Artificial Intelligence
Part 2: How NatWest Group built a secure, compliant, self-service MLOps platform using AWS Service Catalog and Amazon SageMaker
This is the second post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS Professional Services to build a new machine learning operations (MLOps) platform. In this post, we share how the NatWest Group utilized AWS to enable the self-service deployment of their standardized, secure, and compliant MLOps platform using AWS Service Catalog and Amazon SageMaker. This has led to a reduction in the amount of time it takes to provision new environments from days to just a few hours.
We believe that decision-makers can benefit from this content. CTOs, CDAOs, senior data scientists, and senior cloud engineers can follow this pattern to provide innovative solutions for their data science and engineering teams.
Read the entire series:
|
Technology at NatWest Group
NatWest Group is a relationship bank for a digital world that provides financial services to more than 19 million customers across the UK. The Group has a diverse technology portfolio, where solutions to business challenges are often delivered using bespoke designs and with lengthy timelines.
Recently, NatWest Group adopted a cloud-first strategy, which has enabled the company to use managed services to provision on-demand compute and storage resources. This move has led to an improvement in overall stability, scalability, and performance of business solutions, while reducing cost and accelerating delivery cadence. Additionally, moving to the cloud allows NatWest Group to simplify its technology stack by enforcing a set of consistent, repeatable, and preapproved solution designs to meet regulatory requirements and operate in a controlled manner.
Challenges
The pilot stages of adopting a cloud-first approach involved several experimentation and evaluation phases utilizing a wide variety of analytics services on AWS. The first iterations of NatWest Group’s cloud platform for data science workloads confronted challenges with provisioning consistent, secure, and compliant cloud environments. The process of creating new environments took from a few days to weeks or even months. A reliance on central platform teams to build, provision, secure, deploy, and manage infrastructure and data sources made it difficult to onboard new teams to work in the cloud.
Due to the disparity in infrastructure configuration across AWS accounts, teams who decided to migrate their workloads to the cloud had to go through an elaborate compliance process. Each infrastructure component had to be analyzed separately, which increased security audit timelines.
Getting started with development in AWS involved reading a set of documentation guides written by platform teams. Initial environment setup steps included managing public and private keys for authentication, configuring connections to remote services using the AWS Command Line Interface (AWS CLI) or SDK from local development environments, and running custom scripts for linking local IDEs to cloud services. Technical challenges often made it difficult to onboard new team members. After the development environments were configured, the route to release software in production was similarly complex and lengthy.
As described in Part 1 of this series, the joint project team collected large amounts of feedback on user experience and requirements from teams across NatWest Group prior to building the new data science and MLOps platform. A common theme in this feedback was the need for automation and standardization as a precursor to quick and efficient project delivery on AWS. The new platform uses AWS managed services to optimize cost, cut down on platform configuration efforts, and reduce the carbon footprint from running unnecessarily large compute jobs. Standardization is embedded in the heart of the platform, with preapproved, fully configured, secure, compliant, and reusable infrastructure components that are sharable among data and analytics teams.
Why SageMaker Studio?
The team chose Amazon SageMaker Studio as the main tool for building and deploying ML pipelines. Studio provides a single web-based interface that gives users complete access, control, and visibility into each step required to build, train, and deploy models. The maturity of the Studio IDE (integrated development environment) for model development, metadata tracking, artifact management, and deployment were among the features that appealed strongly to the NatWest Group team.
Data scientists at NatWest Group work with SageMaker notebooks inside Studio during the initial stages of model development to perform data analysis, data wrangling, and feature engineering. After users are happy with the results of this initial work, the code is easily converted into composable functions for data transformation, model training, inference, logging, and unit tests so that it’s in a production-ready state.
Later stages of the model development lifecycle involve the use of Amazon SageMaker Pipelines, which can be visually inspected and monitored in Studio. Pipelines are visualized in a DAG (Directed Acyclic Graph) that color-codes steps based on their state while the pipeline runs. In addition, a summary of Amazon CloudWatch Logs is displayed next to the DAG to facilitate the debugging of failed steps. Data scientists are provided with a code template consisting of all the foundational steps in a SageMaker pipeline. This provides a standardized framework (consistent across all users of the platform to ease collaboration and knowledge sharing) into which developers can add the bespoke logic and application code that is particular to the business challenge they’re solving.
