Artificial Intelligence
Scaling your AI-powered Battlesnake with distributed reinforcement learning in Amazon SageMaker
Battlesnake is an AI competition in which you build AI-powered snakes. Battlesnake’s rules are similar to the traditional snakes game. Your goal is to be the last surviving snake when competing against other snakes. Developers of all levels build snakes using techniques ranging from unique heuristic-based strategies to state-of-the-art deep reinforcement learning (RL) algorithms.
You can use the SageMaker Battlesnake Starter Pack to build your own snake and compete in the Battlesnake arena. For more information, see Building an AI-powered Battlesnake with reinforcement learning on Amazon SageMaker. The Starter Pack contains a development environment for you to develop multiple strategies on Amazon SageMaker. The strategies include RL-based policy training and decision tree-based heuristics. The previous SageMaker Battlesnake Starter Pack provided an Apache MXNet based training script to develop a deep Q-networks (DQN) [1]-based snake policy. The algorithm implementation is easy to follow and modify, and provides an educational experience for novice developers.
This post describes an update to the Starter Pack that uses Amazon SageMaker for fully managed RL and provides a 10 times greater reward with the same training time. The Starter Pack uses the built-in capabilities of Amazon SageMaker for distributed RL training, in which the agent’s policy is updated while simulation steps are collected simultaneously with multiple nodes available in the instance. This post also walks you through the basics of distributed RL and how to use distributed RL in Amazon SageMaker to train your snake.
Amazon SageMaker is a fully managed service that enables you to build and deploy models faster and with less heavy lifting. Amazon SageMaker has built-in features to assist with data labeling and preparation; training, tuning and debugging models; and deploying and monitoring models in production. Additionally, Amazon SageMaker has built-in cost-saving mechanisms such as Amazon SageMaker Ground Truth to reduce costs on data labeling by up to 70%, Managed Spot Training to reduce training costs by up to 90%, and Amazon SageMaker supports Amazon Elastic Inference to lower machine learning inference costs by up to 75%.
This post discusses the fully managed RL capabilities in Amazon SageMaker, which include pre-packaged RL toolkits and fully managed model training and deployment. You can use built-in deep learning frameworks such as MXNet and TensorFlow, use various built-in RL algorithms from Intel Coach and RLlib libraries to train your RL policies, and easily start your RL experiments in the Amazon SageMaker Experiments. For more information, see Amazon SageMaker Experiments – Organize, Track And Compare Your Machine Learning Trainings. For more information about applying RL to domains such as recommendation systems, robotics, financial management, and more, see the GitHub repo.
Distributed reinforcement learning
An RL agent typically develops its policy by interacting with the environment in a trial-and-error fashion. During the training process, the agent collects and learns from simulation steps to refine its policy. The simulation steps are also known as experiences or rollouts. This post uses DQN as an illustration. DQN relies on communication between a replay buffer and policy for gradient-based optimizations on target and local Q-networks. For more information, see Building an AI-powered Battlesnake with reinforcement learning on Amazon SageMaker.
The following diagram illustrates the different components and data flow of DQN.
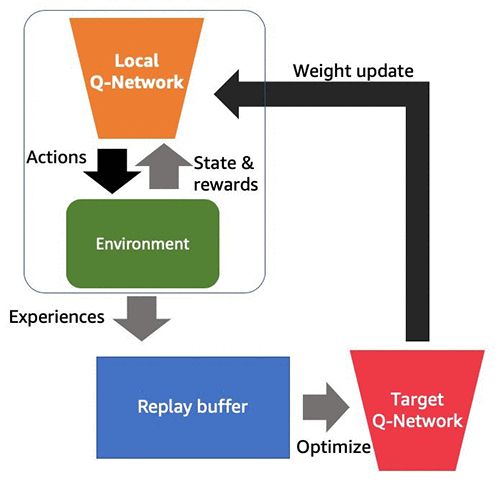
The DQN algorithm consists of multiple components, and distributed RL exploits the separable nature of these components to scale up the training. Specifically, distributed RL uses multiple rollout workers to create a copy of the simulator and collect experiences with the agent policy, and you use these experiences for the policy update. In DQN, the policy optimizer synchronously pulls samples from rollout workers and concatenates them. After the network weights are updated, the weights are broadcasted back to all rollout workers. This process can be asynchronous, depending on the algorithm type. For instance, the optimizer in APEX-DQN [2] asynchronously pulls and applies gradients from rollout workers, and sends updated weights back as needed. The following diagram illustrates a distributed RL model with multiple workers in a single Amazon SageMaker instance with 4 CPUs. 1 CPU is assigned to the driver and the remaining are used for environment simulation.
