Artificial Intelligence
Build an Autonomous Vehicle on AWS and Race It at the re:Invent Robocar Rally
Autonomous vehicles are poised to take to our roads in massive numbers in the coming years. This has been made possible due to advances in deep learning and its application to autonomous driving. In this post, we take you through a tutorial that shows you how to build a remote control (RC) vehicle that uses Amazon AI services.
1) Build an Autonomous Vehicle on AWS and Race It at the re:Invent Robocar Rally
2) Build an Autonomous Vehicle Part 2: Driving Your Vehicle
3) Building an Autonomous Vehicle Part 3: Connecting Your Autonomous Vehicle
4) Building an Autonomous Vehicle Part 4: Using Behavioral Cloning with Apache MXNet for Your Self-Driving Car
Typically each autonomous vehicle is stacked with a lot of sensors that provide rich telemetry. This telemetry can be used to improve the driving of the individual vehicle but also the user experience. Some examples of those improvements are time saved by smart drive routing, increased vehicle range and efficiency, and increased safety and crash reporting. On AWS, customers like TuSimple have built a sophisticated autonomous platform using Apache MXNet. Recently TuSimple completed a 200-mile driverless ride.
To drive awareness of deep learning, AWS IoT, and the role of artificial intelligence (AI) in autonomous driving, AWS will host a workshop-style hackathon—Robocar Rally at re:Invent 2017. This is the first in a series of blog posts and Twitch videos for developers to learn autonomous AI technologies and to prepare for the hackathon. For more details on the hackathon, see Robocar Rally 2017.

In this tutorial we’ll leverage the open source platform project called Donkey. If you want, you can experiment with your own 1/10 scale electric vehicle. However we’ll stick to the recommended 1/16 scale RC vehicle used in the donkey project.
Here are a couple of videos that show two of the cars that we have built at AWS using the tutorial that follows.
Vehicle Build Process
The process for assembling and configuring the autonomous vehicle can be found in this repo. It also includes a full materials list with links on where to purchase the individual components. The main components are the RC Car, Raspberry Pi, Pi Cam, and Adafruit Servo HAT, the combined cost of which was less than $250. You can buy additional sensors, such as a stereo camera, LIDAR data collector, and an accelerometer, to name a few.
We recommend that you follow the steps on this Github repo to ensure a basic level of capabilities and a path to success that minimizes some undifferentiated heavy lifting.
These are the steps you need to follow to get an end-to-end platform working:
- Assembling the car
- Raspberry Pi configuration
- Setting up the pilot (control) server on an Amazon EC2 instance
- Running the default model on the car
We recommend that you follow the instructions in the links to GitHub for steps 1 and 2.
Donkey Server Build on AWS
A key part of the Donkey solution is the control of the pilot server that brokers the communications between the vehicle and the cloud. It can instruct the “to” switch between the manual control and autopilot. The car uses the images from the Pi camera to navigate. Additionally, images can be saved locally on the Pi or streamed to the EC2 instance for inspection and eventually for training.
The pilot server is built on top of the AWS Deep Learning AMI and deployed as a Docker container. This gives us a high performance, immutable, and easy to manage platform on which to build our AI.
To start, log in to your AWS Management Console and select EC2 from the list of services in a Region that is closest to you. For this blog post, I will choose US-EAST-1.
Step 1: Choose an Amazon Machine Image (AMI)
From the AWS Marketplace, search for “Deep Learning AMI Amazon Ubuntu” and choose the Select.

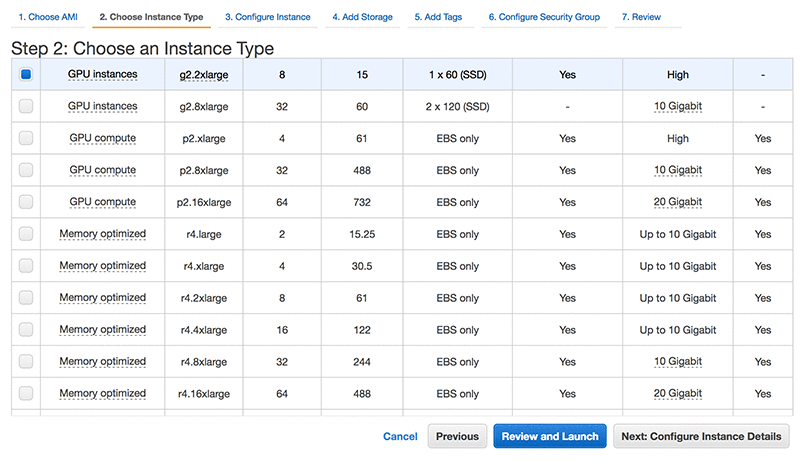
Step 2: Choose an Instance Type
Choose an EC2 instance size and type. For this blog post, I l use the G2.2xlarge because it’s GPU optimized. The G2.2xlarge instance type provides built-in support for seven popular Deep Learning Frameworks: MXNet, Caffe, Caffe2, TensorFlow, Theano, Torch, and CNTK. Lower cost EC2 instances may also be successfully used.
Step 3: Configure Instance Details
Leave all defaults and ensure that you use an appropriate public subnet that allows for inbound communication from the autonomous vehicles that are connecting over the internet.