Developers run the pipelines within the Studio IDE to ensure their code changes integrate correctly with other pipeline steps. After code changes have been reviewed and approved, these pipelines are built and run automatically based on a main Git repository branch trigger. During model training, model evaluation metrics are stored and tracked in SageMaker Experiments, which can be used for hyperparameter tuning. After a model is trained, the model artifact is stored in the SageMaker model registry, along with metadata related to model containers, data used during training, model features, and model code. The model registry plays a key role in the model deployment process because it packages all model information and enables the automation of model promotion to production environments.
MLOps engineers deploy managed SageMaker batch transform jobs, which scale to meet workload demands. Both offline batch inference jobs and online models served via an endpoint use SageMaker’s managed inference functionality. This benefits both platform and business application teams because platform engineers no longer spend time configuring infrastructure components for model inference, and business application teams don’t write additional boilerplate code to set up and interact with compute instances.
Why AWS Service Catalog?
The team chose AWS Service Catalog to build a catalog of secure, compliant, and preapproved infrastructure templates. The infrastructure components in an AWS Service Catalog product are preconfigured to meet NatWest Group’s security requirements. Role access management, resource policies, networking configuration, and central control policies are configured for each resource packaged in an AWS Service Catalog product. The products are versioned and shared with application teams by following a standard process that enables data science and engineering teams to self-serve and deploy infrastructure immediately after obtaining access to their AWS accounts.
Platform development teams can easily evolve AWS Service Catalog products over time to enable the implementation of new features based on business requirements. Iterative changes to products are made with the help of AWS Service Catalog product versioning. When a new product version is released, the platform team merges code changes to the main Git branch and increments the version of the AWS Service Catalog product. There is a degree of autonomy and flexibility in updating the infrastructure because business application accounts can use earlier versions of products before they migrate to the latest version.
Solution overview
The following high-level architecture diagram shows how a typical business application use case is deployed on AWS. The following sections go into more detail regarding the account architecture, how infrastructure is deployed, user access management, and how different AWS services are used to build ML solutions.
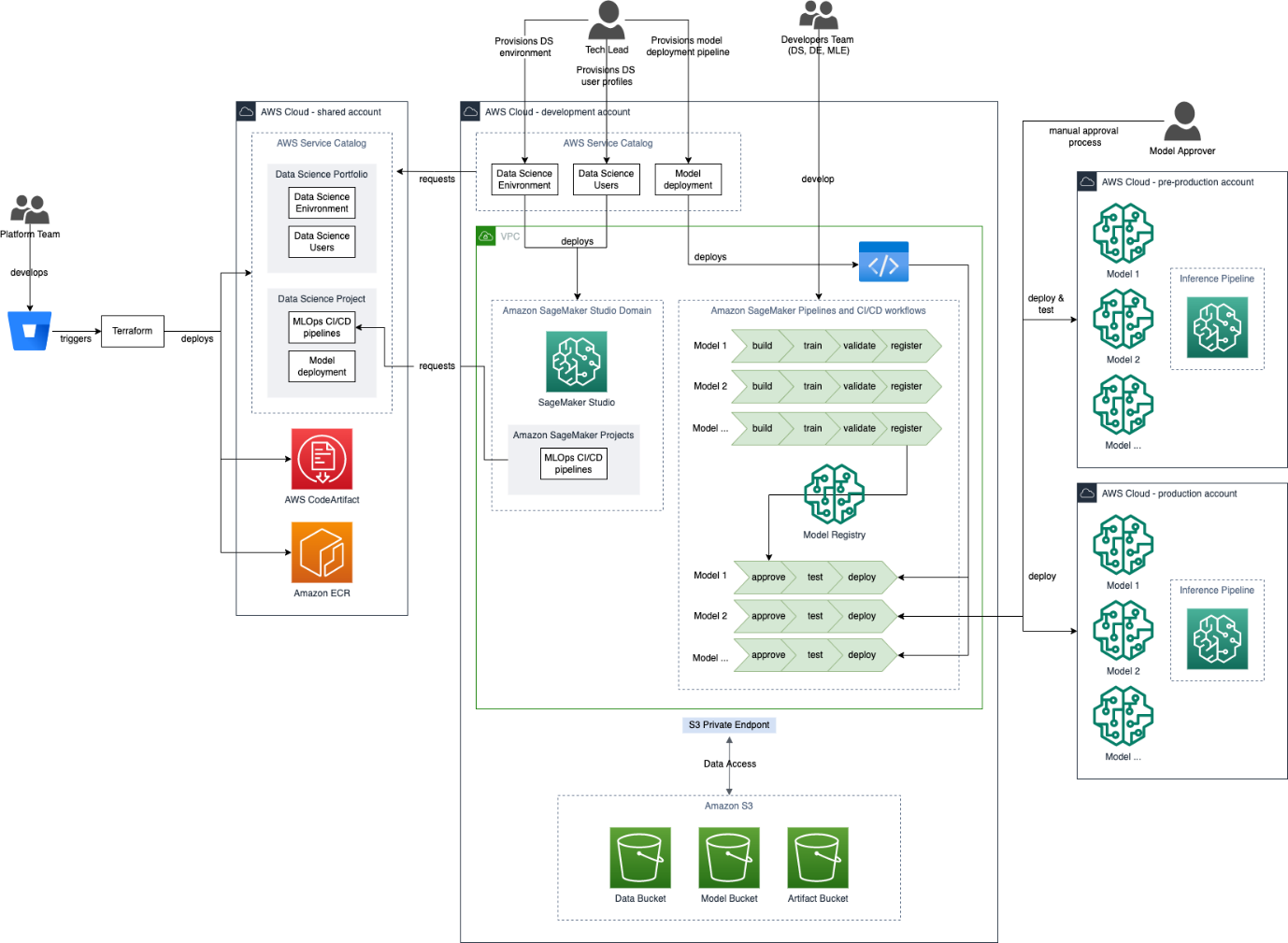
