Artificial Intelligence
Category: Amazon SageMaker

Deploy Mistral AI’s Voxtral on Amazon SageMaker AI
In this post, we demonstrate hosting Voxtral models on Amazon SageMaker AI endpoints using vLLM and the Bring Your Own Container (BYOC) approach. vLLM is a high-performance library for serving large language models (LLMs) that features paged attention for improved memory management and tensor parallelism for distributing models across multiple GPUs.

Build a multimodal generative AI assistant for root cause diagnosis in predictive maintenance using Amazon Bedrock
In this post, we demonstrate how to implement a predictive maintenance solution using Foundation Models (FMs) on Amazon Bedrock, with a case study of Amazon’s manufacturing equipment within their fulfillment centers. The solution is highly adaptable and can be customized for other industries, including oil and gas, logistics, manufacturing, and healthcare.

Introducing SOCI indexing for Amazon SageMaker Studio: Faster container startup times for AI/ML workloads
Today, we are excited to introduce a new feature for SageMaker Studio: SOCI (Seekable Open Container Initiative) indexing. SOCI supports lazy loading of container images, where only the necessary parts of an image are downloaded initially rather than the entire container.

Tracking and managing assets used in AI development with Amazon SageMaker AI
In this post, we’ll explore the new capabilities and core concepts that help organizations track and manage models development and deployment lifecycles. We will show you how the features are configured to train models with automatic end-to-end lineage, from dataset upload and versioning to model fine-tuning, evaluation, and seamless endpoint deployment.

Track machine learning experiments with MLflow on Amazon SageMaker using Snowflake integration
In this post, we demonstrate how to integrate Amazon SageMaker managed MLflow as a central repository to log these experiments and provide a unified system for monitoring their progress.

How Tata Power CoE built a scalable AI-powered solar panel inspection solution with Amazon SageMaker AI and Amazon Bedrock
In this post, we explore how Tata Power CoE and Oneture Technologies use AWS services to automate the inspection process end-to-end.

Checkpointless training on Amazon SageMaker HyperPod: Production-scale training with faster fault recovery
In this post, we introduce checkpointless training on Amazon SageMaker HyperPod, a paradigm shift in model training that reduces the need for traditional checkpointing by enabling peer-to-peer state recovery. Results from production-scale validation show 80–93% reduction in recovery time (from 15–30 minutes or more to under 2 minutes) and enables up to 95% training goodput on cluster sizes with thousands of AI accelerators.
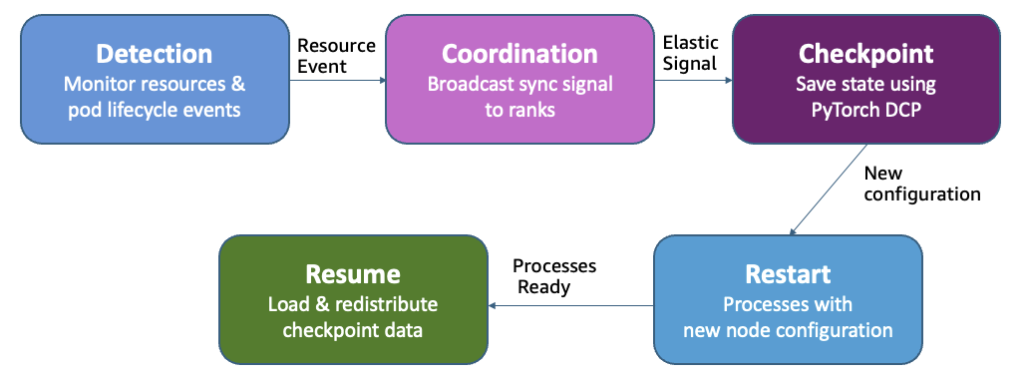
Adaptive infrastructure for foundation model training with elastic training on SageMaker HyperPod
Amazon SageMaker HyperPod now supports elastic training, enabling your machine learning (ML) workloads to automatically scale based on resource availability. In this post, we demonstrate how elastic training helps you maximize GPU utilization, reduce costs, and accelerate model development through dynamic resource adaptation, while maintain training quality and minimizing manual intervention.

Applying data loading best practices for ML training with Amazon S3 clients
In this post, we present practical techniques and recommendations for optimizing throughput in ML training workloads that read data directly from Amazon S3 general purpose buckets.

How Harmonic Security improved their data-leakage detection system with low-latency fine-tuned models using Amazon SageMaker, Amazon Bedrock, and Amazon Nova Pro
This post walks through how Harmonic Security used Amazon SageMaker AI, Amazon Bedrock, and Amazon Nova Pro to fine-tune a ModernBERT model, achieving low-latency, accurate, and scalable data leakage detection.