Microsoft Workloads on AWS
How LogMeIn migrated a billion records online from Oracle to Amazon Aurora and achieved sub-millisecond response time
This post was written by Elliot Barlas, Principal Engineer at LogMeIn
Large-scale database migrations of critical customer records are complex and often avoided. However, these migrations are necessary to advance the architecture of a software system. At LogMeIn, we migrated over a billion such records from on-premises Oracle RAC to Amazon Aurora with MySQL compatibility.
The customer identity database, comprised of users, accounts, and dozens of other entities, was the subject of the migration. Access to this data is on nearly every critical path for LogMeIn remote collaboration products, such as GoToMeeting, GoToWebinar, and GoToConnect. Consequently, the migration occurred while the web application that accesses the database continued serving tens of thousands of requests per second.
In this blog post, I outline why LogMeIn migrated, the tools we used, how we transitioned the workload, and the outcomes the company achieved.
Motivation to migrate
For many years, our customer identity system resided on premises and served us well. We made use of the distributed, high availability properties of Oracle RAC, including physical standby servers deployed across multiple data centers. Given the high read-to-write ratio, the vast majority of traffic was served by physical standbys. We deployed web application software on bare metal hardware and configured load balancer policies on network appliances in our data centers. In short, it was a traditional and static deployment architecture.

Oracle architecture
In recent years, we departed from that model. Web applications are now packaged as Docker images and deployed in the cloud using a range of AWS offerings, including AWS CloudFormation, Amazon Elastic Compute Cloud (EC2), Elastic Load Balancing, and Amazon Elastic Container Service (Amazon ECS). While much of our infrastructure moved to AWS, the customer identity system remained on premises, tethered to the specialized Oracle RAC database. While other applications enjoyed benefits such as automated deployments, recovery, and scaling, the changes to the identity system moved at a snail’s pace.
In 2019, we began seriously exploring how to lift the customer identity system and move it to AWS. This was a tall order, as the system spanned dozens of servers and multiple data centers. We began an exploration period to gauge the feasibility of migrating.
Testing feasibility with AWS tools
Amazon Aurora was a clear choice for the Oracle RAC replacement. The cost, performance, and availability features of Amazon Aurora were compelling. Additionally, Amazon Aurora Global Database read replicas offered a suitable alternative to Oracle RAC physical standbys. The ability to scale up within a region or into a new region with a few clicks or API calls was particularly important, given our desire to expand the footprint of the identity system.
The increased demand for remote collaboration tools in recent times has only strengthened that desire. We decided to focus our attention on Aurora with MySQL compatibility, given our organization’s expertise with MySQL.
We first had to address three major feasibility questions: compatibility, replication, and integrity.
Measuring compatibility with Aurora
Could the Oracle schema that evolved for over 10 years be mapped to MySQL? We used the AWS Schema Conversion Tool to evaluate the Oracle schema and produce a report of compatibility issues with MySQL. The report surfaced several issues that required attention. The most pressing issue was the lack of a suitable equivalent for the Oracle timestamp with time zone data type. Another issue was the lack of support for functional indexes in MySQL. We manually addressed compatibility issues with minor adjustments to the schema using standard MySQL features. In addition to the compatibility report, we referenced Amazon SCT-generated schema creation SQL as we reconstituted the schema.
Ensuring efficient Oracle to Aurora replication
Could we replicate records in near-real-time from Oracle to Aurora while the system was running? Online replication was vital, given the nature of the customer identity system. We did not have the luxury of a maintenance window shutdown. Replication in near real-time would allow us to serve data from both systems simultaneously and systematically divert an increasing amount of read traffic to Aurora before the final write cutover. We used AWS Database Migration Service to achieve this. DMS provided us the ability to copy a complete database from source to target with built-in support for many engines and column data types. Early experiments yielded positive results. In short order, we migrated experimental Oracle databases to Aurora using DMS. We arrived at a suitable LogMiner DMS configuration that produced end-to-end replication from Oracle on premises to Aurora in two to three seconds.
Testing integrity of data
Could we be certain about the integrity of data replicated by DMS? With an abundance of caution, we developed an in-house tool to independently verify that data was correctly copied and surface validation metrics within our monitoring and analytics platform. It scanned data from a source Oracle database, loaded the corresponding records from Aurora, and performed a column-wise comparison for each record. Scanning used range-based queries on primary keys to pull fixed-sized batches of rows in small transactions. The tool was packaged such that we could run it on demand at any time. Repeated successful results gave us a high degree of confidence in DMS.
With the feasibility questions addressed, we moved forward by modifying the web application that accesses the database. However, we encountered the following SQL compatibility issues while adapting the web application. The semantic meaning of NULL in a composite unique constraint differs between Oracle and MySQL. Hierarchical connect-by queries aren’t supported in MySQL. Default transaction isolation levels differ. The rownum psuedocolumn doesn’t exist in MySQL. The set of reserved words differs. The set of aggregate functions differs. Index hint syntax differs. Though the application compatibility issues were numerous, we were able to address them with modest code changes and SQL updates.
