Artificial Intelligence
Amazon SageMaker Automatic Model Tuning now provides up to three times faster hyperparameter tuning with Hyperband
Amazon SageMaker Automatic Model Tuning introduces Hyperband, a multi-fidelity technique to tune hyperparameters as a faster and more efficient way to find an optimal model. In this post, we show how automatic model tuning with Hyperband can provide faster hyperparameter tuning—up to three times as fast.
The benefits of Hyperband
Hyperband presents two advantages over existing black-box tuning strategies: efficient resource utilization and a better time-to-convergence.
Machine learning (ML) models are increasingly training-intensive, involve complex models and large datasets, and require a lot of effort and resources to find the optimal hyperparameters. Traditional black-box search strategies, such as Bayesian, random search, or grid search, tend to scale linearly with the complexity of the ML problem at hand, requiring longer training time.
To speed up hyperparameter tuning and optimize training cost, Hyperband uses Asynchronous Successive Halving Algorithm (ASHA), a strategy that massively parallelizes hyperparameter tuning and automatically stops training jobs early by using previously evaluated configurations to predict whether a specific candidate is promising or not.
As we demonstrate in this post, Hyperband converges to the optimal objective metric faster than most black-box strategies and therefore saves training time. This allows you to tune larger-scale models where evaluating each hyperparameter configuration requires running an expensive training loop, such as in computer vision and natural language processing (NLP) applications. If you’re interested in finding the most accurate models, Hyperband also allows you to run your tuning jobs with more resources and converge to a better solution.
Hyperband with SageMaker
The new Hyperband approach implemented for hyperparameter tuning has a few new data elements changed through AWS API calls. Implementation via the AWS Management Console is not available at this time. Let’s look at some data elements introduced for Hyperband:
- Strategy – This defines the hyperparameter approach you want to choose. A new value for Hyperband is introduced with this change. Valid values are Bayesian, random, and Hyperband.
- MinResource – Defines the minimum number of epochs or iterations to be used for a training job before a decision is made to stop the training.
- MaxResource – Specifies the maximum number of epochs or iterations to be used for a training job to achieve the objective. This parameter is not required if you have numbers of training epochs defined as a hyperparameter in the tuning job.
Implementation
The following sample code shows the tuning job configuration:
The preceding code defines strategy as Hyperband and also defines the lower and upper bound resource limits inside the strategy configuration using HyperbandStrategyConfig, which serves as a lever to control the training runtime. For more details on how to configure and run automatic model tuning, refer to Specify the Hyperparameter Tuning Job Settings.
Hyperband compared to black-box search
In this section, we perform two experiments to compare Hyperband to a black-box search.
First experiment
In the first experiment, given a binary classification task, we aim to optimize a three-layer fully-connected network on a synthetic data set, which contains 5000 data points. The hyperparameters for the network include the number of units per layer, the learning rate of the Adam optimizer, the L2 regularization parameter, and the batch size. The range of these parameters are:
- Number of units per layer – 10 to 1e3
- Learning rate – 1e-4 to 0.1
- L2 regularization parameter – 1e-6 to 2
- Batch size – 10 to 200
The following graph shows our findings.

Comparing Hyperband with other strategies, given a target accuracy of 96%, Hyperband can achieve this target in 357 seconds, while Bayesian needs 560 seconds and random search needs 614 seconds. Hyperband consistently finds a more optimal solution at any given wall-clock time budget. This shows a clear advantage of a multi-fidelity optimization algorithm.
Second experiment
In this second experiment, we consider the Cifar10 dataset and train ResNet-20, a popular network architecture for computer vision tasks. We run all experiments on ml.g4dn.xlarge instances and optimize the neural network through SGD. We also apply standard image augmentation including random flip and random crop. The search space contains the following parameters:
- Mini-batch size: an integer from 4 to 512
- Learning rate of SGD: a float from 1e-6 to 1e-1
- Momentum of SGD: a float from 0.01 to 0.99
- Weight decay: a float from 1e-5 to 1
The following graph illustrates our findings.