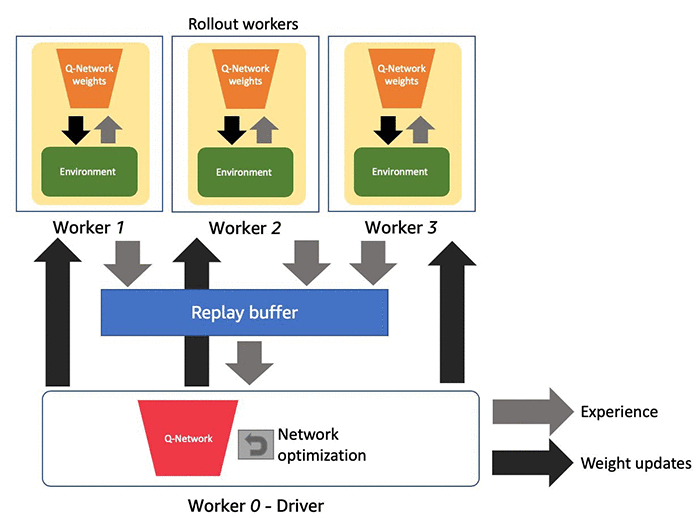
Amazon SageMaker supports distributed RL in a single Amazon SageMaker ML instance with just a few lines of configuration by using the Ray RLlib [3] library. By default, Amazon SageMaker allocates one CPU for the driver, which runs the training process, manages the coordination among workers, and handles updating the global policy parameters. You can use the remaining resources as workers devoted to parallel experience collection.
Amazon SageMaker lets you take this one step further by scaling your RL jobs to multiple Amazon SageMaker ML instances, which boosts the resources available for training. You can distribute your training job in two ways: homogeneous and heterogeneous scaling.
In homogeneous scaling, you use multiple instances with the same type (typically CPU instances) for a single Amazon SageMaker job. Similar to the configuration shown earlier, a single CPU core is reserved for the driver, and you can use all the remaining as rollout workers which generate experiences through environmental simulations. The number of available CPU cores increases with multiple instances. Homogeneous scaling is beneficial when experience collection is the bottleneck of the training workflow; for example, when your environment is computationally heavy.
The following diagram illustrates the architecture of homogeneous scaling with multiple instances each with 4 CPUs. One of the CPUs in the primary instance is used as the driver and the rest CPUs both in primary and secondary instances are used for environment simulation.
