Artificial Intelligence
How Moovit turns data into insights to help passengers avoid delays using Apache Airflow and Amazon SageMaker
This is a guest post by Moovit’s Software and Cloud Architect, Sharon Dahan.
Moovit, an Intel company, is a leading Mobility as a Service (MaaS) solutions provider and creator of the top urban mobility app. Moovit serves over 1.3 billion riders in 3,500 cities around the world.
We help people everywhere get to their destination in the smoothest way possible, by combining all options for real-time trip planning and payment in one app. We provide governments, cities, transit agencies, operators, and all organizations with mobility challenges with AI-powered mobility solutions that cover planning, operations, and analytics.
In this post, we describe how Moovit built an automated pipeline to train and deploy BERT models which classify public transportation service alerts in multiple metropolitan areas using Apache Airflow and Amazon SageMaker.
The service alert challenge
One of the key features in Moovit’s urban mobility app is offering access to transit service alerts (sourced from local operators and agencies) to app users around the world.
A service alert is a text message that describes a change (which can be positive or negative) in public transit service. These alerts are typically communicated by the operator in a long textual format and need to be analyzed in order to classify their potential impact on the user’s trip plan. The service alert classification affects the way transit recommendations are shown in the app. An incorrect classification may cause users to ignore important service interruptions that may impact their trip plan.

Existing solution and classification challenges
Historically, Moovit applied both automated rule-based classification (which works well for simple logic) as well as manual human classification for more complex cases.
For example, the following alert “Line 46 will arrive 10 min later as a result of an accident with a deer.” Can be classified into one of the following categories:
1: "NO_SERVICE",
2: "REDUCED_SERVICE",
3: "SIGNIFICANT_DELAYS",
4: "DETOUR",
5: "ADDITIONAL_SERVICE",
6: "MODIFIED_SERVICE",
7: "OTHER_EFFECT",
9: "STOP_MOVED",The above example should be classified as 3, which is SIGNIFICANT_DELAYS.
The existing rule-based classification solution searches the text for key phrases (for example delay or late) as illustrated in the following diagram.

While the rule-based classification engine offered accurate classifications, it was able to classify only 20% of the service alerts requiring the other 80% to be manually classified. This was not scalable and resulted in gaps in our service alerts coverage.
NLP based classification with a BERT framework
We decided to leverage a neural network that can learn to classify service alerts and selected the BERT model for this challenge.
BERT (Bidirectional Encoder Representations from Transformers) is an open-source machine learning (ML) framework for natural language processing (NLP). BERT is designed to help computers understand the meaning of ambiguous language in the text by using surrounding text to establish context. The BERT framework was pre-trained using text from the BooksCorpus with 800M words and English Wikipedia with 2,500M words, and can be fine-tuned with question-answer datasets.
We leveraged classified data from our rule-based classification engine as ground truth for the training job and explored two possible approaches:
- Approach 1: The first approach was to train using the BERT pre-trained model which meant adding our layers in the beginning and at the end of the pre-trained model.
- Approach 2: The second approach was to use the BERT tokenizer with a standard five-layer model.
Comparison tests showed that, due to the limited amount of available ground truth data, the BERT tokenizer approach yielded better results, was less time-consuming, and required minimal compute resources for training. The model was able to successfully classify service alerts that could not be classified with the existing rule-based classification engine.
The following diagram illustrates the model’s high-level architecture.
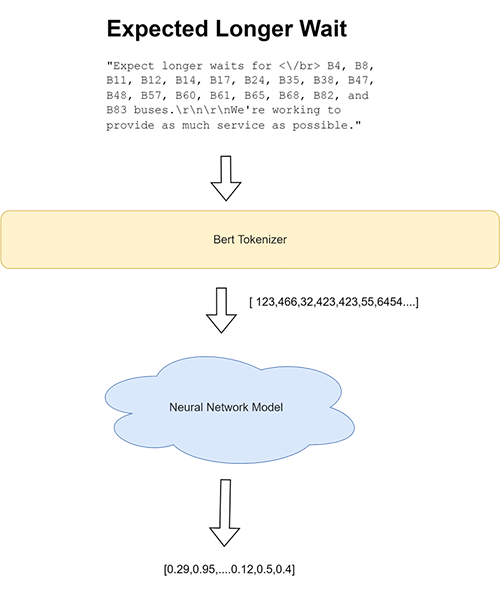
After we have the trained model, we deploy it to a SageMaker endpoint and expose it to the Moovit backend server (with request payload being the service alert’s raw text). See the following example code:
{
"instances": [
"Expect longer waits for <\/br> B4, B8, B11, B12, B14, B17, B24, B35, B38, B47, B48, B57, B60, B61, B65, B68, B82, and B83 buses.\r\n\r\nWe're working to provide as much service as possible."
]
}
The response is the classification and the level of confidence:
{
"response": [
{
"id": 1,
"prediction": "SIGNIFICANT_DELAYS",
"confidance": 0.921
}
]
}
From research to production – overcoming operational challenges
Once we trained an NLP model, we had to overcome several challenges in order to enable our app users to access service alerts at scale and in a timely manner:
- How do we deploy a model to our production environment?
- How do we serve the model at scale with low latency?
- How do we re-train the model in order to future proof our solution?
- How do we expand to other metropolitan areas (aka “metros”) in an efficient way?
Prior to using SageMaker, we used to take the trained ML models and manually integrate them into our backend environment. This created a dependency between the model deployment and a backend upgrade. As a result, our ability to deploy new models was very limited and resulted in extremely rare model updates.
In addition, serving an ML model can require substantial compute resources which are difficult to predict and need to be provisioned for in advance in order to ensure adherence to our strict latency requirements. When the model is served within the backend this can cause unnecessary scaling of compute resources and erratic behavior.
The solution to both these challenges was to use SageMaker endpoints for our real time inference requirements. This enabled us to (1) de-couple the model serving and deployment cycle from the backend release schedule and (2) de-couple the resource provisioning required for model serving (also in peak periods) from the backend provisioning.
Because our group already had deep experience with Airflow, we decided to automate the entire pipeline using Airflow operators in conjunction with SageMaker. As you can see below, we built a full CI/CD pipeline to automate data collection, model re-training and to manage the deployment process. This pipeline can also be leveraged to make the entire process scalable to new metropolitan areas, as we continue to increase our coverage in additional cities worldwide.
AI Lake architecture
The architecture shown in the following diagram is based on SageMaker and Airflow; all endpoints exposed to developers use Amazon API Gateway. This implementation was dubbed “AI lake”.