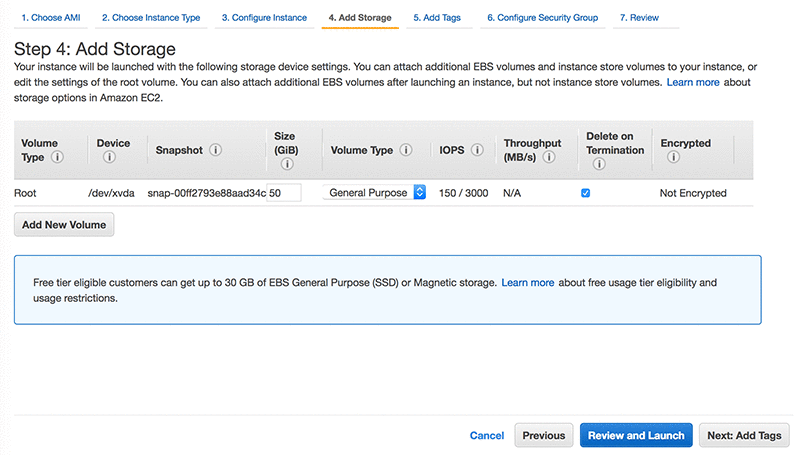
Step 4: Add Storage
This solution doesn’t require much space, so a 32 GB General Purpose GP2 volume should be sufficient.
Step 5: Add Tags
Adding tags is always a good idea because it helps track your resource usage.

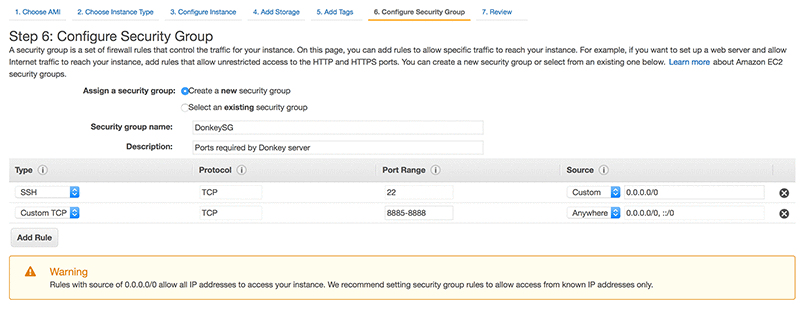
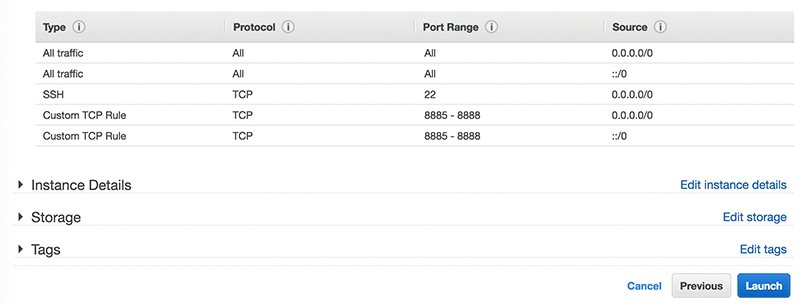
Step 6: Configure Security Group
The Donkey server will need TCP ports 8885-8888 open from any IP address that belongs to an autonomous vehicle. SSH access might also be required after initial setup. We recommend that you put known IP addresses in the Security Group rather than an open range of 0.0.0.0/0.
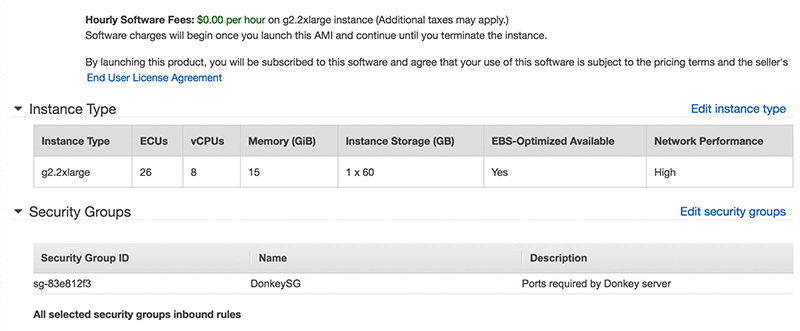
Step 7: Review Instance Launch
Give everything a final review and choose Launch.

Step 8: Key Pair Selection
As a final step, create a new key pair or select an existing key pair. You will require this key pair to connect to this server using SSH. Keep the key pair in a secure location.

Within minutes, the EC2 instance will be ready for you. In your EC2 console you will see your new instance in a running state. Choose the EC2 instance, and then choose Connect. Copy the example snippet to SSH to the instance. Make note of the public IP address because the pilot server and the vehicle (Raspberry Pi) will require this.

- From a terminal screen connect to the Donkey server EC2 instance using SSH:
- Upgrade Keras:
- Download the donkey car repo:
- Install the donkey car package:
- Create a new directory for your donkey car and specify a path:
- Change the directory to your donkey car:
- Execute this command to verify that your pilot server can train models:
- Expected response:
To save costs, we recommend that you shut down the Amazon EBS-backed EC2 instance to avoid incurring compute charges while not driving the vehicle. The primary use of this instance will be to perform the training data that was collected by the Donkey vehicle. The Raspberry Pi has limited compute power. A GPU-enabled EC2 instance will train the neural network on the image and send telemetry data much faster than the Raspberry Pi. A sample neural network that was used to self-drive the car is showcased in a Jupyter notebook along with a sample dataset that is available in our robocar2017 GitHub repository.
Stay tuned for our next blog post, where we continue the tutorial and show you how to connect and drive the autonomous vehicle and set up a driving course.