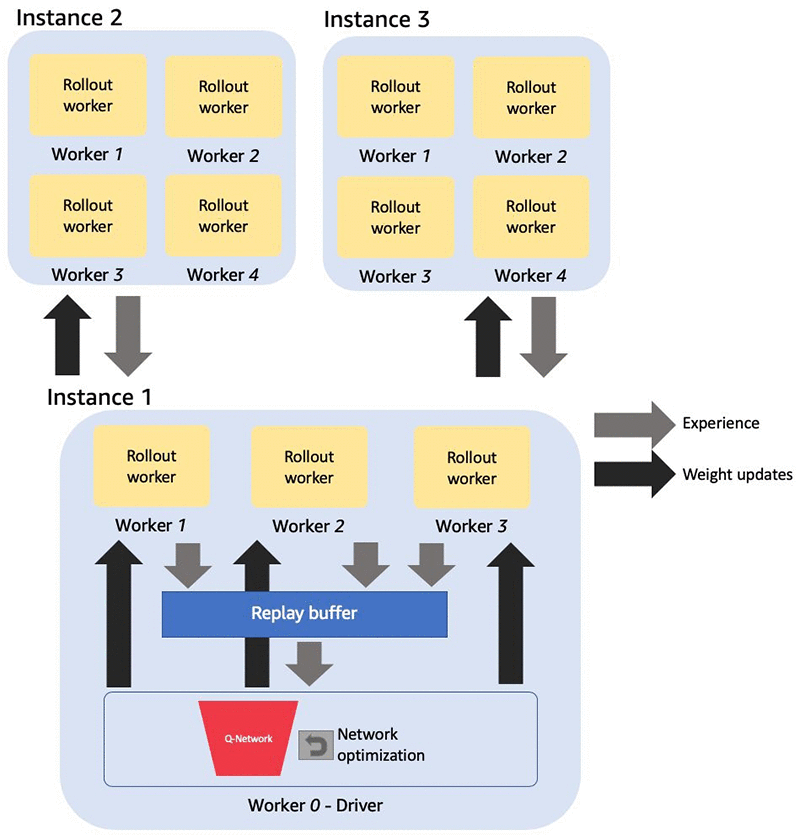
With more rollout workers, neural network updates can often become the bottleneck. In this case, you could use heterogeneous scaling, in which you use different instance types together. A typical choice would be to use GPU instances to perform network optimization and CPU instances to collect experiences for faster training at optimized costs. Amazon SageMaker allows you to achieve this by spinning up two jobs within the same Amazon VPC, and the communications between the instances are taken care of automatically.
The following diagram illustrates the architecture in which the primary job consumes one GPU instance and the secondary job consumes three CPU instances.
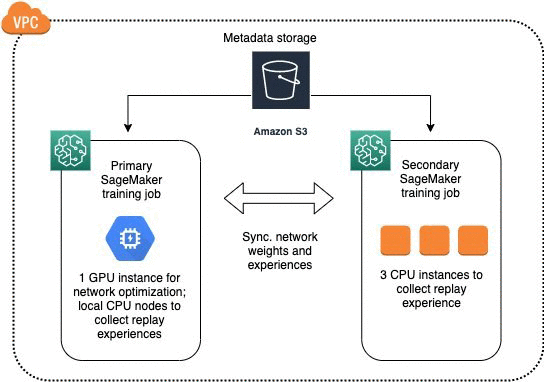
You can configure the specific number of instances and types to suit your use case. For more information about distributed RL training across multiple nodes, see the following notebook on the GitHub repo.
Training your snake with a single instance
To run an RL training job, you can follow a similar workflow to running other Amazon SageMaker training jobs, which is to use estimators to run training scripts. In the following example, the entry point is a training script (train-mabs.py) that interfaces between the environment and the policy. To launch a single instance RL training job, you first create an RLEstimator() with your desired parameters and call fit() on the estimator object. See the following code:
To automatically scale the RL training to several workers, you can adjust the rl.training.config.num_cpus and rl.training.config.num_gpus parameters. You must reserve 1 CPU (the 1 in num_cpus - 1) to act as the driver. For example, to configure a training job with multiple workers in a single Amazon SageMaker instance, set 'rl.training.config.num_cpus' = 3 and 'num_gpus' = 0 and select a training instance type with at least 4 CPUs (for example ml.c5.xlarge).
Distributed training of your snake with multiple instances
You can perform your distributed RL experiment with multiple instances of the same type (homogeneous scaling). You need to set train_instance_count to the number of instances to train on. Similar to the single instance use case, you need to configure the number of workers based on the total resources available. You can calculate this by the train_instance_count multiplied by the number of cores per instance subtracted by 1. Again, subtracting by 1 accounts for the driver. See the following code:
When you increase the number of rollout workers, policy updates can often become the bottleneck. To address this, you can use an instance with one or more GPUs for policy updates and multiple CPU instances for rollouts (heterogeneous scaling).
