you need to look after such a huge farm as unexpected errors show up.
- If you decide to only run them when needed, there is a chance that the servers’ AD-Kerberos Tickets might expire.
- While one does not pay for the stopped EC2 instance, the associated Amazon EBS root volume will accumulate charges.
- Golden Image
The second option is to create a Golden Image for the Worker instances. A technical process creates a Golden Image that contains all required software components and configurations. This includes the Worker software as well as antivirus software or security hardening. The downside of Golden Images is that you need to keep track of the image version that is used. This becomes more complex if you chain Golden Images (for example, when you create a Base Image and a functional image on top of that. More on that topic later).
Another aspect, especially for Windows-based systems, is that the image needs to run through a “Sysprep” before a new instance can be launched. The Sysprep neutralizes the system, for example, by removing the computer name or the SID of the system. Admins need to ensure that the application software is capable of surviving a Sysprep.
- Post-Start Installation
In this option, a Worker instance is started from scratch. Upon start, all necessary installation and configuration steps are run and the system is taken online. This can be done through startup scripts, such as through Amazon EC2 Launch Template.
On the downside, because of the several bootstrapping and software deployment activities, the Worker provisioning itself can take considerable time. In a Windows-based environment, this can be a cost consideration as the EC2 instances are licensed by the hour.
Making a Decision
So finally, which node readiness method did we decide for our use case?
At first sight, the first approach for our Worker Nodes would be the Golden Image solution. The Image would contain all necessary components, the system would be up to date when needed and the provisioning time is low.
But taking a second look, there is a standard set of software and configurations that is needed by not just Worker Nodes but all server types including app, web, and workstation servers. We therefore designed a process to automatically create a general Golden Image called the “ERGO Base Image” that can be loosely coupled to further provisioning processes. Using this Base Image we are now able to bring reusability and flexibility across different server-role provisioning workflows and we will keep revisiting this concept in the following sections. But as a next step, let’s do a deep dive on the Base Image preparation process.
ERGO Base Image Process
AWS releases a new updated, fully-patched Windows Server 2016 Amazon Machine Images (AMI) within five business days of Microsoft’s patch Tuesday (the second Tuesday of each month). It can happen that there are intermediate AMIs, for example, when Microsoft provides a patch outside of regular patch days. AWS also provides an Amazon SNS topic that can be subscribed where new AMIs are published. We instead decided to run a nightly Amazon CloudWatch triggered AWS Lambda function that compares the latest AMI with our current Base Image. In the case of AMI version drift, the Lambda function includes a trigger to create a new AMI, which is helpful when we need to update our internal components that are using the current AMI as a base.
Once the process detects that a new ERGO Base Image needs to be created, we initiate a series of steps as outlined in the following list. Here it’s also important to mention that we make extensive use of AWS Systems Manager automation documents to start automation actions on EC2 instances. In some cases like joining the AD domain, AWS Systems Manager provides reference automation documents and in some cases we had to write our automation documents for custom execution like software installation and configuration. Systems Manager allowed us to run automation at scale but we also intermittently ran into automation quota limitations of the service and we engage AWS service teams to work around the Service Quotas.
- A new EC2 instance is created from the new AMI
- EC2 instance hardening based on configuration files saved in Amazon S3
- Base OS agents like CloudWatch, antivirus, and more are installed
- Time-zone setting and import of ERGO certificates
- New AMI from EC2 instance created
- AMI copied to encrypted AMI
After these steps, we have an encrypted ERGO Base Image that we can use for all upstream systems. Within the cleanup task, the build process’ EC2 instance is shut down and the AMI-ID is published to an internal SNS Topic.
