Artificial Intelligence

Implement secure API access to your Amazon Q Business applications with IAM federation user access management
Amazon Q Business provides a rich set of APIs to perform administrative tasks and to build an AI assistant with customized user experience for your enterprise. In this post, we show how to use Amazon Q Business APIs when using AWS Identity and Access Management (IAM) federation for user access management.

Enhance speech synthesis and video generation models with RLHF using audio and video segmentation in Amazon SageMaker
In this post, we show you how to implement an audio and video segmentation solution using SageMaker Ground Truth. We guide you through deploying the necessary infrastructure using AWS CloudFormation, creating an internal labeling workforce, and setting up your first labeling job. By the end of this post, you will have a fully functional audio/video segmentation workflow that you can adapt for various use cases, from training speech synthesis models to improving video generation capabilities.

Using responsible AI principles with Amazon Bedrock Batch Inference
In this post, we explore a practical, cost-effective approach for incorporating responsible AI guardrails into Amazon Bedrock Batch Inference workflows. Although we use a call center’s transcript summarization as our primary example, the methods we discuss are broadly applicable to a variety of batch inference use cases where responsible considerations and data protection are a top priority.

Revolutionizing knowledge management: VW’s AI prototype journey with AWS
we’re excited to share the journey of the VW—an innovator in the automotive industry and Europe’s largest car maker—to enhance knowledge management by using generative AI, Amazon Bedrock, and Amazon Kendra to devise a solution based on Retrieval Augmented Generation (RAG) that makes internal information more easily accessible by its users. This solution efficiently handles documents that include both text and images, significantly enhancing VW’s knowledge management capabilities within their production domain.
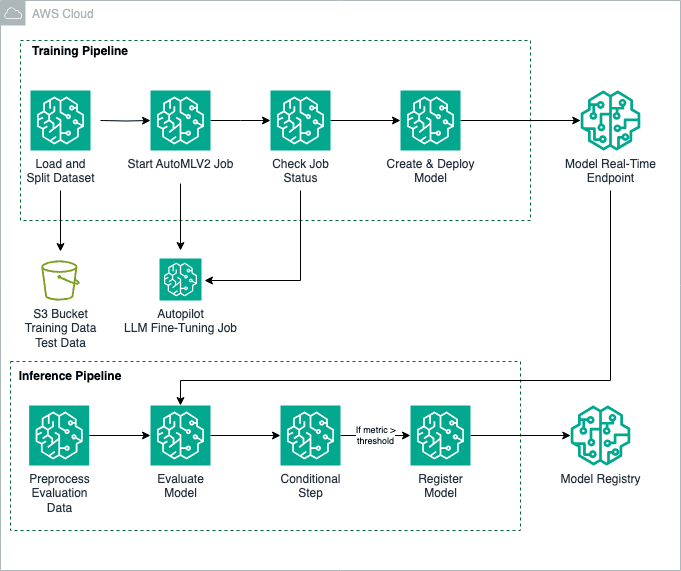
Fine-tune large language models with Amazon SageMaker Autopilot
Fine-tuning foundation models (FMs) is a process that involves exposing a pre-trained FM to task-specific data and fine-tuning its parameters. It can then develop a deeper understanding and produce more accurate and relevant outputs for that particular domain. In this post, we show how to use an Amazon SageMaker Autopilot training job with the AutoMLV2 […]
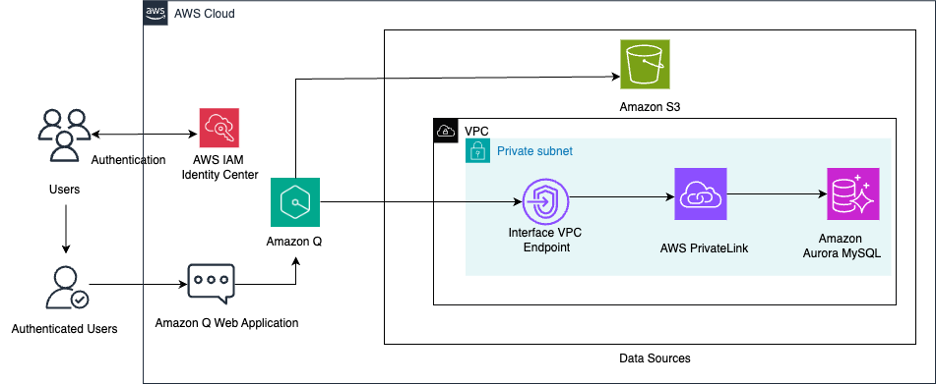
Unify structured data in Amazon Aurora and unstructured data in Amazon S3 for insights using Amazon Q
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. In this post, we explore how you can use Amazon […]

Automate Q&A email responses with Amazon Bedrock Knowledge Bases
In this post, we illustrate automating the responses to email inquiries by using Amazon Bedrock Knowledge Bases and Amazon Simple Email Service (Amazon SES), both fully managed services. By linking user queries to relevant company domain information, Amazon Bedrock Knowledge Bases offers personalized responses.

Streamline RAG applications with intelligent metadata filtering using Amazon Bedrock
In this post, we explore an innovative approach that uses LLMs on Amazon Bedrock to intelligently extract metadata filters from natural language queries. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries. This approach can also enhance the quality of retrieved information and responses generated by the RAG applications.

Embedding secure generative AI in mission-critical public safety applications
This post shows how Mark43 uses Amazon Q Business to create a secure, generative AI-powered assistant that drives operational efficiency and improves community service. We explain how they embedded Amazon Q Business web experience in their web application with low code, so they could focus on creating a rich AI experience for their customers.

How FP8 boosts LLM training by 18% on Amazon SageMaker P5 instances
LLM training has seen remarkable advances in recent years, with organizations pushing the boundaries of what’s possible in terms of model size, performance, and efficiency. In this post, we explore how FP8 optimization can significantly speed up large model training on Amazon SageMaker P5 instances.