As shown in the architecture diagram, accounts follow a hub and spoke model. A shared platform account serves as a hub account, where resources required by business application team (spoke) accounts are hosted by the platform team. These resources include the following:
- A library of secure, standardized infrastructure products used for self-service infrastructure deployments, hosted by AWS Service Catalog
- Docker images, stored in Amazon Elastic Container Registry (Amazon ECR), which are used during the run of SageMaker pipeline steps and model inference
- AWS CodeArtifact repositories, which host preapproved Python packages
These resources are automatically shared with spoke accounts via the AWS Service Catalog portfolio sharing and import feature, and AWS Identity and Access Management (IAM) trust policies in the case of both Amazon ECR and CodeArtifact.
Each business application team is provisioned three AWS accounts in the NatWest Group infrastructure environment: development, pre-production, and production. The environment names refer to the account’s intended role in the data science development lifecycle. The development account is used to perform data analysis and wrangling, write model and model pipeline code, train models, and trigger model deployments to pre-production and production environments via SageMaker Studio. The pre-production account mirrors the setup of the production account and is used to test model deployments and batch transform jobs before they are released into production. The production account hosts models and runs production inferencing workloads.
User management
NatWest Group has strict governance processes to enforce user role separation. Five separate IAM roles have been created for each user persona.
The platform team uses the following roles:
- Platform support engineer – This role contains permissions for business-as-usual tasks and a read-only view of the rest of the environment for monitoring and debugging the platform.
- Platform fix engineer – This role has been created with elevated permissions. It’s used if there are issues with the platform that require manual intervention. This role is only assumed in an approved, time-limited manner.
The business application development teams have three distinct roles:
- Technical lead – This role is assigned to the application team lead, often a senior data scientist. This user has permission to deploy and manage AWS Service Catalog products, trigger releases into production, and review the status of the environment, such as AWS CodePipeline statuses and logs. This role doesn’t have permission to approve a model in the SageMaker model registry.
- Developer – This role is assigned to all team members that work with SageMaker Studio, which includes engineers, data scientists, and often the team lead. This role has permissions to open Studio, write code, and run and deploy SageMaker pipelines. Like the technical lead, this role doesn’t have permission to approve a model in the model registry.