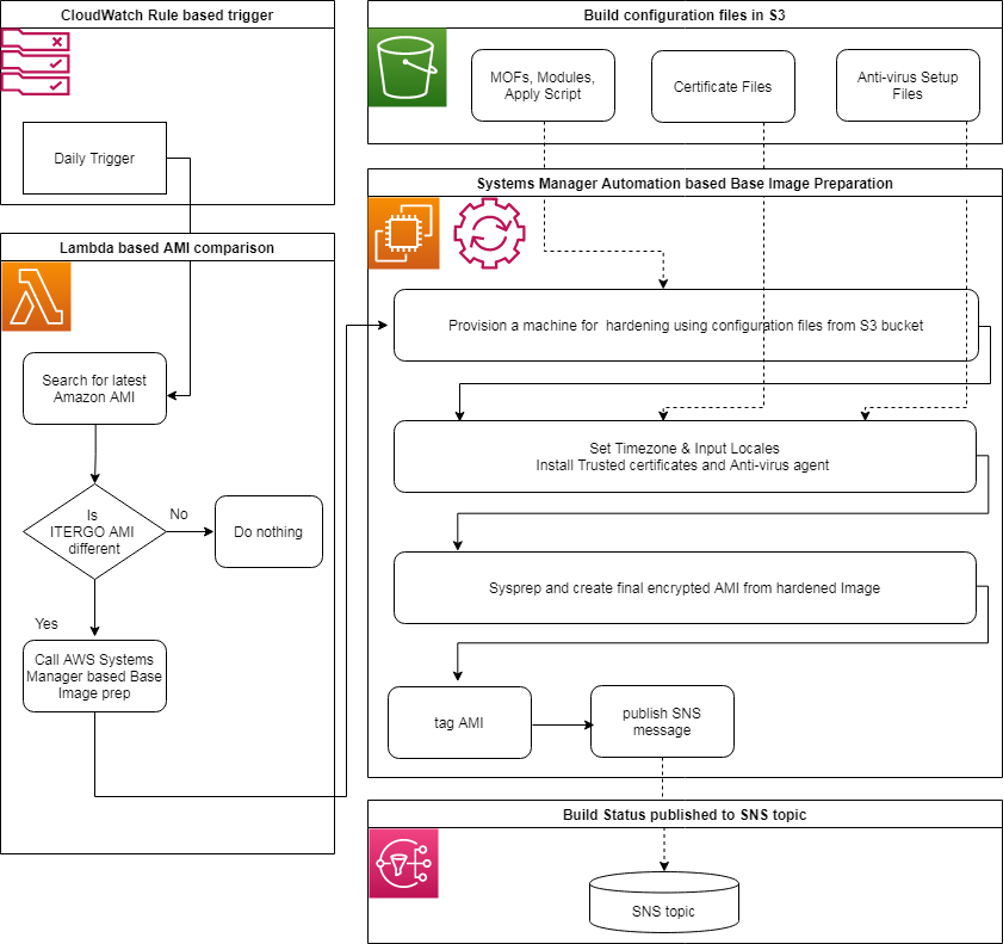 Figure 3: Base Image preparation process
Figure 3: Base Image preparation process
Provisioning in the Platform
As mentioned previously, we have different server roles hosted on Amazon EC2 machines for the IFRS 17 project. Each of these server roles has a different set of software components and associated configurations for the deployment process. With the ERGO Base Image, we now have the choice of deployment for each and every role.
Worker Nodes Provisioning
For the Worker servers, we chose to run a “standby concept.” At a given point in time, an automation is triggered to build an EC2 instance of a Worker on top of an ERGO Base Image AMI with a small EC2 instance type. This instance is duplicated, and all instances are shut down and reconfigured to a new, larger instance type. When the platform needs to proceed calculations, it will start the required number of instances, run the calculations, and shut them down again.
Preparing actual machines and holding them on standby will reduce the start-time compared to creating a Golden Image. This is beneficial as the Worker instances are usually quite large. In addition to that, the Worker software configurations are not modified during usage and stay the same. The only expected reason to reprovision Workers is a new ERGO Base AMI.
We also do not chain the provisioning process of the Worker directly to the ERGO Base Image. While the Base Image is built in response to AWS releasing a new AMI, the rollover of the Worker instances needs to be synchronized with calculation windows as well as the load of the platform.
Web Server Provisioning
The Web Server role is an example where we fully automate the rollover of EC2 instances. It is provisioned through a Launch Template for an EC2 Auto Scaling group. The Launch Template includes the Base AMI as well as the initial installation and configuration of the software.
A separate automation is brought in place that is aware of the Launch Template. It will take the AMI-ID from the Amazon Simple Notification Service message and update it within the Launch Template. The Auto Scaling group will register a change in the Launch Template and re-roll all instances with the new AMI.
Workstation Provisioning
The end-user developer workstation is an example where we create an associated Golden Image off the ERGO Base Image process. On top of a base AMI instance, we install all the tools that are needed to develop and test financial calculation models. From this EC2 instance, we create a new AMI that can be provisioned quickly on demand once an actuary requests it. As the developer workstations are usually provisioned with 48 CPU cores to test financial calculation models and run mainly during quarter-end and year-end cycles, the on-demand provisioning works best for this role.