SageMaker helps data scientists and developers to prepare, build, train, and deploy high-quality machine learning models quickly by bringing together a broad set of capabilities purpose-built for machine learning.
Moovit uses SageMaker to automate the training and deployment process. The trained models are saved to Amazon Simple Storage Service (Amazon S3) and cataloged.
SageMaker helps us significantly reduce the need for engineering time and lets us focus more on developing features for the business and less on the infrastructure required to support the model’s lifecycle. Below you can see Moovit’s SageMaker Training Jobs.

After we train the Metro’s model, we expose it using the SageMaker endpoint. SageMaker enables us to deploy a new version seamlessly to the app, without any downtime.

Moovit uses API Gateway to expose all models under the same domain, as shown in the following screenshot.

Moovit decided to use Airflow to schedule and create a holistic workflow. Each model has its own workflow, which includes the following steps:
- Dataset generation – The owner of this step is the BI team. This step automatically creates a fully balanced dataset with which to train the model. The final dataset is saved to an S3 bucket.
- Train – The owner of this step is the server team. This step fetches the dataset from the previous step and trains the model using SageMaker. SageMaker takes care of the whole training process, such as provisioning the instance, running the training code, saving the model, and saving the training job results and logs.
- Verify – This step is owned by the data science team. During the verification step, Moovit runs a confusion matrix and checks some of the parameters to make sure that the model is healthy and stands within proper thresholds. If the new model misses the criteria, the flow is canceled and the deploy step doesn’t run.
- Deploy – The owner of this step is the DevOps teams. This step triggers the deploy function for SageMaker (using Boto3) to update the existing endpoint or create a new one.
Results
With the AI lake solution and service alert classification model, Moovit accomplished two major achievements:
- Functional – In Metros where the service alert classification model was deployed, Moovit has achieved x3 growth in percentage of classified service alerts! (from 20% to over 60%)
- Operational – Moovit now has the ability to maintain and develop more ML models with less engineering effort, and with very clear and outlined best practices and responsibilities. This opens new opportunities for integrating AI and ML models into Moovit’s products and technologies.
The following charts illustrate the service alert classifications before (left) and after (right) implementing this solution – the turquoise area is the unclassified alerts (aka “modified service”).

Conclusion
In this post, we shared how Moovit used SageMaker with AirFlow to improve the number of classified service alerts by 200% (x3). Moovit is now able to maintain and develop more ML models with less engineering efforts and with very clear practices and responsibilities.
For further reading, refer to the following:
- Build end-to-end machine learning workflows with Amazon SageMaker and Apache Airflow
- Amazon SageMaker Operators in Apache Airflow
About the Authors
 Sharon Dahan is a Software & Cloud Architect at Moovit. He is responsible for bringing innovative and creative solutions which can stand within Moovit’s tremendous scale. In his spare time, Sharon makes tasty hoppy beer.
Sharon Dahan is a Software & Cloud Architect at Moovit. He is responsible for bringing innovative and creative solutions which can stand within Moovit’s tremendous scale. In his spare time, Sharon makes tasty hoppy beer.
 Miron Perel is a Senior Machine Learning Business Development Manager with Amazon Web Services. Miron helps enterprise organizations harness the power of data and Machine Learning to innovate and grow their business.
Miron Perel is a Senior Machine Learning Business Development Manager with Amazon Web Services. Miron helps enterprise organizations harness the power of data and Machine Learning to innovate and grow their business.
 Eitan Sela is a Machine Learning Specialist Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them build and operate machine learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.
Eitan Sela is a Machine Learning Specialist Solutions Architect with Amazon Web Services. He works with AWS customers to provide guidance and technical assistance, helping them build and operate machine learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.