Specifically, you can spin up two Amazon SageMaker jobs, and SageMaker RL takes care of communication between the two jobs. This post uses Primary instance to refer to one or more GPU instances and Secondary instance to refer to the cluster of CPU instances. Before defining the estimators, you must define several parameters. See the following code:
You can define the primary and secondary RLEstimator with the following code:
Experimentation
In this section, snakes are trained both with the previous RL implementation and the new implementation using built-in RL algorithms on Amazon SageMaker. The previous RL implementation is based on MXNet and runs on a single instance with a single core. The Amazon SageMaker RL experiments consist of the following:
- A single instance with a single core
- A single instance with multiple cores
- Multiple identical instances with multiple cores
- Multiple heterogeneous instances with multiple cores
DQN was used for the single instance experiments to keep experimentation conditions between the two implementations similar. In the experiments with multi-instances, we kept the training batch size the same and enabled asynchronous policy update to better utilize the experiences collected. We further improved data efficiency by using the distributed prioritized experiences replay and the modified algorithm is known as APEX [2]. This post runs all experiments for 210 minutes and uses identical a reward function, environment representation, and hyperparameters.
In terms of training, the MXNet, single instance, and homogeneous scaling jobs run using the same instance type (ml.m5.xlarge). The primary instance type for the heterogeneous scaling job is a GPU instance (ml.p2.xlarge) and the secondary instances are ml.m5.xlarge. The following graph shows the performance evaluated in terms of the mean episode rewards.
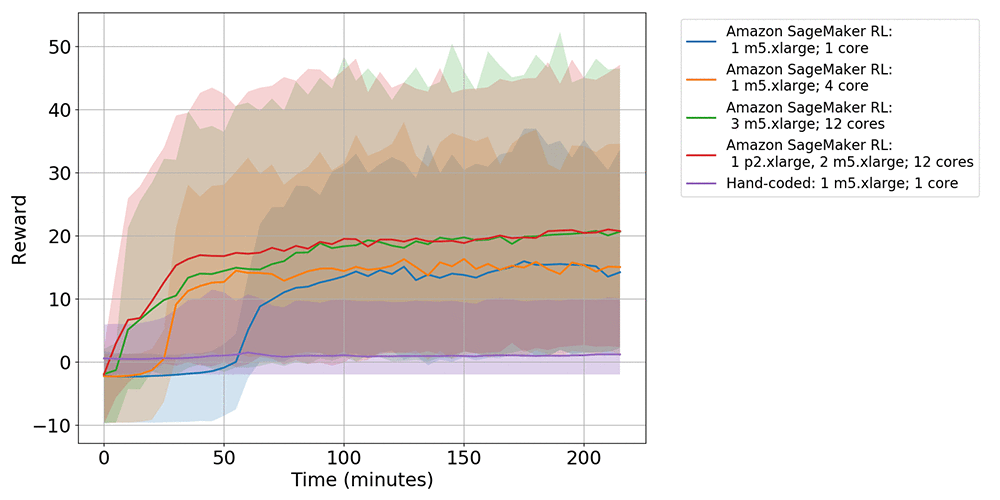
The following graph shows the performance evaluated in terms of the mean episode length (how long the snakes survived for).

The previous policy was trained for over 20 hours, which is reflected in both graphs, in which the rewards and episode length have only slightly increased after 3 hours of training (hand-coded: 1 m5.xlarge; 1 core). The graphs show an increase of at least 7.5 times in reward obtained and twice as long in episode length between the previous and current policies. When you compare between the single instance jobs (Amazon SageMaker RL: 1 m5.xlarge, 1 core vs. Amazon SageMaker RL: 1 m5.xlarge, and 4 cores), the single instance with multiple cores outperforms the single core job. This is further emphasized when you use multiple instances, where heterogeneous scaling (Amazon SageMaker RL: 1 p2.xlarge, 2 m5.xlarge;12 cores) outperforms both single instance and homogeneous scaling jobs (Amazon SageMaker RL: 3 m5.xlarge; 12 cores). The heterogeneous scaling job achieved an increase of at least 10 times longer in reward and an increase in episode length of 3 times longer compared to the previous implementation.