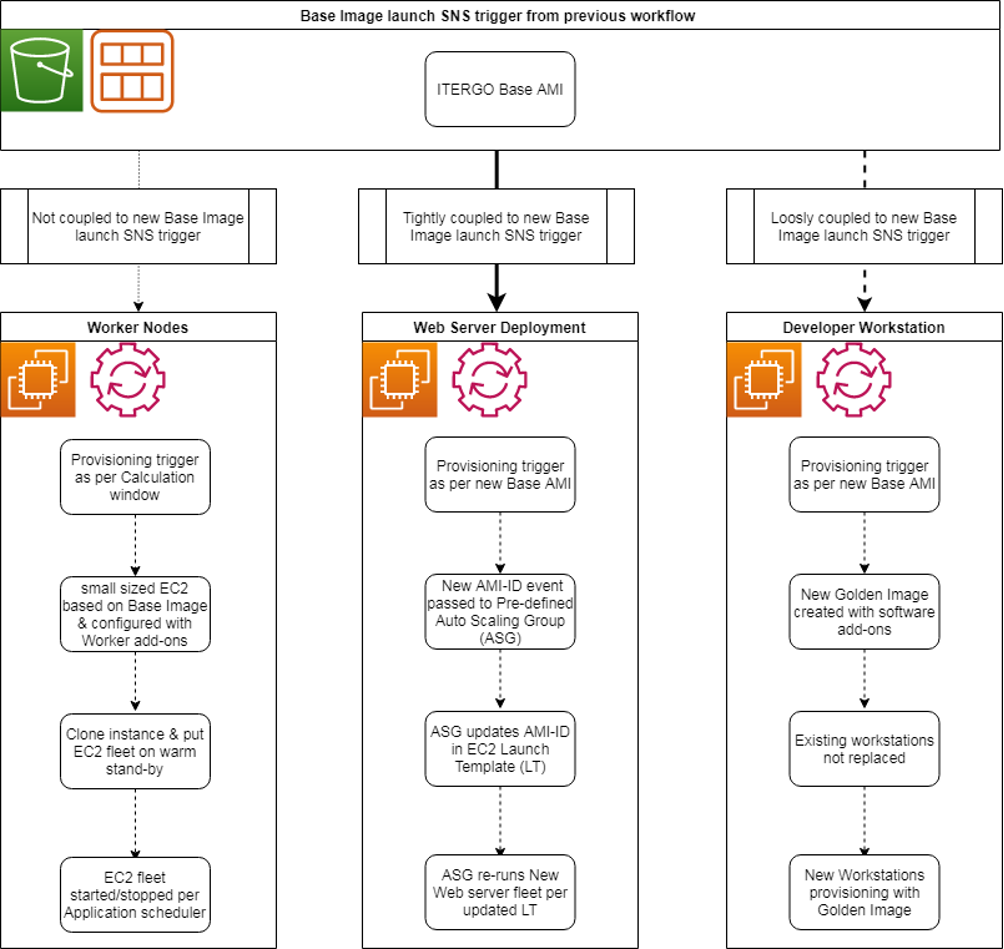 Figure 4: Platform provisioning process
Figure 4: Platform provisioning process
Bringing it all together is our deployment pipeline that is completely automated based on Infrastructure as Code principle and uses an AWS CloudFormation template as the provisioning template. The entire pipeline was built using GitHub Enterprise, Jenkins, and CloudFormation. Beyond the ease of deployment automation, this model also allowed the project team to audit configuration drift using the “drift detection” feature, automatically detecting unmanaged configuration changes to stacks and configuring appropriate remediation action using Amazon CloudWatch and AWS Lambda.
Scaling at the storage layer: We discussed the compute scaling at length in the preceding sections. This shouldn’t take away the fact that we also need storage scaling in accordance with risk model calculations. Here we make use of the storage and throughput capacity scaling feature of Amazon FSx for Windows File Server. This allows us to increase the file system size and throughput capacity as per the calculation requirements to fine-tune performance and reduce costs.
ERGO’s Journey to the “NoOps” Paradigm
Managing a platform this size with manual tasks by an operations team is not a great choice (never has been!) and especially not in a cloud environment where you get all the tools you need for automation. The automated Base Image process was our first step to evaluate immutable infrastructure. In the next step, we found efficient ways to automatically deploy various software components with different restrictions.
From this point, we developed our “NoOps” paradigm and had our own share of learnings along the way: “No Operations, but Automation.”
Automate Everything with IaC
A fully automated platform is the first step towards a NoOps environment. It is important to get this mindset across the whole team, from engineers to architects and project leads.
Automation is always an upfront investment. Most often you would try to cherry pick easily automatable topics. But to achieve a NoOps scenario, you need to start with an automation strategy that includes all components (and eventually include the easy wins). When you automate your platform, take into consideration what components or processes of your surrounding systems can be automated as well.
Build a Team and Upskill Your Workforce
Automating everything will require everyone to build automation, simply due to the amount of work. You therefore need to upskill your workforce to be able to design, create, and maintain automation. In addition, build a team around your platform that is maintaining an open communication and a collaborative mindset. When automation processes start to interact with each other, the people need to be open for discussion and interaction as well.
Don’t Fix Systems
Last but not least, you absolutely don’t want to have manual interference in your systems. Don’t fix the systems, fix the automation. When you start with a full automation target picture in mind, this is kind of obvious. But if you had an interim failure there and went about the cherry-picking way of automation, manual interference on systems could be tempting but will undermine your NoOps scenario.
What’s Next
ERGO built a NoOps-based, highly automated, hybrid cloud environment to run IFRS 17 financial calculations in an effective and timely manner on AWS. Using this platform, ERGO’s Risk department feels confident to act much faster overall and can also pass on new findings and recommendations more quickly.
The next steps on ERGO’s agenda is to set up a FinOps strategy to monitor and report the costs based on business criteria such as business affiliation or calculation necessity (test-runs vs. productive-runs). An interesting topic for us is the evaluation of Spot Instances. Here we are keen to find ways to include Amazon EC2 Spot Instances into the core system in a more dynamic fashion and also to investigate how the core platform can deal with Spot Instances getting dropped during calculations in a way that the user won’t notice and does not affect the legal outcome.