- Model approver – This role has limited permissions relating to viewing, approving, and rejecting models in the model registry. The reason for this separation is to prevent any users that can build and train models from approving and releasing their own models into escalated environments.
Separate Studio user profiles are created for developers and model approvers. The solution uses a combination of IAM policy statements and SageMaker user profile tags so that users are only permitted to open a user profile that matches their user type. This makes sure that the user is assigned the correct SageMaker execution IAM role (and therefore permissions) when they open the Studio IDE.
Self-service deployments with AWS Service Catalog
End-users utilize AWS Service Catalog to deploy data science infrastructure products, such as the following:
- A Studio environment
- Studio user profiles
- Model deployment pipelines
- Training pipelines
- Inference pipelines
- A system for monitoring and alerting
End-users deploy these products directly through the AWS Service Catalog UI, meaning there is less reliance on central platform teams to provision environments. This has vastly reduced the time it takes for users to gain access to new cloud environments, from multiple days down to just a few hours, which ultimately has led to a significant improvement in time-to-value. The use of a common set of AWS Service Catalog products supports consistency within projects across the enterprise and lowers the barrier for collaboration and reuse.
Because all data science infrastructure is now deployed via a centrally developed catalog of infrastructure products, care has been taken to build each of these products with security in mind. Services have been configured to communicate within Amazon Virtual Private Cloud (Amazon VPC) so traffic doesn’t traverse the public internet. Data is encrypted in transit and at rest using AWS Key Management Service (AWS KMS) keys. IAM roles have also been set up to follow the principle of least privilege.
Finally, with AWS Service Catalog, it’s easy for the platform team to continually release new products and services as they become available or required by business application teams. These can take the form of new infrastructure products, for example providing the ability for end-users to deploy their own Amazon EMR clusters, or updates to existing infrastructure products. Because AWS Service Catalog supports product versioning and utilizes AWS CloudFormation behind the scenes, in-place upgrades can be used when new versions of existing products are released. This allows the platform teams to focus on building and improving products, rather than developing complex upgrade processes.
Integration with NatWest’s existing IaC software
AWS Service Catalog is used for self-service data science infrastructure deployments. Additionally, NatWest’s standard infrastructure as code (IaC) tool, Terraform, is used to build infrastructure in the AWS accounts. Terraform is used by platform teams during the initial account setup process to deploy prerequisite infrastructure resources such as VPCs, security groups, AWS Systems Manager parameters, KMS keys, and standard security controls. Infrastructure in the hub account, such as the AWS Service Catalog portfolios and the resources used to build Docker images, are also defined using Terraform. However, the AWS Service Catalog products themselves are built using standard CloudFormation templates.
Improving developer productivity and code quality with SageMaker projects
SageMaker projects provide developers and data scientists access to quick-start projects without leaving SageMaker Studio. These quick-start projects allow you to deploy multiple infrastructure resources at the same time in just a few clicks. These include a Git repository containing a standardized project template for the selected model type, Amazon Simple Storage Service (Amazon S3) buckets for storing data, serialized models and artifacts, and model training and inference CodePipeline pipelines.
The introduction of standardized code base architectures and tooling now make it easy for data scientists and engineers to move between projects and ensure code quality remains high. For example, software engineering best practices such as linting and formatting checks (run both as automated checks and pre-commit hooks), unit tests, and coverage reports are now automated as part of training pipelines, providing standardization across all projects. This has improved the maintainability of ML projects and will make it easier to move these projects into production.
Automating model deployments
The model training process is orchestrated using SageMaker Pipelines. After models have been trained, they’re stored in the SageMaker model registry. Users assigned the model approver role can open the model registry and find information relating to the training process, such when the model was trained, hyperparameter values, and evaluation metrics. This information helps the user decide whether to approve or reject a model. Rejecting a model prevents the model from being deployed into an escalated environment, whereas approving a model triggers a model promotion pipeline via CodePipeline that automatically copies the model to the pre-production AWS account, ready for inference workload testing. After the team has confirmed that the model works correctly in pre-production, a manual step in the same pipeline is approved and the model is automatically copied over to the production account, ready for production inferencing workloads.