Transitioning the workload
Overall, availability was the most important characteristic of the migration. We were committed to a migration with no read downtime, no increase in request processing time, no reduction in throughput capacity, and write downtime under one minute during the final cutover. Furthermore, we sought an approach that allowed for immediate rollback, or restoration, of the Oracle system at any time before the final write cutover. We met these goals by devising a simple weighted routing approach. This allowed us to configure the percent of read traffic forwarded to Aurora and the amount of traffic remaining locally on the Oracle system.
A global table in Amazon DynamoDB stored the routing policy, which the on-premises system queried every few seconds. For each read request, the on-premises system performed a weighted random selection according to the policy. This helped determine if the request should remain on premises or route to Aurora in a nearby AWS Region. We could see the effect of an adjustment to the policy in DynamoDB within seconds. The background replication using DMS ensured that all systems served the same data with a difference of a few seconds.
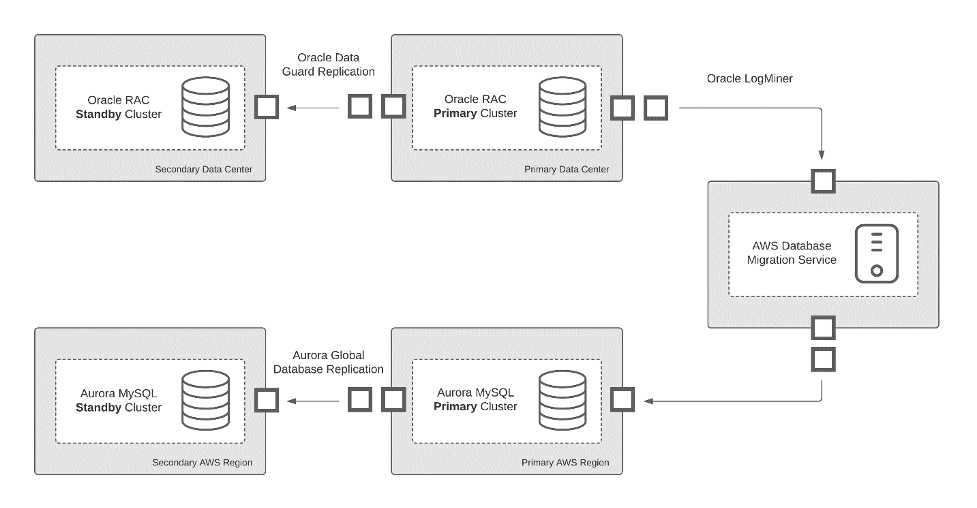
Data replication path from Oracle to Aurora

Transitioning workload from Oracle to Aurora
After extensive testing in a staging environment, we deployed this setup in production and began by routing a small fraction of requests. This allowed us to make observations in a safe and controlled manner, while retaining the ability to roll back through a routing policy change. Over the course of several weeks, we gradually increased the percent of routed requests while checking key performance metrics along the way. We used the full spectrum of Aurora monitoring tools, including CloudWatch metrics, Enhanced Monitoring, and Performance Insights. We attached alarms to CPU utilization, replication lag, and select-query latency metrics. The traffic shaping effort proceeded smoothly, eventually reaching 100% read request routing.
We concluded the migration with the write cutover. After executing the write cutover, all read and write requests routed to the Aurora MySQL system. In the weeks that followed, we decommissioned the Oracle database and configured client applications to connect directly to the Aurora MySQL system in AWS to avoid the routing step.
Outcome
For the last several months, we’ve been enjoying the fruits of AWS. Performance has been stellar, given our choice of smaller database instance classes for Aurora MySQL instances. The Aurora database processes hundreds of thousands of queries per second with sub-millisecond response time. Plus, automated application deployments are a breeze with Amazon Elastic Container Service (Amazon ECS). We also adjusted our Aurora instance types with no impact. We use the point-in-time snapshot capability weekly to form testing datasets and began expanding the footprint of the customer identity system into additional AWS Regions. Cross-region replication lag is a fraction of a second. Most importantly, the entire customer identity system infrastructure is now programmable and automatable. We’re glad that we decided to move forward with a cloud-first strategy and hope this blog post helps other folks in their journey.
 Average select query response time over a 24-hour period
Average select query response time over a 24-hour period
Aurora architecture
AWS can help you assess how your company can get the most out of cloud. Join the millions of AWS customers that trust us to migrate and modernize their most important applications in the cloud. To learn more on modernizing legacy systems like Oracle and SQL Server, visit AWS Database Freedom For ISVs. Contact us to start your migration journey today.