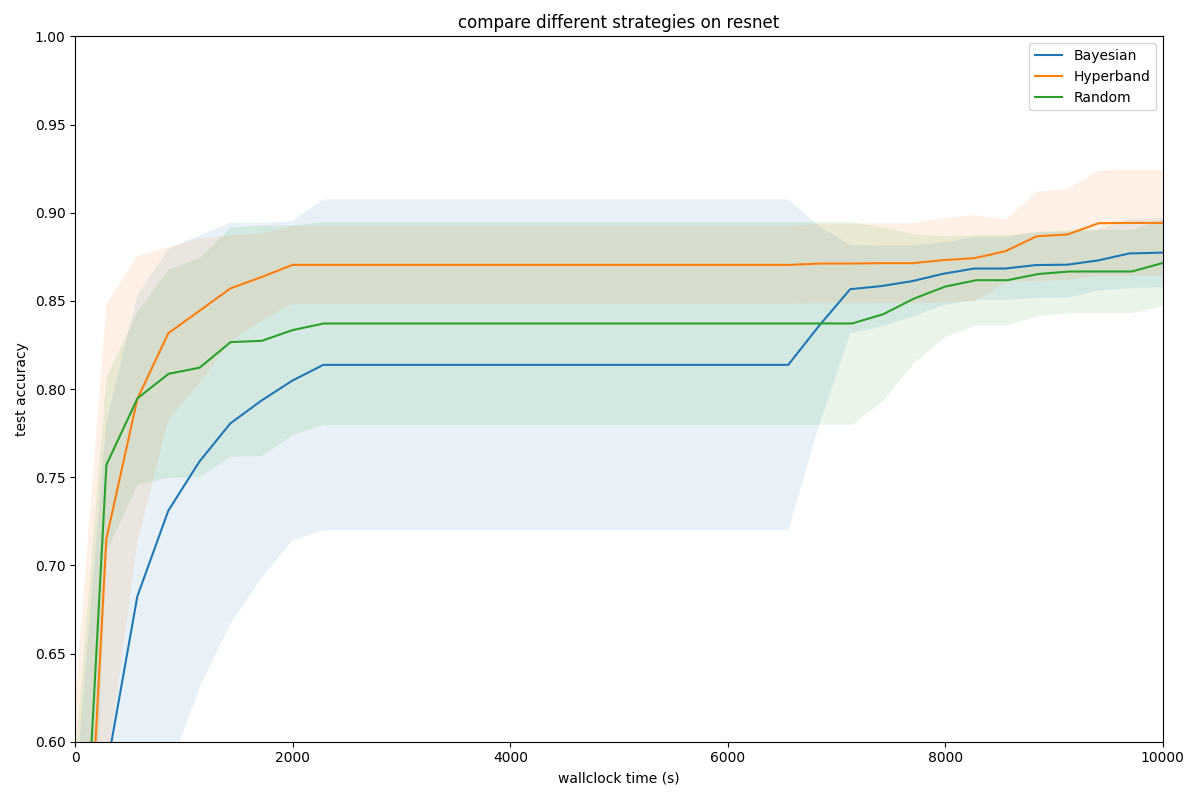
Given a target validation accuracy 0.87, Hyperband can reach it in fewer than 2000 seconds while Random and Bayesian require 10000 and almost 9000 seconds respectively. This amount to a speed-up factor of ~5x and ~4.5x for Hyperband on this task compared to Random and Bayesian strategies. This shows a clear advantage for the multi-fidelity optimization algorithm, which significantly reduces the wall-clock time it takes to tune your deep learning models.
Conclusion
SageMaker Automatic Model Tuning allows you to reduce the time to tune a model by automatically searching for the best hyperparameter configuration within the ranges that you specify. You can find the best version of your model by running training jobs on your dataset with several search strategies, such as black-box or multi-fidelity strategies.
In this post, we discussed how you can now use a multi-fidelity strategy called Hyperband in SageMaker to find the best model. The support for Hyperband makes it possible for SageMaker Automatic Model Tuning to tune larger-scale models where evaluating each hyperparameter configuration requires running an expensive training loop, such as in computer vision and NLP applications.
Finally, we saw how Hyperband further optimizes runtime compared to black-box strategies with early stopping by using previously evaluated configurations to predict whether a specific candidate is promising and, if not, stop the evaluation to reduce the overall time and compute cost. Using Hyperband in SageMaker also allows you to specify the minimum and maximum resource in the HyperbandStrategyConfig parameter for further runtime controls.
To learn more, visit Perform Automatic Model Tuning with SageMaker.
About the authors
 Doug Mbaya is a Senior Partner Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solutions in the cloud.
Doug Mbaya is a Senior Partner Solution architect with a focus in data and analytics. Doug works closely with AWS partners, helping them integrate data and analytics solutions in the cloud.
 Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services industry with their operations in AWS. As a machine learning specialist, Gopi works to help customers succeed in their ML journey.
Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services industry with their operations in AWS. As a machine learning specialist, Gopi works to help customers succeed in their ML journey.
 Xingchen Ma is an Applied Scientist at AWS. He works in the team owning the service for SageMaker Automatic Model Tuning.
Xingchen Ma is an Applied Scientist at AWS. He works in the team owning the service for SageMaker Automatic Model Tuning.