Conclusion
This post shows you how to use the SageMaker Battlesnake Starter Pack to train a snake with distributed RL. Snakes built using Amazon SageMaker achieved a reward of 10 times greater compared to the snakes built without this option when trained over the same amount of time with the distributed training capabilities for RL in Amazon SageMaker.
Try out distributed training with Amazon SageMaker RL and see if you can climb up the ranks in the Battlesnake global arena. For more information, see the following video Amazon SageMaker Battlesnake Workshop with Xavier Raffin from AWS (April 20th) on Twitch as a part of the Battlesnake: Stay Home and Code event to raise money for Food Banks Canada.
References
[1] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[2] Horgan, D., Quan, J., Budden, D., Barth-Maron, G., Hessel, M., Van Hasselt, H., & Silver, D. (2018). Distributed prioritized experience replay. arXiv preprint arXiv:1803.00933.
[3] Liang, E., Liaw, R., Moritz, P., Nishihara, R., Fox, R., Goldberg, K., … & Stoica, I. (2017). RLlib: Abstractions for distributed reinforcement learning. arXiv preprint arXiv:1712.09381.
About the Authors
 Jonathan Chung is an Applied scientist in AWS. He works on applying deep learning to various applications including games and document analysis. He enjoys cooking and visiting historical cities around the world.
Jonathan Chung is an Applied scientist in AWS. He works on applying deep learning to various applications including games and document analysis. He enjoys cooking and visiting historical cities around the world.
 Anna Luo is an Applied Scientist in AWS. She works on utilizing reinforcement learning techniques for different domains including supply chain and recommender system. Her current personal goal is to master snowboarding.
Anna Luo is an Applied Scientist in AWS. She works on utilizing reinforcement learning techniques for different domains including supply chain and recommender system. Her current personal goal is to master snowboarding.
 Scott Perry is a Specialist Solutions Architect with AWS. Based in Calgary, Alberta, he helps customers apply AI/ML-based solutions to meaningful business problems. His interests include Deep Reinforcement Learning and Genomics. Outside of work, he enjoys playing electric guitar and spending time in the mountains.
Scott Perry is a Specialist Solutions Architect with AWS. Based in Calgary, Alberta, he helps customers apply AI/ML-based solutions to meaningful business problems. His interests include Deep Reinforcement Learning and Genomics. Outside of work, he enjoys playing electric guitar and spending time in the mountains.
 Bharathan Balaji is a Research Scientist in AWS and his research interests lie in reinforcement learning systems and applications. He contributed to the launch of Amazon SageMaker RL and AWS DeepRacer. He likes to play badminton, cricket and board games during his spare time.
Bharathan Balaji is a Research Scientist in AWS and his research interests lie in reinforcement learning systems and applications. He contributed to the launch of Amazon SageMaker RL and AWS DeepRacer. He likes to play badminton, cricket and board games during his spare time.
 Xavier Raffin is a Solutions Architect at AWS where he helps customers to transform their businesses and build industry leading cloud solutions. Xavier curiosity, pushed him to apply technology onto many domains: Public Transportation, Web Mapping, IoT, Aeronautics and Space. He contributed to several OpenSource and Opendata projects: OpenStreetMap, Navitia, Transport APIs.
Xavier Raffin is a Solutions Architect at AWS where he helps customers to transform their businesses and build industry leading cloud solutions. Xavier curiosity, pushed him to apply technology onto many domains: Public Transportation, Web Mapping, IoT, Aeronautics and Space. He contributed to several OpenSource and Opendata projects: OpenStreetMap, Navitia, Transport APIs.
 Vishaal Kapoor is a Senior Software Development Manager with AWS AI. He loves all things AI and works on building deep learning solutions using SageMaker. In his spare time, he mountain bikes, snowboards, and spends time with his family.
Vishaal Kapoor is a Senior Software Development Manager with AWS AI. He loves all things AI and works on building deep learning solutions using SageMaker. In his spare time, he mountain bikes, snowboards, and spends time with his family.