Outcomes
One of the main aims of this collaborative project between NatWest and AWS was to reduce the time it takes to provision and deploy data science cloud environments and ML models into production. This has been achieved—NatWest can now provision new, scalable, and secure AWS environments in a matter of hours, compared to days or even weeks. Data scientists and engineers are now empowered to deploy and manage data science infrastructure by themselves using AWS Service Catalog, reducing reliance on centralized platform teams. Additionally, the use of SageMaker projects enables users to begin coding and training models within minutes, while also providing standardized project structures and tooling.
Because AWS Service Catalog serves as the central method to deploy data science infrastructure, the platform can easily be expanded and upgraded in the future. New AWS services can be offered to end-users quickly when the need arises, and existing AWS Service Catalog products can be upgraded in place to take advantage of new features.
Finally, the move towards managed services on AWS means compute resources are provisioned and shut down on demand. This has provided cost savings and flexibility, while also aligning with NatWest’s ambition to be net-zero by 2050 due to an estimated 75% reduction in CO2 emissions.
Conclusion
The adoption of a cloud-first strategy at NatWest Group led to the creation of a robust AWS solution that can support a large number of business application teams across the organization. Managing infrastructure with AWS Service Catalog has improved the cloud onboarding process significantly by using secure, compliant, and preapproved building blocks of infrastructure that can be easily expanded. Managed SageMaker infrastructure components have improved the model development process and accelerated the delivery of ML projects.
To learn more about the process of building production-ready ML models at NatWest Group, take a look at the rest of this four-part series on the strategic collaboration between NatWest Group and AWS Professional Services:
- Part 1 explains how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform
- Part 3 provides an overview of how NatWest Group uses SageMaker services to build auditable, reproducible, and explainable ML models
- Part 4 details how NatWest data science teams migrate their existing models to SageMaker architectures
About the Authors
 Junaid Baba is DevOps Consultant at AWS Professional Services He leverages his experience in Kubernetes, distributed computing, AI/MLOps to accelerated cloud adoption of UK financial services industry customers. Junaid has been with AWS since June 2018. Prior to that, Junaid worked with number of financial start-ups driving DevOps practices. Outside of work he has interests in trekking, modern art, and still photography.
Junaid Baba is DevOps Consultant at AWS Professional Services He leverages his experience in Kubernetes, distributed computing, AI/MLOps to accelerated cloud adoption of UK financial services industry customers. Junaid has been with AWS since June 2018. Prior to that, Junaid worked with number of financial start-ups driving DevOps practices. Outside of work he has interests in trekking, modern art, and still photography.
 Yordanka Ivanova is a Data Engineer at NatWest Group. She has experience in building and delivering data solutions for companies in the financial services industry. Prior to joining NatWest, Yordanka worked as a technical consultant where she gained experience in leveraging a wide variety of cloud services and open-source technologies to deliver business outcomes across multiple cloud platforms. In her spare time, Yordanka enjoys working out, traveling and playing guitar.
Yordanka Ivanova is a Data Engineer at NatWest Group. She has experience in building and delivering data solutions for companies in the financial services industry. Prior to joining NatWest, Yordanka worked as a technical consultant where she gained experience in leveraging a wide variety of cloud services and open-source technologies to deliver business outcomes across multiple cloud platforms. In her spare time, Yordanka enjoys working out, traveling and playing guitar.
 Michael England is a software engineer in the Data Science and Innovation team at NatWest Group. He is passionate about developing solutions for running large-scale Machine Learning workloads in the cloud. Prior to joining NatWest Group, Michael worked in and led software engineering teams developing critical applications in the financial services and travel industries. In his spare time, he enjoys playing guitar, travelling and exploring the countryside on his bike.
Michael England is a software engineer in the Data Science and Innovation team at NatWest Group. He is passionate about developing solutions for running large-scale Machine Learning workloads in the cloud. Prior to joining NatWest Group, Michael worked in and led software engineering teams developing critical applications in the financial services and travel industries. In his spare time, he enjoys playing guitar, travelling and exploring the countryside on his bike.